Ladda ner presentationen
Presentation laddar. Vänta.

1
732G71 STATISTIK B Vad förväntas man egentligen kunna efter genomgången kurs? Exempel: Du sitter i ett projektmöte på din arbetsplats. Din chef (om det inte är du) är något upprörd över att en ny amerikansk studie påstås visa att försäljningsresultat kan förbättras om lager är spridda geografiskt än om de är samlade till ett fåtal ställen. Inom företaget har man på senare år arbetat enligt det motsatta förhållandet. Chefen säger till dig: Du är ju en relativt nyutbildad ekonom. Har du inte läst statistik? Ditt svar blir förstås: Javisst! (även om du inombords blir en aning panikslagen) Chefen: Då så! Du kan väl ta och kolla upp den där studien. Jag är ganska säker på att det är trams det mesta, men för säkerhets skull…
 är något upprörd över att en ny amerikansk studie påstås visa att försäljningsresultat kan förbättras om lager är spridda geografiskt än om de är samlade till ett fåtal ställen. Inom företaget har man på senare år arbetat enligt det motsatta förhållandet. Chefen säger till dig: Du är ju en relativt nyutbildad ekonom. Har du inte läst statistik. Ditt svar blir förstås: Javisst. (även om du inombords blir en aning panikslagen) Chefen: Då så. Du kan väl ta och kolla upp den där studien. Jag är ganska säker på att det är trams det mesta, men för säkerhets skull….")
2
Saxat ur “den amerikanska studien”: …The slopes are clearly significant, which tells us that it seems reasonable to assume that the covariates have a clear impact on the sales, especially when we have removed the units that were supposed to induce undesired intra-relationships between the predictors. The interpretation of the final model is that the mean result increases with approximately 2% per storage unit with a 99% error margin of 0.7%. There is some intra-annual variation, that might affect the predictions, especially in summer months… Ovanstående innehåller komponenter som alla har tagits upp på ett eller annat sätt i kursen. Vad borde du kunna göra i detta fall?

3
1.Naturligtvis läsa, förstå och kunna återge innehållet i den amerikanska studien. 2.Validera resultaten mot data ni har i ert eget företag, dvs. försöka upprepa vad amerikanerna har gjort men med egna data. 3.Kritiskt ifrågasätta sådant som är tveksamt i studien Skall man verkligen ta bort observationer när de ger upphov till multikolinjäritetsproblem? Skall man blanda rena regressionsmodeller med tidsseriemodeller innehållande säsongsmodellering? Finns det problem med modellantagandena? 4.Återföra till “chefen” och endera bekräfta eller motbevisa hans uppfattning om att det mesta är “trams”

4
Den enkla linjära regressionen Ni skall kunna “för hand” räkna fram parameterskattningar, konfidensintervall, prognosintervall, korrelationskoefficienter, förklaringsgrader etc. − Varför skall vi kunna göra detta för hand när det i praktiken alltid görs med datorprogram? − Handräkningen visar att man förstår vad de olika komponenterna i en modell “står för”. Vad som är y, vad som är x, vad det är man skattar och vad det t.ex. är för skillnad på konfidens- och prognosintervall. Vidare är den enkla linjära regression grund för att även kunna räkna på enkla exponentiella modeller och elasticitetsmodeller. “Omsättning av formler” är nyttig att göra för att inte bli låst till att allt måste heta y och x.

5
Exempel på uppgift ni förväntas kunna lösa (Övningstentan, uppgift 1) I en omfattande studie har man undersökt ett urval om 10 koncerner med avseende pä deras affärsstrategier. I studien ställer man bl.a. frågor om graden av miljöinriktad affärsstrategi och frågorna ställs dels till en ansvarig person i koncernledningen, dels till en ansvarig person i den viktigaste affärsenheten i koncernen. En av de frågor som ställs är den övergripande (här i något förenklad form): Vilken grad av miljöinriktning bedömer du att ni har i er strategi? Låg O O O O O O O O O Hög Svarsskalan brukar kallas Likert-skala och är sådan att svarsstegen kan antas ligga lika långt från varandra (en s.k. intervallskala). Detta möjliggör användande av korrelations- koefficienter och regressionsmodeller vid analysarbetet. De erhållna svaren kodas med talen 1, 2,..., 9 där 1 används för ett svar längst till vänster i skalan och 9 för ett svar längst till höger. Med hjälp av de inkomna svaren vill man försöka hitta ett regressionssamband där ett svar på koncernnivå förklaras av svaret på affärsenhetsnivå.
