Ladda ner presentationen
Presentation laddar. Vänta.

1
Hur bra är modellen som vi har anpassat?
Vi bedömer modellen med hjälp av ett antal kriterier: visuell bedömning, om möjligt F-test, signifikanstest för hela regressionsmodellen förklaringsgraden, R2 p-värden för de individuella variablerna eller t-kvoter Residualanalys, för att avgöra om regressionsantagandena är uppfyllda

2
Visuell bedömning:

3
Hur bra är modellen som vi har anpassat?
The regression equation is Hyra = Kv-meter Predictor Coef SE Coef T P Constant Kv-meter S = R-Sq = 85.5% R-Sq(adj) = 84.8% Analysis of Variance Source DF SS MS F P Regression Residual Error Total enskilda p-värden R2 och justerad R2 F-test och dess p-värde Residualanalys kan också göras i MINITAB
 = 84.8% Analysis of Variance. Source DF SS MS F P. Regression Residual Error Total enskilda p-värden. R2 och justerad R2. F-test och dess p-värde. Residualanalys kan också göras i MINITAB.")
4
Varför behöver vi så många olika mått på hur bra modellen är?
Om vi bara har en förklarande variabel, så spelar det inte så stor roll vilket mått vi använder: p-värden, R2 och F-test är i princip utbytbara. Residualanalys måste dock alltid genomföras. I de flesta fall kommer vi dock att ha modeller med mer än bara en förklarande variabel. Då är det viktigt att titta på de olika kriterierna var för sig, eftersom de ger olika information.

5
Vi har redan genomfört t-testet för de enskilda parametrarna (intercept och lutning) för att se om de är signifikant skilda från noll. Hur beräknas då R2 och F-testet? Båda är baserade på en jämförelse av hur mycket av variationen i responsvariabeln som kan förklaras genom modellen och hur mycket av variationen som inte kan förklaras

6
Vi har redan räknat med ett mått för den oförklarade variationen: Residualkvadratsumman, som också ofta betecknas med SSE (Sum of Squared Errors). Ett mått på den totala variationen är också ganska enkelt att ta fram: variationen i responsvariabeln, SSyy, som i regressionssammanhang ofta kallas för SST (Totalkvadratsumman).
.")
7
För att göra kvadratsummeuppdelningen komplett kan vi beräkna SSR (Sum of Squares Regression), den förklarade variationen. SSR = SST - SSE eller SST = SSR + SSE Den totala variationen är summan av den (av modellen) förklarade variationen och den återstående variationen. SSR är den del av variationen som inte är slump, men kan förklaras av regressionssambandet.
 förklarade variationen och den återstående variationen. SSR är den del av variationen som inte är slump, men kan förklaras av regressionssambandet.")
8
Förklaringsgrad och korrelationskoefficient
Förklaringsgraden betecknas med R2 Ju högre förklaringsgrad, desto bättre lyckas vår skattade modell förklara variationen i data Modellen kan anses vara bra. I vårt exempel blev R2 = 85.5%, dvs. att 85.5% av all variation i data kan förklaras med hjälp av modellen.

9
Utvikning: Kom ihåg korrelationskoefficienten som mäter det linjära sambandet mellan x och y. I motsats till regressionsmodellen finns det i korrelationskoefficienten ingen kausalitet: regressionsmodellen: x påverkar y, men inte tvärtom korrelationskoefficienten: x och y hänger ihop

10
Korrelationskoefficienten ligger alltid mellan –1 och 1
Korrelationskoefficienten ligger alltid mellan –1 och 1. Om den är = – 1 eller = 1 säger man att det råder ett perfekt linjärt samband mellan y och x. Om r = 0 finns inget linjärt samband mellan y och x. (Det kan dock finnas andra samband, t.ex. kvadratiska) I vårt fall blir korrelationskoefficienten r=0.925 Observera att r2=(0.925)2=0.8556R2 Men detta gäller bara i fallet med en förklaringsvariabel, inte om vi inkluderar fler oberoende variabler i modellen.
 I vårt fall blir korrelationskoefficienten r= Observera att r2=(0.925)2=0.8556R2. Men detta gäller bara i fallet med en förklaringsvariabel, inte om vi inkluderar fler oberoende variabler i modellen.")
11
F-test: MSE har vi träffat på förut, men då kallade vi den för På MINITAB-utskriften kan vi hitta både MSE och se. Om vi bara har en förklarande variabel, så är SSR/1=MSR. Värdet på F-testet ska jämföras med F-fördelningen med 1 och (n-2) frihetsgrader I vårt fall: Ur tabellen: signifikant
 frihetsgrader. I vårt fall: Ur tabellen: signifikant.")
12
F är ett mått på hur stor den förklarade variationen är jämfört med den oförklarade.
Om F är stor då har vi en bra modell som kan förklara mycket och lämnar lite oförklarat. Om vi bara har en förklarande variabel i modellen, så är F = t2 där t kommer från t-testet, när man testar b1.

