Ladda ner presentationen
Presentation laddar. Vänta.

1
Kvadratsummeuppdelning/Variansanalys
Låt dvs. ”råvariationen” bland y-värdena får ytterligare en beteckning (Square Sum of Total variation) Tidigare har vi sett att SST inte duger som bas för en skattning av 2
 Tidigare har vi sett att SST inte duger som bas för en skattning av 2.")
2
Man kan visa att dvs. SST kan delas upp i två kvadratsummor varav den ena är SSE. Den andra, betecknad SSR, innehåller den del av den totala variationen som inte är slump utan beror på regressionssambandet mellan y och x. SSR står för Square Sum of Regression och det svenska namnet är regressionskvadratsumma. I exemplet från föreläsning 1 (pizzarestaurangerna) är SST= och SSE= (se föregående fö-underlag) SSR=15730 – 1530 = 14200
 är. SST= och SSE=1530 (se föregående fö-underlag) SSR=15730 – 1530 =")
3
Förklaringsgrad Den del av SST som utgörs av SSR , dvs. den del av den totala variationen som utgörs av regressionssambandet kallas förklaringsgrad och betecknas r2 , dvs. Ju högre förklaringsgrad, desto bättre lyckas vår skattade modell förklara variationen i data Modellen kan anses vara bra. I exemplet med pizzarestaurangerna blir dvs % av den totala variationen i y kan sägas förklaras av sambandet med x. Notera! I den enkla regressionsmodellen är förklaringsgraden = (korrelationskoefficienten)2 Däremot behöver inte r = kvadratroten ur r2. Det är den bara om sambandet är positivt! r är som tidigare också korrelationskoefficienten
2. Däremot behöver inte r = kvadratroten ur r2. Det är den bara om sambandet är positivt! r är som tidigare också korrelationskoefficienten.")
4
F-test: Kvadratsummeuppdelningen SST=SSE+SSR kan användas till mer än bra förklaringsgrad. Tidigare har vi tagit upp begreppet frihetsgrader har n1 frihetsgrader ty om n1 av termerna i summan är kända så kan man räkna ut den n:e. Motsvarande argument SSE har n2 frihetsgrader I kvadratsummeuppdelningen SST=SSE+SSR gäller att antalet frihetsgrader till vänster om likhetstecknet skall vara samma som till höger SSR har (n1) (n2) = 1 frihetsgrad
 (n2) = 1 frihetsgrad.")
5
Vi har tidigare definierat
MSE=SSE/(n2) MSE är en medelkvadratsumma och erhålls alltså genom att dividera SSE med dess frihetsgrader Motsvarande definierar vi då MSR=SSR/1 (= SSR ) Betrakta åter hypotesprövningen H0: 1 =0 Ha: 1 0 Om H0 är sann kan man visa att kvoten MSR/MSE får en regelbunden sannolikhetsfördelning över alla tänkbara stickprov av data.
 MSE är en medelkvadratsumma och erhålls alltså genom att dividera SSE med dess frihetsgrader. Motsvarande definierar vi då. MSR=SSR/1 (= SSR ) Betrakta åter hypotesprövningen. H0: 1 =0. Ha: 1 0. Om H0 är sann kan man visa att kvoten MSR/MSE får en regelbunden sannolikhetsfördelning över alla tänkbara stickprov av data.")
6
Fördelningen brukar kallas F-fördelning och har ofta följande utseende:
Fördelningen kännetecknas av att den alltid är över positiva värden på x-axeln. (Just i vårt exempel med 1 frihetsgrad i SSR börjar den dock inte i 0)
")
7
Om nollhypotesen är sann skall vi alltså få ett värde på MSR/MSE som ligger väl i linje med denna fördelning. Om nollhypotesen inte är sann: Det finns ett regressionssamband mellan y och x Förklaringsgraden borde vara hyfsat hög vilket den blir om SSR utgör en stor del av SST (SST=SSE+SSR ) Kvoten MSR/MSE borde bli högre än vad den är om inget regressionssamband finns. Nollhypotesen bör förkastas om värdet hos MSR/MSE ligger ”långt ut” i den högra svansen av F-fördelningen
 Kvoten MSR/MSE borde bli högre än vad den är om inget. regressionssamband finns. Nollhypotesen bör förkastas om värdet hos MSR/MSE ligger. långt ut i den högra svansen av F-fördelningen.")
8
Man jämför alltså MSR/MSE med ett tabellvärde hämtat ur F-förd.
F-fördelningen bestäms av frihetsgraderna hos de två kvadratsummorna, i exemplet med pizzarestaurangerna blir de 1 resp. 10 – 2 = 8 F1,8 -fördelning Vi får MSR = 14200/1= och MSE= 1530/8=191.25 MSR/MSE=14200/ 72.25

9
72.25 > 5.32 H0 förkastas på 5% nivå.
Statistical table of F distribution, alpha = 0.05 Kritisk gräns blir 5.32 72.25 > 5.32 H0 förkastas på 5% nivå.