: Vilken grad av miljöinriktning bedömer du att ni har i er strategi. Låg O O O O O O O O O Hög Svarsskalan brukar kallas Likert-skala och är sådan att svarsstegen kan antas ligga lika långt från varandra (en s.k. intervallskala). Detta möjliggör användande av korrelations- koefficienter och regressionsmodeller vid analysarbetet. De erhållna svaren kodas med talen 1, 2,..., 9 där 1 används för ett svar längst till vänster i skalan och 9 för ett svar längst till höger. Med hjälp av de inkomna svaren vill man försöka hitta ett regressionssamband där ett svar på koncernnivå förklaras av svaret på affärsenhetsnivå..")
6
Följande kodade svar har erhållits: Koncern (i) Svar på koncernnivå (y) Svar på affärsenhetsnivå (x) 1 5 4 2 2 3 3 4 4 4 7 6 5 1 1 6 1 3 7 2 4 8 6 6 9 3 1 10 8 9 Följande har beräknats: x 2 =221 y 2 =209 xy =207 Antag modellen y i = 0 + 1 x i + i ; i = 1, 2, …, 10
 Svar på koncernnivå (y) Svar på affärsenhetsnivå (x) Följande har beräknats: x 2 =221 y 2 =209 xy =207 Antag modellen y i = 0 + 1 x i + i ; i = 1, 2, …, 10")
7
a) Vilka antaganden måste göras för 1, 2,…, 10 för att modellen skall kunna analyseras på vanligt sätt? Försök komma på minst en orsak till att något av antaganden inte skulle vara uppfyllt. (1p) b) Beräkna punktskattningar av parametrarna 0 och 1. (1.5p) c) Avgör med ett lämpligt test på 5% nivå om det föreligger någon regression mellan y och x. (1.5p) d) Beräkna den anpassade modellens förklaringsgrad och tolka denna. (1p) e) Beräkna ett 95% konfidensintervall för det genomsnittliga svaret på koncernnivå för alla koncerner i populationen där svaren på affärsnivå samtliga är 7. (1.5p) f) Gör en prognos av svaret på koncernnivå för en koncern där svaret på affärsenhetsnivå är 7. Beräkna också ett 99% prognosintervall. (1.5p) a)De skall ha väntevärde 0, konstant varians, vara oberoende och normalfördelade. Det som främst inte är självklart är antagandet om normalfördelning, Teoretiskt kan vi inte ha normalfördelade avvikelser eftersom svarsvärdena bara kan vara något av talen 1, 2, …, 9. Övriga antagande kan förstås också diskuteras men där är det svårare att hitta orsaker, t.ex. skulle det kunna finnas samband mellan olika koncerner som stör oberoendeantagandet.
 b) Beräkna punktskattningar av parametrarna 0 och 1. (1.5p) c) Avgör med ett lämpligt test på 5% nivå om det föreligger någon regression mellan y och x. (1.5p) d) Beräkna den anpassade modellens förklaringsgrad och tolka denna. (1p) e) Beräkna ett 95% konfidensintervall för det genomsnittliga svaret på koncernnivå för alla koncerner i populationen där svaren på affärsnivå samtliga är 7. (1.5p) f) Gör en prognos av svaret på koncernnivå för en koncern där svaret på affärsenhetsnivå är 7. Beräkna också ett 99% prognosintervall. (1.5p) a)De skall ha väntevärde 0, konstant varians, vara oberoende och normalfördelade. Det som främst inte är självklart är antagandet om normalfördelning, Teoretiskt kan vi inte ha normalfördelade avvikelser eftersom svarsvärdena bara kan vara något av talen 1, 2, …, 9. Övriga antagande kan förstås också diskuteras men där är det svårare att hitta orsaker, t.ex. skulle det kunna finnas samband mellan olika koncerner som stör oberoendeantagandet..")