13
SSR MSR F-test MSE SSE SST The regression equation is
Hyra = Kv-meter Predictor Coef SE Coef T P Constant Kv-meter S = R-Sq = 85.5% R-Sq(adj) = 84.8% Analysis of Variance Source DF SS MS F P Regression Residual Error Total SSR MSR F-test MSE SSE SST
 = 84.8% Analysis of Variance. Source DF SS MS F P. Regression Residual Error Total SSR. MSR. F-test. MSE. SSE. SST.")
14
Multipel regressionsanalys
I stället för en förklarande variabel kan vi inkludera flera. Vi får dock tänka på att inte inkludera sådana variabler som inte har någon eller som bara har marginell betydelse för responsvariabeln. Återigen inkluderas en felterm e i modellen, som står för den del i variationen av y som inte kan förklaras genom modellen. Feltermen har medelvärde 0 och varians s2 och är normalfördelad och varje e är oberoende av de andra e.

15
t-test och konfidensintervall för de enskilda parametrarna (b1, b2,
t-test och konfidensintervall för de enskilda parametrarna (b1, b2, ..., bk) i modellen beräknas i princip på samma sätt som förut. Men nu använder man en t-fördelning med n-k-1 frihetsgrader. F-test korrigeras lite genom att inkludera k (antal förklarande variabler i modellen): Observera att formeln är den samma som förut om man sätter k=1. Förklaringsgrad beräknas fortfarande:
 i modellen beräknas i princip på samma sätt som förut. Men nu använder man en t-fördelning med n-k-1 frihetsgrader. F-test korrigeras lite genom att inkludera k (antal förklarande variabler i modellen): Observera att formeln är den samma som förut om man sätter k=1. Förklaringsgrad beräknas fortfarande:")
16
Kvadratsummeuppdelningen gäller förstås också: SST = SSR + SSE
SST, SSR beräknas som förut, och även SSE beräknas som förut: eftersom punktskattningen/punktprognosen nu är: Observera att alla sådana beräkningar görs för varje observation, även om index i inte alltid är med.

17
Konfidensintervall för punktskattningen och prognosintervall for punktprognosen beräknas i princip på samma sätt Konfidensintervall Prognosintervall Men “Distance value” kan inte beräknas lika enkelt som i fallet med en förklarande variabel. Däremot kan man ta den rätt enkelt från datorutskriften (senare).
.")
18
Källa: ”MTBWIN”/Student12/HOMES.MTW
Följande datamaterial innehåller uppgifter om 150 slumpmässigt valda fastigheter i USA Column Name Count Description Modell Översättning C1 Price 150 Price y pris C2 Area 150 Area in square feet x1 bostadsyta C3 Acres 150 Acres x2 tomtyta C4 Rooms 150 Number of rooms x3 antal rum C5 Baths 150 Number of baths x4 antal badrum Källa: ”MTBWIN”/Student12/HOMES.MTW

19
Pris mot bostadsyta

20
Pris mot tomtyta

21
Pris mot antal rum

22
Pris mot antal badrum

23
Vi börjar med en modell som inte inkluderar alla förklarande variabler, men bara de som verkar viktigast: bostadsyta och antal rum.

24
Signifikanstest för t.ex. b1:
Regression Analysis: Price versus Area, Rooms The regression equation is Price = Area Rooms Predictor Coef SE Coef T P Constant Area Rooms Signifikanstest för t.ex. b1: är den skattade standardavvikelsen av b1 Vi jämför t med t-fördelningen med n-k-1= frihetsgrader.

25
t-fördelning med 147 frihetsgrader
för ett dubbelsidig test är p-värdet sannolikheten att få ett värde t eller ännu större eller ett värde –t eller ännu mindre. -6.62 t=6.62

26
inte signifikant Regression Analysis: Price versus Area, Rooms
The regression equation is Price = Area Rooms Predictor Coef SE Coef T P Constant Area Rooms inte signifikant