10
Multipel regressionsanalys
Den generella metoden i vilken Enkel linjär regression är ett specialfall Syften: Att förklara variationen i en intressant storhet med hjälp av en eller flera bakgrundsvariabler Att med information om bakgrundsvariablernas värden göra prognoser för utfallet av den intressanta storheten Syftena drar ibland åt olika håll: Ju fler bakgrundvariabler som inkluderas desto bättre förklaring erhålls (!!) Ju fler bakgrundsvariabler som används desto sämre prognoser erhålls (!!) Studier av de enskilda variablerna krävs ur såväl matematisk/datamässig synvinkel som ur tillämpningsområdets synvinkel
 Ju fler bakgrundsvariabler som används desto sämre prognoser erhålls (!!) Studier av de enskilda variablerna krävs ur såväl matematisk/datamässig synvinkel som ur tillämpningsområdets synvinkel.")
11
Den generella modellen:
Den intressanta storheten betecknas y . y antas innehålla slumpmässig variation Ur statistisk synvinkel får vi att göra med Antalet bakgrundsvariabler antas vara k stycken och betecknas x1, x2,…, xk För att få en någorlunda enkel beskrivning antar vi att värdena hos alla bakgrundsvariabler är givna (dvs. utan slumpmässig variation) Bakgrundsvariablerna antas förklara E(y ) enligt en linjär modell:
 Bakgrundsvariablerna antas förklara E(y ) enligt en linjär modell:")
12
Hur kommer då Var ( y ) in i bilden?
Modellen för y (alltså inte E( y )) antas vara: där är en slumpvariabel som varierar runt väntevärdet 0 med konstant varians 2 Observera alltså att denna varians är den varians som också y har. En mer detaljerad modell som beskriver storheten punkt för punkt är följande: Vi antar att vi har observationer på y och på varje bakgrundsvariabel i n punkter och numrerar dessa 1, 2, … , n. Vi utnyttjar då ett index eller subscript som betecknas i :
) antas vara: där är en slumpvariabel som varierar runt väntevärdet 0 med konstant varians 2. Observera alltså att denna varians är den varians som också y har. En mer detaljerad modell som beskriver storheten punkt för punkt är följande: Vi antar att vi har observationer på y och på varje bakgrundsvariabel i n punkter och numrerar dessa 1, 2, … , n. Vi utnyttjar då ett index eller subscript som betecknas i :")
13
Litet mer om själva : Varje i antas ha väntevärde 0 Varje i antas ha konstant varians 2 Varje i antas vara normalfördelad N(0, ) 1 , 2 ,…, n antas vara oberoende slumpvariabler Antagande 1 måste i princip alltid vara uppfyllt Om antagande 2 ej är uppfyllt krävs transformationer av data (se senare) Om antagande 3 ej är uppfyllt måste alternativa testmetoder (och konfidensintervall) konstrueras. Detta görs ej i denna kurs. Om antagande 4 ej är uppfyllt har vi ofta en situation med tidsberoende (se tidsserieanalysdelen)
 Om antagande 3 ej är uppfyllt måste alternativa testmetoder (och konfidensintervall) konstrueras. Detta görs ej i denna kurs. Om antagande 4 ej är uppfyllt har vi ofta en situation med tidsberoende (se tidsserieanalysdelen)")
14
Följande datamaterial innehåller uppgifter om 150 slumpmässigt valda fastigheter i USA
Datamaterialet ingår bland exempeldatamängderna i Minitab och har följande beskrivning: Column Name Count Description Modell Översättning C1 Price 150 Price y pris C2 Area 150 Area in square feet x1 bostadsyta C3 Acres 150 Acres x2 tomtyta C4 Rooms 150 Number of rooms x3 antal rum C5 Baths 150 Number of baths x4 antal badrum Källa: Minitab 15\English\Sample Data\Student9\HOMES.MTW

15
Price (y) Area (x1) Acres (x2) Rooms (x3) Baths (x4)
, ,0 , ,5 , ,0 , ,0 , ,5 , ,5 , ,5 , ,0

16
Pris mot bostadsyta Pris mot Tomtyta

17
Pris mot bostadsyta Pris mot tomtyta

18
Bostadsyta och Antal rum verkar vara två bakgrundsvariabler som förklarar y bra.
Kan dessa kombineras i en modell?

19
Modell 1: Modellen anpassas på motsvarande sätt som vid enkel linjär regression, dvs vi minimerar med avseende på b0 , b1 och b3 . De därvid erhållna värdena på b0 , b1 och b3 utgör Minsta Kvadrat-skattningarna av parametrarna 0 , 1 och 3 Här går det dock inte att få några generella formler utan värdena räknas fram (med dator) i varje enskilt exempel.
 i varje enskilt exempel.")
20
Den anpassade modellen skrivs
Vi har även här kvadratsummeuppdelningen SST = SSE + SSR , dvs och en skattning av 2 erhålls som Observera att vi här dividerar med n (antal x-variabler) 1 . I den enkla linjära regression dividerade vi med n 2 och där var ju antal x-variabler = 1
 1 . I den enkla linjära regression dividerade vi med n 2 och där var ju antal x-variabler = 1.")
21
Alternativt ”menyvägen” StatRegressionRegression…
Analys av modellen i Minitab: MTB > regress c1 2 c2 c4 Alternativt ”menyvägen” StatRegressionRegression… x1 y x3 Anger att två x-variabler skall användas ”Response” är alltså y-variabeln. Kallas också responsvariabel på svenska eller ibland beroende variabel. ”Predictors” är bakgrundsvariablerna. Ett vanligare namn är förklaringsvariabler eller oberoende variabler. Namnen prediktorer resp. x-variabler förekommer också