8
b) Beräkna punktskattningar… Använd t.ex. formlerna I utskriften ges de komplicerade summorna medan x och y får lov att beräknas denna gång: x = 4 + 3 + 4 + 6 + 1 + 3 + 4 + 6 + 1 + 9 = 41 y = 5 + 2 + 4 + 7 + 1 + 1 + 2 + 6 + 3 + 8 = 39

9
c) Avgör med ett lämpligt test på 5% nivå om det föreligger någon regression mellan y och x. Det finns två ekvivalenta sätt att göra detta. Gemensamt är dock formuleringen av hypoteserna som bör se ut så här: H 0 : 1 = 0H 1 : 1 0 Varför det då? Jo det enda som reglerar regressionen är 1. Om denna är 0 finns ingen regression. Vad 0 är spelar ingen som helst roll! Testmetod 1: t- test Testvariabeln beräknas som Vi behöver beräkna s !

10
Testvariabelns värde blir nu Värdet skall nu jämföras med en t-fördelning med n – 2 = 8 frihetsgrader. Tabellvärdet för 5% nivå (95% konfidensnivå) blir 2.31 Eftersom 2.31 < 4.74 förkastas H 0 Signifikant regression föreligger! Testmetod 2: F-test Testvariabeln beräknas som Med våra data blir Vi jämför med F [0.05] (1,8) = 5.32 Eftersom 22.4 > 5.32 kan H 0 förkastas
 blir 2.31 Eftersom 2.31 < 4.74 förkastas H 0 Signifikant regression föreligger. Testmetod 2: F-test Testvariabeln beräknas som Med våra data blir Vi jämför med F [0.05] (1,8) = 5.32 Eftersom 22.4 > 5.32 kan H 0 förkastas.")
11
d) Beräkna den anpassade modellen förklaringsgrad och tolka denna Förklaringsgraden beräknas till På tentorna ser man ofta att tolkningen glöms bort ( poängavdrag) Tolkningen är att 73.7% av variationen i y förklaras av x. e) Beräkna ett 95% konfidensintervall för det genomsnittliga svaret på koncernnivå för alla koncerner i populationen där svaren på affärsnivå samtliga är 7. Här söker vi alltså ett konfidensintervall för Formel:
 Beräkna ett 95% konfidensintervall för det genomsnittliga svaret på koncernnivå för alla koncerner i populationen där svaren på affärsnivå samtliga är 7. Här söker vi alltså ett konfidensintervall för Formel:.")
12
f) Gör en prognos av svaret på koncernnivå för en koncern där svaret på affärsenhetsnivå är 7. Beräkna också ett 99% prognosintervall. Denna uppgift är mycket lika e). Lägg bara till en etta under rottecknet i formeln: Notera att den övre gränsen faktiskt ligger utanför det möjliga dataområdet! Glöm inte att specifikt ange att prognosen är 6.5
. Lägg bara till en etta under rottecknet i formeln: Notera att den övre gränsen faktiskt ligger utanför det möjliga dataområdet. Glöm inte att specifikt ange att prognosen är 6.5.")
13
Den multipla regressionen Här är det svårare att räkna för hand! Från datorutskrifter kan ni räkna med att få ut parameterskattningar (b 0, b 1, …, b k ) medelfel för parameterskattningar ( ) kvadratsummor (SSR, SSE, SST samt SSR(x k | x 1,…,x k – 1 ) dvs. sekventiella kvadratsummor) konfidens- och prognosintervall i en given punkt Vad måste ni själva kunna inse eller beräkna utifrån datorutskriften? antal frihetsgrader (framgår ju av formelsamlingen när man vet n ) medelkvadratsummor, s testvariabler förklaringsgrader omräkning av intervall från 95% till 99% och vice versa
 medelfel för parameterskattningar ( ) kvadratsummor (SSR, SSE, SST samt SSR(x k | x 1,…,x k – 1 ) dvs. sekventiella kvadratsummor) konfidens- och prognosintervall i en given punkt Vad måste ni själva kunna inse eller beräkna utifrån datorutskriften. antal frihetsgrader (framgår ju av formelsamlingen när man vet n ) medelkvadratsummor, s testvariabler förklaringsgrader omräkning av intervall från 95% till 99% och vice versa.")
14
Speciella utskrifter: VIF-värden Resultat från breg Resultat från stepwise Dessa måste förstås kunna tolkas. Utskrifterna på denna punkt ges dock i sin helhet utan “censurering”.