27
F-testet är signifikant
S = R-Sq = 48.6% R-Sq(adj) = 47.9% Analysis of Variance Source DF SS MS F P Regression E Residual Error E Total E+11 F-testet är signifikant
 = 47.9% Analysis of Variance. Source DF SS MS F P. Regression E Residual Error E Total E+11. F-testet är signifikant.")
28
Vad står F-testet för i detta fall?
F-testet testar om ‘den linjära regressionsmodellen’ är signifkant eller inte. Om vi bara har en förklarande variabel då är det samma som att testa om denna variabel (parameter b1) är signifikant. Om vi har flera förklarande variabler, då testar vi om H0: alla parametrar b1, b2,..., bk är lika med 0 H1: minst en av parametrarna b1, b2,..., bk är inte 0 För att bestämmer vilka parametrar som är skilda från 0 använder vi t-testet.
 är signifikant. Om vi har flera förklarande variabler, då testar vi om. H0: alla parametrar b1, b2,..., bk är lika med 0. H1: minst en av parametrarna b1, b2,..., bk är inte 0. För att bestämmer vilka parametrar som är skilda från 0 använder vi t-testet.")
29
Vad är R-sq(adj) då? Justerad R2:
 då Justerad R2:")
30
När man anpassar en regressionsmodell har man oftast två mål:
att hitta en modell som beskriver datamaterialet så bra som möjligt (de anpassade värdena ska ligga nära observationerna ) att hitta en modell som kan göra prediktioner för nya observationer. Göra bra punktprediktioner. Genom att inkludera stora mängder förklarande variabler kan man ofta få bättre och bättre anpassning till datamaterialet, men prognoserna för nya observationer kan bli sämre (överanpassning).
 att hitta en modell som kan göra prediktioner för nya observationer. Göra bra punktprediktioner. Genom att inkludera stora mängder förklarande variabler kan man ofta få bättre och bättre anpassning till datamaterialet, men prognoserna för nya observationer kan bli sämre (överanpassning).")
31
Det vanliga R2-värdet ökar alltid när man lägger till fler förklarande variabler.
Det justerade R2-värdet ökar inte alltid om man lägger till fler förklarande variabler, eftersom det innehåller en korrektion för antalet förklarande variabler i modellen (k). Justering, så att föklaringsgraden fortfarande ligger mellan 0 och 100%. Justering för att antalet förklarande variabler är k
. Justering, så att föklaringsgraden fortfarande ligger mellan 0 och 100%. Justering för att antalet förklarande variabler är k.")
32
Punktskattning och punktprognos
Nu vill vi göra en prognos för priset på en fastighet med bostadsytan: 3000 ft2 och antal rum: 6, och ett 95% prediktionsintervall i MINITAB

33
Prediktionsintervall
Regression Analysis: Price versus Area, Rooms Samma utskrift som tidgare Predicted Values for New Observations New Obs Fit SE Fit % CI % PI ( , ) ( , ) XX X denotes a row with X values away from the center XX denotes a row with very extreme X values Values of Predictors for New Observations New Obs Area Rooms Prediktionsintervall
 ( , ) XX. X denotes a row with X values away from the center. XX denotes a row with very extreme X values. Values of Predictors for New Observations. New Obs Area Rooms Prediktionsintervall.")
34
Regression Analysis: Price versus Area, Rooms
Samma utskrift som tidgare Predicted Values for New Observations New Obs Fit SE Fit % CI % PI ( , ) ( , ) XX X denotes a row with X values away from the center XX denotes a row with very extreme X values Values of Predictors for New Observations New Obs Area Rooms Konfidensintervall för det genomsnittliga priset på fastigheter med 3000 ft2 och 6 rum.
 ( , ) XX. X denotes a row with X values away from the center. XX denotes a row with very extreme X values. Values of Predictors for New Observations. New Obs Area Rooms Konfidensintervall för det genomsnittliga priset på fastigheter med 3000 ft2 och 6 rum.")
35
SE Fit är standardavvikelsen för punktskattningen
‘Distance value’ kan, som sagt, inte enkelt beräknas från datamaterialet om vi har fler än en förklarande variabel. Men den kan beräknas ur New Obs Fit SE Fit % CI % PI ( , ) ( , ) XX SE Fit är standardavvikelsen för punktskattningen
 ( , ) XX. SE Fit är standardavvikelsen för punktskattningen.")
36
Får vi någon ytterligare information från prognosen?
Predicted Values for New Observations New Obs Fit SE Fit % CI % PI ( , ) ( , ) XX X denotes a row with X values away from the center XX denotes a row with very extreme X values Varning att fastigheten vi vill veta någonting om har extrema värden för x. Vi kan göra tillförlitliga prognoser bara för fastigheter där vi har liknande fastigheter redan i ursprungliga datamaterialet.
 ( , ) XX. X denotes a row with X values away from the center. XX denotes a row with very extreme X values. Varning att fastigheten vi vill veta någonting om har extrema värden för x. Vi kan göra tillförlitliga prognoser bara för fastigheter där vi har liknande fastigheter redan i ursprungliga datamaterialet.")
37
Om vi t.ex bara har bostadsytan som förklarande variabel: Prediktioner utanför området där vi har observationer är inte tillförlitliga