22
Regression Analysis: Price versus Area, Rooms
The regression equation is Price = Area Rooms Predictor Coef SE Coef T P Constant Area Rooms S = R-Sq = 48.6% R-Sq(adj) = 47.9% Analysis of Variance Source DF SS MS F P Regression E Residual Error E Total E+11
 = 47.9% Analysis of Variance. Source DF SS MS F P. Regression E Residual Error E Total E+11.")
23
Source DF Seq SS Area E+11 Rooms Unusual Observations Obs Area Price Fit SE Fit Residual St Resid X X R RX R R RX X R R R X R R denotes an observation with a large standardized residual X denotes an observation whose X value gives it large influence.

24
Vad är egentligen ”SE Coef” ?
Predictor Coef SE Coef T P Constant Area Rooms b0=64221, b1=49.673, b3= 141 Vad är egentligen ”SE Coef” ? Varje bj ( j = 0, 1, 3) är att se som utfallet av en slumpvariabel, ty för ett nytt datamaterial på samma variabler skulle en ny regressionsanalys ge andra värden. ”SE” står för Standard Error. Den svenska termen är medelfel och det står för den skattade standardavvikelsen hos variabeln bj . Beteckningen är ofta I enkel linjär regression finns generella formler för dessa standardavvikelser, t ex men i multipel linjär regression finns inga sådana enkla formler.
 är att se som utfallet av en slumpvariabel, ty för ett nytt datamaterial på samma variabler skulle en ny regressionsanalys ge andra värden. SE står för Standard Error. Den svenska termen är medelfel och det står för den skattade standardavvikelsen hos variabeln bj . Beteckningen är ofta. I enkel linjär regression finns generella formler för dessa standardavvikelser, t ex. men i multipel linjär regression finns inga sådana enkla formler.")
25
T ex får vi ett 95% konfidensintervall för 1 som
För den intresserade: Formler kan ställas upp med hjälp av matrisalgebra, men då krävs att man har läst en matematikkurs om sådant. Vi litar istället på vad datorutskrifterna ger och i vårt exempel ser vi att Med hjälp av bj och kan vi nu bilda konfidensintervall för j och/eller genomföra t-test av enskilda värden hos j . T ex får vi ett 95% konfidensintervall för 1 som Notera att vi här har nk1 frihetsgrader som i vårt fall blir 150 2 1=147 Detta frihetsgradstal finns ej i AJÅ:s tabell, men kan ur Minitab fås till (Observera dock närheten till 1.96 ) Predictor Coef SE Coef T P Constant Area Rooms
 Predictor Coef SE Coef T P. Constant Area Rooms")
26
Vi får då konfidensintervallet
I konfidensintervallet kan vi t ex se att 1 inte skulle kunna vara 0, då intervallet ej omfattar detta värde. Alternativt kan detta göras genom formell hypotesprövning (på 5% nivå). Vi ställer då upp Testvariabel (testfunktion, teststorhet) blir här som skall jämföras med (eftersom testet är dubbelsidigt) Eftersom t > förkastas H0 Notera nu att värdet 6.62 faktiskt redan finns uträknat i utskriften under kolumnen ”T” Predictor Coef SE Coef T P Constant Area Rooms
. Vi ställer då upp. Testvariabel (testfunktion, teststorhet) blir här. som skall jämföras med (eftersom testet är dubbelsidigt) Eftersom t > förkastas H0. Notera nu att värdet 6.62 faktiskt redan finns uträknat i utskriften under kolumnen T Predictor Coef SE Coef T P. Constant Area Rooms")
27
Vad säger nu kolumnen ”P”?
I denna kolumn redovisas det s k P-värdet för motsvarande t-test. P-värdet beräknas som sannolikheten att testvariabeln blir så stor som den är (eller större) under förutsättning att H0 är sann. I vårt fall skulle värdet beräknas som Observera alltså att vi räknar med såväl stora positiva som stora negativa värden. Detta beror på att testet i detta fall är dubbelsidigt. Beräkningen kan inte göras enkelt, p g a att det är just t-fördelningen som användas, men här som i många andra fall är det praktiskt att förlita sig på datorutskriften. Predictor Coef SE Coef T P Constant Area Rooms
 under förutsättning att H0 är sann. I vårt fall skulle värdet beräknas som. Observera alltså att vi räknar med såväl stora positiva som stora negativa värden. Detta beror på att testet i detta fall är dubbelsidigt. Beräkningen kan inte göras enkelt, p g a att det är just t-fördelningen som användas, men här som i många andra fall är det praktiskt att förlita sig på datorutskriften. Predictor Coef SE Coef T P. Constant Area Rooms")
28
I Minitab kan dock P-värdet också beräkna med kommandon:
MTB > cdf k1; SUBC> t 147. MTB > print k1 beräknar och ger resultatet Resultatet blir förstås inte exakt 0, men så pass litet att Minitab:s format inte skriver ut de sista decimalerna. Eftersom t-fördelningen är symmetrisk runt 0 kan detta värde multipliceras med 2 för att få P-värdet. Resultatet blir förstås också det mycket litet och det är orsaken till att vi i kolumnen ”P” avläser värdet När det står så kan vi alltså räkna med att P-värdet är < (ty då avrundas det till 0.000) Samma yta till vänster om strecket här… …som till höger om strecket här
 Samma yta till vänster om strecket här… …som till höger om strecket här.")
29
Vi har alltså ingen anledning att förkasta den nollhypotesen.
Vi ser nu att så fort P-värdet blir lägre än signifikansnivån (dvs. ) så kan H0 förkastas. Detta är en enkel och snabb metod att utifrån en datorutskrift avgöra om en nollhypotes skall förkastas eller ej. T ex ser vi att P-värdet för dubbelsidigt test av nollhypotesen H0:3=0 är så pass högt som Vi har alltså ingen anledning att förkasta den nollhypotesen. Detta bekräftas genom att värdet i kolumnen ”T”, dvs testvariabelns värde är 0.05 och detta faller ju inom intervallet (1.9762, ) som är tabellvärdena det skall jämföras med. Observera! Samma tabellvärde för alla t-test på 5% nivå i just denna analys Predictor Coef SE Coef T P Constant Area Rooms
 så kan H0 förkastas. Detta är en enkel och snabb metod att utifrån en datorutskrift avgöra om en nollhypotes skall förkastas eller ej. T ex ser vi att P-värdet för dubbelsidigt test av nollhypotesen H0:3=0 är så pass högt som Vi har alltså ingen anledning att förkasta den nollhypotesen. Detta bekräftas genom att värdet i kolumnen T , dvs testvariabelns värde är 0.05 och detta faller ju inom intervallet (1.9762, ) som är tabellvärdena det skall jämföras med. Observera! Samma tabellvärde för alla t-test på 5% nivå i just denna analys. Predictor Coef SE Coef T P. Constant Area Rooms")
30
(SSE tas från kolumnen ”SS”, ”E+11” betyder ”·1011 ”)
Vad ger oss nu resten av utskriften? S = R-Sq = 48.6% R-Sq(adj) = 47.9% Analysis of Variance Source DF SS MS F P Regression E Residual Error E Total E+11 s = är alltså skattningen av . Den är förstås roten ur skattningen av 2 som erhålls som (SSE tas från kolumnen ”SS”, ”E+11” betyder ”·1011 ”) Detta värde finns dock uträknat med större noggrannhet under kolumnen ”MS” och är förstås MSE=
 = 47.9% Analysis of Variance. Source DF SS MS F P. Regression E Residual Error E Total E+11. s = är alltså skattningen av . Den är förstås roten ur skattningen av 2 som erhålls som. (SSE tas från kolumnen SS , E+11 betyder ·1011 ) Detta värde finns dock uträknat med större noggrannhet under kolumnen MS och är förstås MSE=")
31
S = R-Sq = 48.6% R-Sq(adj) = 47.9% Analysis of Variance Source DF SS MS F P Regression E Residual Error E Total E+11 Roten ur blir 30047 ”R-sq” står för R2 och är förklaringsgraden hos den skattade modellen. Den beräknas på samma sätt som vid enkel linjär regression men har en annan symbol här. Alltså Vad står då R för? Den kallas multipel korrelationskoefficient och uttrycker den ”samtidiga” korrelationen med y å ena sidan och x1 och x3 å den andra . Tolkningen kan kännas svår och tas inte upp i denna kurs.