15
Exempel på uppgift ni förväntas kunna lösa (Övningstentan, uppgift 2) Vid en bank i Chicago har man för 93 anställda samlat in uppgifter om lön y antal utbildningsår vid anställningx 1 tidigare erfarenhet av bankarbete i månaderx 2 anställningstid i månader x 3 kön x 4 = 1 för män och = 0 för kvinnor. Följande visar ett litet utdrag ur datamaterialet: lön (y) utbildningstid (x 1 ) erfarenhet (x 2 ) anst.tid (x 3 ) kön (x 4 ) 3900 12 0.0 1 0 4020 10 44.0 7 0 4290 12 5.0 30 0 4380 8 6.2 7 0 4380 8 7.5 6 0 4380 12 0.0 7 0 4380 12 0.0 10 0... 6840 15 41.5 7 1 6900 12 175.0 10 1 6900 15 132.0 24 1 8100 16 54.5 33 1
 utbildningstid (x 1 ) erfarenhet (x 2 ) anst.tid (x 3 ) kön (x 4 )")
16
Man lägger till variabeln x2 · x4 och gör en anpassning av modellen y = 0 + 2 · x 2 + 4 · x 4 + 5 · x 2 · x 4 + Ett utdrag ur en analys med Minitab är följande: MTB > regress c1 3 c3 c5 c6; SUBC> vif; SUBC> predict 100 0 0. Regression Analysis: y versus x2, x4, x2*x4 The regression equation is y = 4919 + 2.20 x2 + 1045 x4 - 2.26 x2*x4 Predictor Coef SE Coef T P VIF Constant 4919.2 115.4 * * x2 2.1973 0.8815 * * 1.7 x4 1044.5 187.2 * * 2.2 x2*x4 -2.264 1.351 * * 2.9 S = 582.2 R-Sq = * R-Sq(adj) = * Analysis of Variance Source DF SS MS F P Regression 3 16152852 * * * Residual Error 89 30170439 * Total 92 46323290
 = * Analysis of Variance Source DF SS MS F P Regression * * * Residual Error * Total")
17
Source DF Seq SS x2 1 1289861 x4 1 13911841 x2*x4 1 951150... Predicted Values for New Observations New Obs Fit SE Fit 95.0% CI 95.0% PI 1 5138.9 74.5 ( 4990.8, 5287.0) ( 3972.6, 6305.2) Values of Predictors for New Observations New Obs x2 x4 x2*x4 1 100 0.000000 0.000000 Notera att i denna utskrift har medvetet censurerats bort: T-kvoter och P-värden för dessa Medelkvadratsummor, F-kvot och P-värde R-sq och R-sq(adj)
 ( , ) Values of Predictors for New Observations New Obs x2 x4 x2*x Notera att i denna utskrift har medvetet censurerats bort: T-kvoter och P-värden för dessa Medelkvadratsummor, F-kvot och P-värde R-sq och R-sq(adj).")
18
a) Beräkna (i) den anpassade modellens justerade förklaringsgrad. (ii) ett 95% konfidensintervall för 2 (1p) Analysis of Variance Source DF SS MS F P Regression 3 16152852 * * * Residual Error 89 30170439 * Total 92 46323290 (i) (ii) Predictor Coef SE Coef Constant 4919.2 115.4 x2 2.1973 0.8815 x4 1044.5 187.2 x2*x4 -2.264 1.351 Residual Error 89
 ett 95% konfidensintervall för 2 (1p) Analysis of Variance Source DF SS MS F P Regression * * * Residual Error * Total (i) (ii) Predictor Coef SE Coef Constant x x x2*x Residual Error 89.")
19
Svarsalternativen i facit är följande: 1 (i) 34.9% (ii) 2.20 ± 4.90 2 (i) 32.7% (ii) 1044.5 ± 366.9 3 (i) 65.1% (ii) 1044.5 ± 366.9 4 (i) 34.9% (ii) 1044.5 ± 366.9 5 (i) 34.9% (ii) 2.20 ± 1.73 6 (i) 32.7% (ii) 2.20 ± 1.73 Alternativ 6 är alltså det korrekta. Hur har då de andra alternativen uppstått? 34.9% är förklaringsgraden, men det är alltså den justerade som efterfrågas. 65.1% är 100% – R 2 vilket alltså är en felräkning på det som inte efterfrågas 2.20 4.90 uppstår om man får för sig att felmarginalen är kvadraten på s dividerad med roten ur n (93). Långsökt fel! 1044.5 366.9 är ett K.I. för 4. Detta kan av slarv uppstå om man fått för sig att koefficienternas index (i detta fall 2) utgår från i vilken ordning variabeln tas in i analysen.