38
Pris mot bostadsyta Få observation med bostadsyta 3000 ft2 eller större, men ändå väl inom området där vi har observation

39
Pris mot antal rum

40
Om vi tittar på datamaterialet så ser
Vad är då problemet? Om vi tittar på datamaterialet så ser vi att de fastigheter som ingår och har exakt 6 rum har en bostadsyta mellan 1008 och 1900 ft2. Det är alltså kombinationen 3000 ft2 och 6 rum som är extrem och vi måste fundera över om det är rimligt att anta att modellen är giltig även för denna typ av fastighet. pris area rooms 117000 1008 6 108000 1036 126500 1092 133000 1100 116000 98000 1165 129000 1200 126000 1232 1248 110000 1289 117500 1300 121900 100000 1338 128500 1344 135000 1400 140000 1403 152000 1450 142500 1552 150000 1564 120500 1600 141900 1632 145900 1680 144900 1900

41
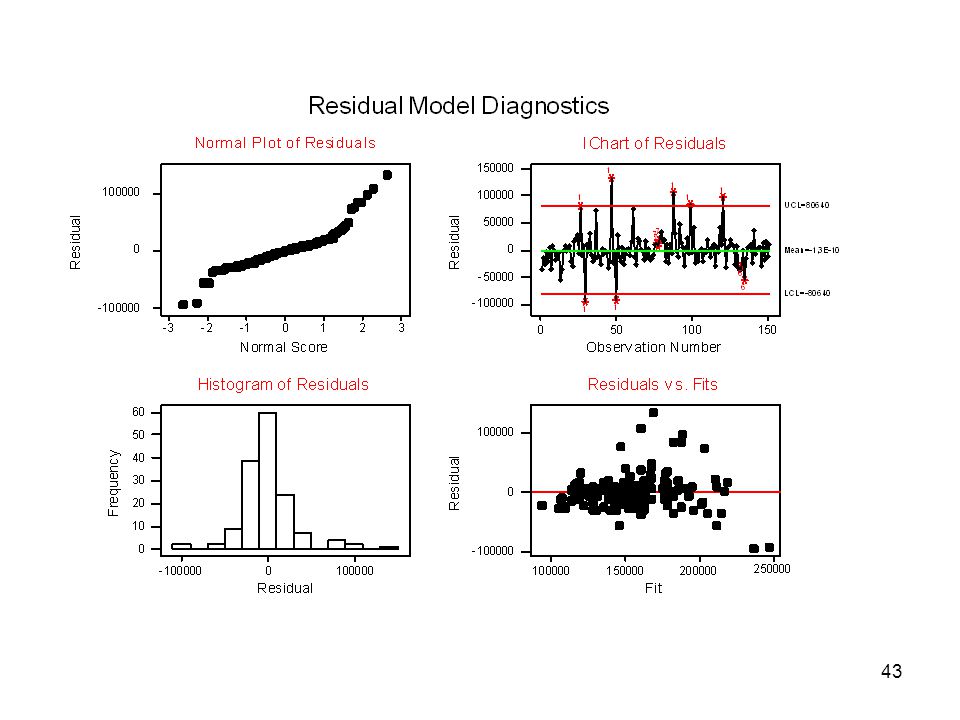
Residualanalys För att överhuvudtaget kunna ta resultaten av regressionsanalysen på allvar, måste vi undersöka om regressionsantagandena är uppfyllda. Har residualerna en konstant varians? Är residualerna normalfördelade? Är residualerna oberoende? Är alla samband linjära?

42
Har residualerna en konstant varians?
Plotta residualerna mot anpassade värden (residuals vs fits) Är residualerna normalfördelade? Histogram av residualerna Normalfördelningsdiagram av residualerna (Normal plot...) Är residualerna oberoende? Plotta residualerna i observationsordning (residuals vs order). Är alla samband linjära? Plotta residualerna mot enskilda förklarande variabler (Residuals vs the variables)
 Är residualerna normalfördelade Histogram av residualerna. Normalfördelningsdiagram av residualerna (Normal plot...) Är residualerna oberoende Plotta residualerna i observationsordning (residuals vs order). Är alla samband linjära Plotta residualerna mot enskilda förklarande variabler (Residuals vs the variables)")
Liknande presentationer



 5. Problem med nedskräpning (fråga 1a) 6. Problem med skadegörelse (fråga 1b)>")









>")