32
S = R-Sq = 48.6% R-Sq(adj) = 47.9% Analysis of Variance Source DF SS MS F P Regression E Residual Error E Total E+11 ”R-sq(adj)” står för justerad förklaringsgrad och tas upp senare i kursen. Kolumnen ”F” ger ett värde som kan misstänkas vara värdet hos en testvariabel precis som i enkel linjär regression. Detta är sant och testvariabeln beräknas även här som MSR/MSE. Skillnaden är att hypotesparet i detta fall är Om H0 inte förkastas innebär detta att ingen regression finns mellan y och dessa x-variabler.
 står för justerad förklaringsgrad och tas upp senare i kursen. Kolumnen F ger ett värde som kan misstänkas vara värdet hos en testvariabel precis som i enkel linjär regression. Detta är sant och testvariabeln beräknas även här som MSR/MSE. Skillnaden är att hypotesparet i detta fall är. Om H0 inte förkastas innebär detta att ingen regression finns mellan y och dessa x-variabler.")
33
Frihetsgraderna kan avläsas i kolumnen ”DF” (Degrees of Freedom)
S = R-Sq = 48.6% R-Sq(adj) = 47.9% Analysis of Variance Source DF SS MS F P Regression E Residual Error E Total E+11 Vi kan även här använda P-värdet för att avgöra om testet är signifikant eller ej. Det mycket låga P-värde vi har ger då att nollhypotesen skall förkastas. Alternativt jämför vi testvariabelns värde (69.38) med ett tabellvärde ur en F-fördelning med frihetsgraderna 2 och 147 . Observera alltså att vi ökar till två frihetsgrader här jämfört med vid enkel linjär regression. Det beror på att det är två parametrar (1 och 3 ) som ingår i nollhypotesen. Frihetsgraderna kan avläsas i kolumnen ”DF” (Degrees of Freedom) Tabellvärdet för test på 5% nivå tas i detta fall fram med Minitab:s hjälp till och vi ser att är långt mycket större än detta värde.
 = 47.9% Analysis of Variance. Source DF SS MS F P. Regression E Residual Error E Total E+11. Vi kan även här använda P-värdet för att avgöra om testet är signifikant eller ej. Det mycket låga P-värde vi har ger då att nollhypotesen skall förkastas. Alternativt jämför vi testvariabelns värde (69.38) med ett tabellvärde ur en F-fördelning med frihetsgraderna 2 och Observera alltså att vi ökar till två frihetsgrader här jämfört med vid enkel linjär regression. Det beror på att det är två parametrar (1 och 3 ) som ingår i nollhypotesen. Frihetsgraderna kan avläsas i kolumnen DF (Degrees of Freedom) Tabellvärdet för test på 5% nivå tas i detta fall fram med Minitab:s hjälp till och vi ser att är långt mycket större än detta värde.")
34
Utskrift från annan programvara
I AJÅ (och på många andra ställen) kan man stöta på utskrift från det stora och välanvända programpaketet SAS. För vårt exempel skulle en SAS-utskrift kunna ha följande utseende: The REG Procedure Model: MODEL1 Dependent Variable: y Analysis of Variance Sum of Mean Source DF Squares Square F Value Pr > F Model E <.0001 Error E Corrected Total E11 Root MSE R-Square Dependent Mean Adj R-Sq Coeff Var
 kan man stöta på utskrift från det stora och välanvända programpaketet SAS. För vårt exempel skulle en SAS-utskrift kunna ha följande utseende: The REG Procedure. Model: MODEL1. Dependent Variable: y. Analysis of Variance. Sum of Mean. Source DF Squares Square F Value Pr > F. Model E < Error E Corrected Total E11. Root MSE R-Square Dependent Mean Adj R-Sq Coeff Var")
35
Parameter Estimates Parameter Standard Variable DF Estimate Error t Value Pr > |t| Intercept <.0001 x <.0001 x SAS ger litet mer i sin utskrift och i litet annan ordning, men det skall dock vara relativt enkelt att identifiera de komponenter vi just tagit ur Minitab-utskriften. Notera att SAS använder litet andra rubriker på sina kolumner, dock.