. Långsökt fel är ett K.I. för 4. Detta kan av slarv uppstå om man fått för sig att koefficienternas index (i detta fall 2) utgår från i vilken ordning variabeln tas in i analysen..")
20
b) Beräkna ett 99% prognosintervall för lönen hos en kvinnlig anställd med 100 månaders tidigare erfarenhet. (0.5p) Predicted Values for New Observations New Obs Fit SE Fit 95.0% CI 95.0% PI 1 5138.9 74.5 ( 4990.8, 5287.0) ( 3972.6, 6305.2) Values of Predictors for New Observations New Obs x2 x4 x2*x4 1 100 0.000000 0.000000 Den prognos och de intervall som redovisas i utskriften är just för en kvinna (x 4 = 0) med 100 månaders erfarenhet (x 2 = 100) Formel för ett 99% prognosintervall: S = 582.2
 Predicted Values for New Observations New Obs Fit SE Fit 95.0% CI 95.0% PI ( , ) ( , ) Values of Predictors for New Observations New Obs x2 x4 x2*x Den prognos och de intervall som redovisas i utskriften är just för en kvinna (x 4 = 0) med 100 månaders erfarenhet (x 2 = 100) Formel för ett 99% prognosintervall: S =")
21
I tentan ingående t-tabell omfattar inte frihetsgradstalet 89 Helt OK att använda normalfördelningsvärden istället. (står också i tentan) 99% P.I. ger normalfördelningsvärdet 2.576 Svarsalternativen i facit är följande: 1 (3973,6305) 2 (4991,5287) 3 (3769,6571) 4 (3627,6651) 5 (3755,6523) 6 (4944,5334) Alternativ 4 är alltså det som stämmer. Övriga alternativ: Alternativ 1 är det 95%-iga prognosintervallet som finns i utskriften Alternativ 2 är det 95%-iga konfidensintervallet som finns i utskriften Övriga alternativ är mer långsökta
 99% P.I. ger normalfördelningsvärdet Svarsalternativen i facit är följande: 1 (3973,6305) 2 (4991,5287) 3 (3769,6571) 4 (3627,6651) 5 (3755,6523) 6 (4944,5334) Alternativ 4 är alltså det som stämmer. Övriga alternativ: Alternativ 1 är det 95%-iga prognosintervallet som finns i utskriften Alternativ 2 är det 95%-iga konfidensintervallet som finns i utskriften Övriga alternativ är mer långsökta.")
22
Man vill testa hypotesen H 0 : 4 = 5 = 0 på 5% nivå. d) Beräkna testfunktionens värde och avgör om nollhypotesen skall förkastas eller ej. (1p) Här skall vi alltså göra ett partiellt F-test. Analysis of Variance Source DF SS Regression 3 16152852 Residual Error 89 30170439 Total 92 46323290 Source DF Seq SS x2 1 1289861 x4 1 13911841 x2*x4 1 951150 Jämför med F [0.05] (2,89). Tabellen har dock inga frihetsgrader mellan 80 och 100, men värdena sjunker med ökad frihetsgrad. F [0.05] (2,89). < F [0.05] (2,80) = 3.11 < 21.92 H 0 förkastas
 Beräkna testfunktionens värde och avgör om nollhypotesen skall förkastas eller ej. (1p) Här skall vi alltså göra ett partiellt F-test. Analysis of Variance Source DF SS Regression Residual Error Total Source DF Seq SS x x x2*x Jämför med F [0.05] (2,89). Tabellen har dock inga frihetsgrader mellan 80 och 100, men värdena sjunker med ökad frihetsgrad. F [0.05] (2,89). < F [0.05] (2,80) = 3.11 < H 0 förkastas.")
23
Svarsalternativen i facit är följande: 1 Testfunktionens värde=0.53, H 0 förkastas ej 2 Testfunktionens värde=3.81, H 0 förkastas ej 3 Testfunktionens värde=15.88, H 0 förkastas ej 4 Testfunktionens värde=15.88, H 0 förkastas 5 Testfunktionens värde=21.92, H 0 förkastas 6 Testfunktionens värde=23.82, H 0 förkastas Alternativ 5 är alltså det korrekta. Alternativ 1 uppstår om man försöker räkna ut testvariabeln för det “vanliga” F- testet men tar SSR/SSE istället för MSR/MSE. Alternativ 2 uppstår om man tar SSR(x 2 ) istället för SSR(x 4 |x 2 )+SSR(x 2 x 4 |x 2,x 4 ) i täljaren till testvariabeln Alternativ 3 och 4 ger teststorheten för det vanliga F-testet med olika slutsatser. Alternativ 6 är mer långsökt
 istället för SSR(x 4 |x 2 )+SSR(x 2 x 4 |x 2,x 4 ) i täljaren till testvariabeln Alternativ 3 och 4 ger teststorheten för det vanliga F-testet med olika slutsatser. Alternativ 6 är mer långsökt.")