36
Fler analyser av vårt datamaterial
I enkel linjär regression visade vi hur man kan beräkna ett konfidensintervall för y|x0 , dvs. det förväntade eller genomsnittliga värdet hos y då x=x0 beräkna en prognos och ett prognosintervall för y i en ny punkt Dessa kan beräknas även i multipel regression, men inga enkla formler kan sättas upp (kräver också matrisalgebra). Principen är dock detsamma och vi kan här använda ”Distance value” som ingående term.
. Principen är dock detsamma och vi kan här använda Distance value som ingående term.")
37
Ett konfidensintervall för beräknas som
där och ”Distance value” tas i förekommande fall från datorutskrift Ett prognosintervall för y0 beräknas som

38
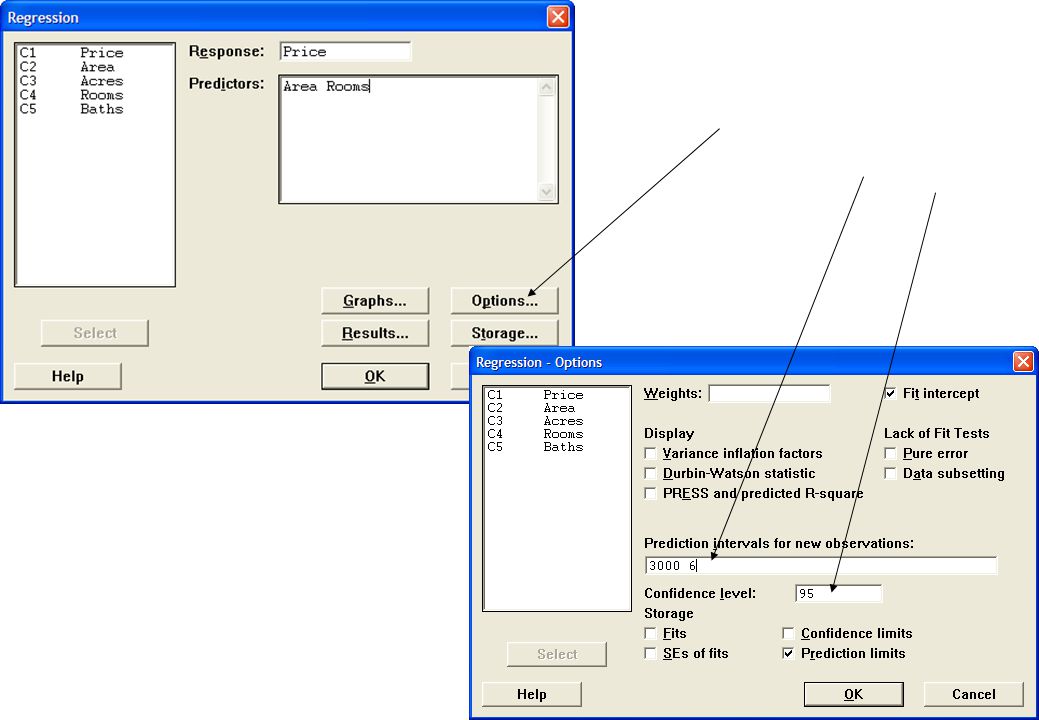
Vi begär dessa intervall (inklusive själva prognosen eller punktskattningen) vid Minitab-analysen.
Antag t ex att vi vill göra en prognos för priset på en fastighet när bostadsytan är 3000 ft2 och antal rum är 6, dvs x01 = 3000 och x03 = 6, samt ett 95% konfidensintervall för och ett 95% prognosintervall för y0 MTB > regress c1 2 c2 c4; SUBC> predict ; SUBC> confidence 95. Menyvägen ser det istället ut på följande sätt: StatRegressionRegression…

40
Regression Analysis: Price versus Area, Rooms
Samma utskrift som tidigare Predicted Values for New Observations New Obs Fit SE Fit % CI % PI ( , ) ( , ) XX X denotes a row with X values away from the center XX denotes a row with very extreme X values Values of Predictors for New Observations New Obs Area Rooms
 ( , ) XX. X denotes a row with X values away from the center. XX denotes a row with very extreme X values. Values of Predictors for New Observations. New Obs Area Rooms")
41
Vi vet ju att s = 30047 Hur kan vi nu komma åt ”Distance value”?
New Obs Fit SE Fit % CI % PI ( , ) ( , ) XX Vi vet ju att s =
 ( , ) XX. Vi vet ju att s = ")
42
Jämförelse med utskriften:
Värdet är ett mått på avståndet från den nya punkten till datamaterialets ”centrum”, men har i övrigt ingen särskild tolkning. Beskrivningen är en förenkling av en i övrigt ganska komplicerad matematisk beräkningsmetod. För att få det i utskriften beräknade prognosintervallet skulle vi nu kunna göra följande beräkning Jämförelse med utskriften: New Obs Fit SE Fit % CI % PI ( , ) ( , ) XX Skillnaden beror på avrundningsfel (”0.168” är egentligen …)
 ( , ) XX. Skillnaden beror på avrundningsfel ( är egentligen …)")
43
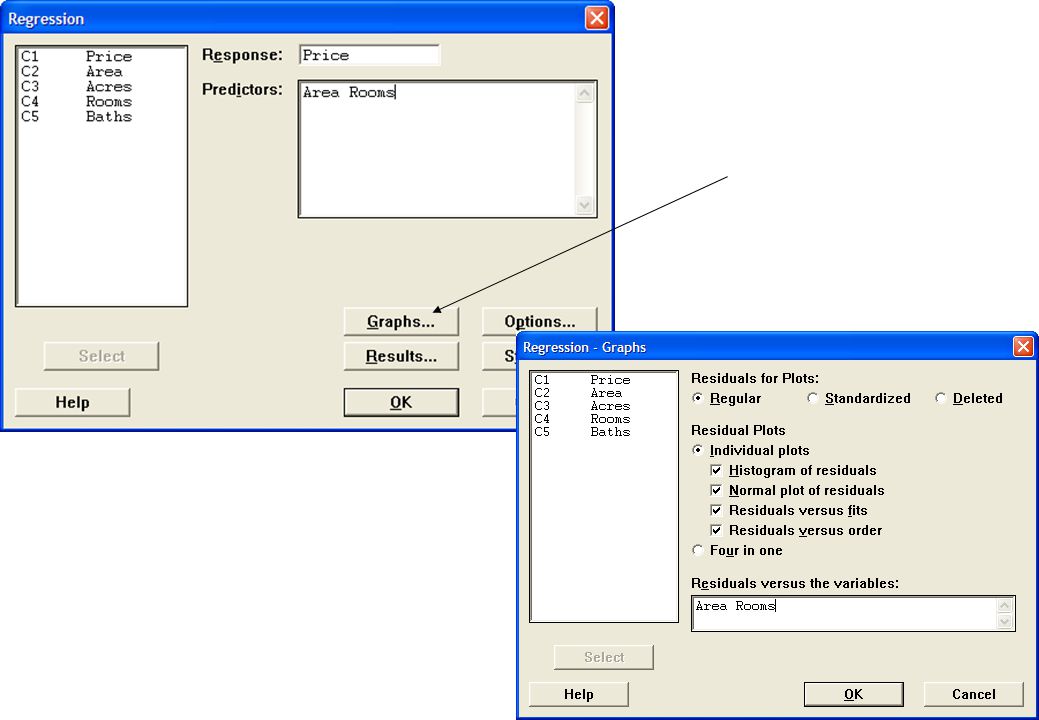
Residualanalys Residualanalys blir mer betydelsefull när det kommer till multipel regression. Bra residualer är till god hjälp i bedömningen av en anpassad modell utöver t-test och F-test. Residualdiagram kan begäras i datoranalysen som Histogram för att checka normalfördelningsantagandet Normalfördelningsdiagram för att checka normalfördelningsantagandet Plott mot anpassade värden ( ) för att checka om variansen är konstant Plott i observationsordning för att checka oberoendeantagandet Plott mot en eller flera av x-variablerna för att checka om sambandet mellan y och en x-variabel är rent linjärt eller ej
 för att checka om variansen är. konstant. Plott i observationsordning för att checka oberoendeantagandet. Plott mot en eller flera av x-variablerna för att checka om sambandet mellan y och en x-variabel är rent linjärt eller ej.")
45
(Diagrammen kommer vart och ett för sig men har samlats här)
")
46
x1 x3

47
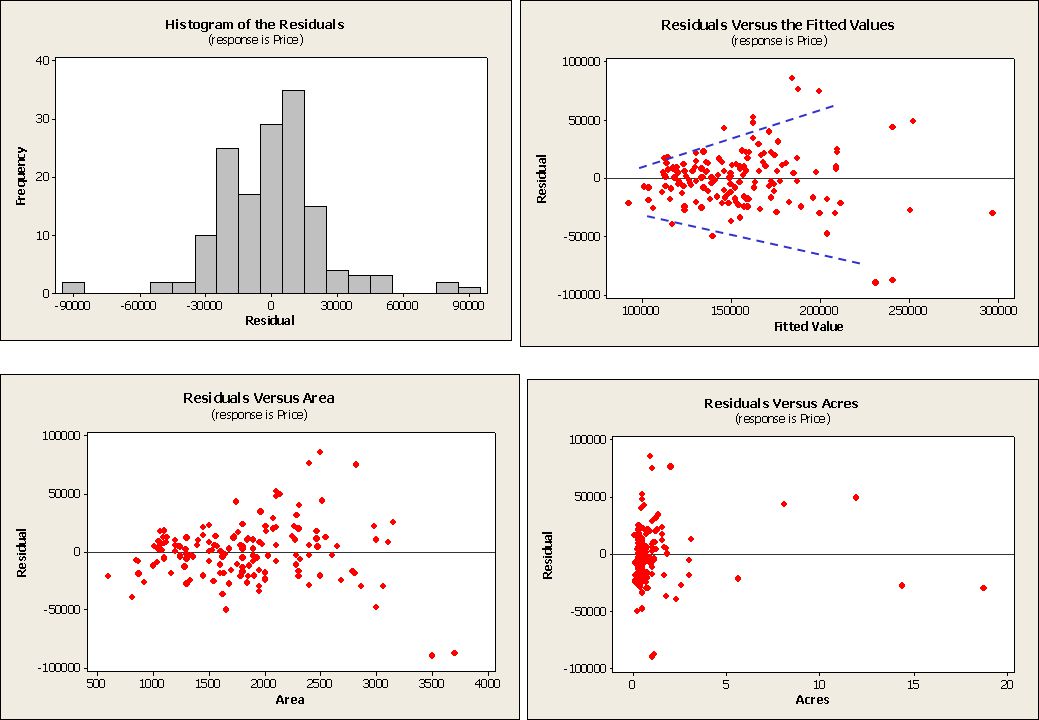
…och hur skall diagrammen studeras?
Punkterna skall ansluta bra till en rät linje åtminstone i mitten av diagrammet om residualerna skall anses vara normalfördelade. Inte så uppfyllt här Skall vara symmetriskt om residualerna skall anses vara normalfördelade Ev. högerskevt här

48
Punkterna skall utgöra ett jämnbrett band om variansen skall anses vara konstant.
Här ser vi antydan till ett strutmönster (inritad med blå streck) Punkterna skall inte ha någon successiv följsamhet om residualerna skall anses vara oberoende. Här ser vi ingen sådan följsamhet OK!
 Punkterna skall inte ha någon successiv följsamhet om residualerna skall anses vara oberoende. Här ser vi ingen sådan följsamhet OK!")
49
Punkterna skall inte uppvisa något mönster som antyder att ytterligare samband med resp. x-variabel finns kvar. Mönster: Krökning, rät linje etc. Svårt att se några mönster i just dessa två diagram

50
En mer begränsad residualplott:

51
Modell 2: y=β0 + β1·x1 + β2·x2 + ε
Vi jämför nu test och residualanalys för några andra modeller på samma datamaterial Modell 2: y=β0 + β1·x1 + β2·x2 + ε x1 = Bostadsyta x2 = Tomtyta The regression equation is Price = ,2 Area Acres Predictor Coef StDev T P Constant , ,000 Area , , , ,000 Acres , , , ,000 S = R-Sq = 65,7% R-Sq(adj) = 65,2% Analysis of Variance Source DF SS MS F P Regression ,69376E , ,000 Residual Error Total ,57989E+11 Bägge är signifikanta Minst en av x1 och x2 skall vara med Bättre R 2
 = 65,2% Analysis of Variance. Source DF SS MS F P. Regression 2 1,69376E ,49 0,000. Residual Error Total 149 2,57989E+11. Bägge är signifikanta. Minst en av x1 och x2 skall vara med. Bättre R 2.")
53
Modell 3: (Samtliga förklaringsvariabler med)
y=β0 + β1·x1 + β2·x2 + β3·x3 + β4·x4 + ε The regression equation is Price = ,9 Area Acres Rooms Baths Predictor Coef StDev T P Constant , ,000 Area , , , ,000 Acres , , , ,000 Rooms , ,724 Baths , ,001 S = R-Sq = 68,2% R-Sq(adj) = 67,4% Analysis of Variance Source DF SS MS F P Regression ,76060E , ,000 Residual Error Total ,57989E+11 Ej signifikant här precis som i Modell 1 Minst en av x-variablerna skall vara med
 = 67,4% Analysis of Variance. Source DF SS MS F P. Regression 4 1,76060E ,90 0,000. Residual Error Total 149 2,57989E+11. Ej signifikant här precis som i Modell 1. Minst en av x-variablerna skall vara med.")
55
Modell 4: y=β0 + β3·x3 + β5·x32 + ε I denna modell skapar vi alltså en ny förklaringsvariabel genom att kvadrera x3. Modellen kan alltså analyseras som en linjär modell även om en av förklaringsvariablerna ingår ”icke-linjärt”. Modelltypen kallas kvadratisk regression och är ett specialfall av polynomregression i vilken flera variabler med olika grader kan ingå, dvs. andragradstermer (kvadratiska), tredjegradstermer (kubiska), kombinationer av olika termer (se vidare om samspelstermer senare i kursen) etc. Den kvadratiska termen skapas med MTB > let c6=c4**2 och ges t ex namnet ”Rooms_sq” med MTB > name c6 ’Rooms_sq’
, tredjegradstermer (kubiska), kombinationer av olika termer (se vidare om samspelstermer senare i kursen) etc. Den kvadratiska termen skapas med. MTB > let c6=c4**2 och ges t ex namnet Rooms_sq med. MTB > name c6 ’Rooms_sq’")
56
Bägge är faktiskt signifikanta på 5% nivå
Regression Analysis: Price versus Rooms, Rooms_sq The regression equation is Price = Rooms Rooms_sq Predictor Coef SE Coef T P Constant Rooms Rooms_sq S = R-Sq = 35.6% R-Sq(adj) = 34.7% Analysis of Variance Source DF SS MS F P Regression Residual Error E Total E+11 Bägge är faktiskt signifikanta på 5% nivå Sämre förklaringsgrad dock!
 = 34.7% Analysis of Variance. Source DF SS MS F P. Regression Residual Error E Total E+11. Bägge är faktiskt signifikanta på 5% nivå. Sämre förklaringsgrad dock!")
57
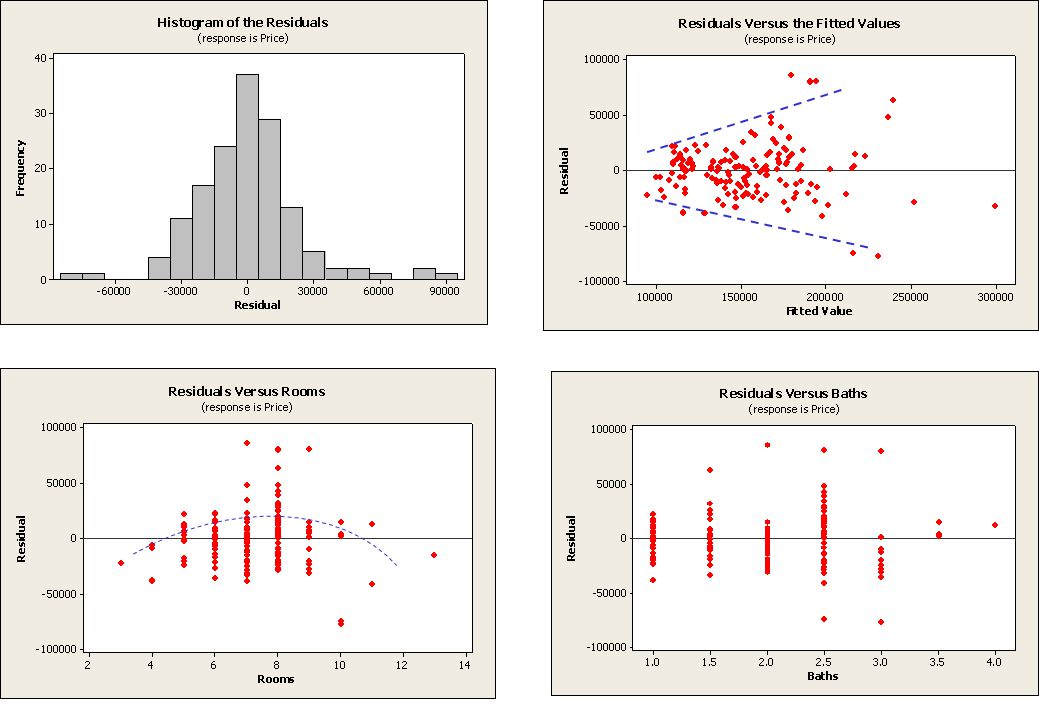
x3 Den svaga krökningen har försvunnit här
men strutformen har återkommit här

58
De anpassade värdena, dvs. plottas nedan mot variabeln x3, dvs. Rooms.
Vi ser tydligt den krökta formen på det anpassade sambandet: En x2-kurva med max-punkt nära x=13. Notera att det finns flera punkter med samma värde på x3 och det är totalt 150 punkter som är plottade i figuren.

Liknande presentationer












>")

>")