24
e) Vilket av följande uttalanden om multikolinjäritetsproblem är inte korrekt? (i) Tecknen på de skattade lutningsparametrarna kan bli orealistiska om problem finns med multikolinjäritet. (ii) Man bör definitivt ta bort två av förklaringsvariablerna i modellen för att undvika svåra problem med multikolinjäritet. (iii) Variabeln x 2 ·x 4 förklaras till (1− 1/2.9 )·100% 65.5% av de andra två förklaringsvariablerna. (iv) VIF–värdena ger information om huruvida en förklaringsvariabel har multipel korrelation med de övriga förklaringsvariablerna. (v) Inget av VIF-värdena är över 10, vilket tyder på måttliga problem med multikolinjäritet. (0.5p) Predictor Coef SE Coef VIF Constant 4919.2 115.4 x2 2.1973 0.8815 1.7 x4 1044.5 187.2 2.2 x2*x4 -2.264 1.351 2.9 Alternativ (ii) är inte korrekt. Det finns inga svåra problem med multikolinjäritet här då VIF-värdena är långt under 10. Alternativ (iii) är helt korrekt även om det kan låta komplicerat. VIF värdet 2.9 är = 1/(1-R 2 3 ) där R 2 3 är förklaringsgraden i en modell där x 2 x 4 förklaras av x 2 och x 4
 Tecknen på de skattade lutningsparametrarna kan bli orealistiska om problem finns med multikolinjäritet. (ii) Man bör definitivt ta bort två av förklaringsvariablerna i modellen för att undvika svåra problem med multikolinjäritet. (iii) Variabeln x 2 ·x 4 förklaras till (1− 1/2.9 )·100% 65.5% av de andra två förklaringsvariablerna. (iv) VIF–värdena ger information om huruvida en förklaringsvariabel har multipel korrelation med de övriga förklaringsvariablerna. (v) Inget av VIF-värdena är över 10, vilket tyder på måttliga problem med multikolinjäritet. (0.5p) Predictor Coef SE Coef VIF Constant x x x2*x Alternativ (ii) är inte korrekt. Det finns inga svåra problem med multikolinjäritet här då VIF-värdena är långt under 10. Alternativ (iii) är helt korrekt även om det kan låta komplicerat. VIF värdet 2.9 är = 1/(1-R 2 3 ) där R 2 3 är förklaringsgraden i en modell där x 2 x 4 förklaras av x 2 och x 4.")
25
Nedan följer ytterligare en analys med samtliga x-variabler inblandade: MTB > breg c1 c2-c6 Best Subsets Regression: y versus x1, x2, x3, x4, x2*x4 Response is y x 2 * x x x x x Vars R-Sq R-Sq(adj) C-p S 1 2 3 4 4 1 30.3 29.6 36.2 595.57 X 1 17.0 16.1 60.2 650.11 X 2 42.0 40.7 17.3 546.52 X X 2 36.3 34.9 27.4 572.44 X X 3 48.5 46.8 7.5 517.75 X X X 3 43.7 41.8 16.1 541.32 X X X 4 51.1 48.9 4.9 507.42 X X X X 4 48.8 46.4 9.0 519.30 X X X X 5 51.6 48.8 6.0 507.79 X X X X X
 C-p S X X X X X X X X X X X X X X X X X X X X X X X X X")
26
f) Vilket av följande påståenden stämmer bäst beträffande val av modell? (i) Modellen med fem förklaringsvariabler är bäst eftersom den har högst förklaringsgrad. (ii) Modellen med x 1, x 2, x 3 och x 4 bör väljas eftersom dess C–värde är i paritet med vad det bör vara. (iii) Modellen med fem förklaringsvariabler bäst eftersom R 2, R 2 och s 2 samtidigt får gynnsamma värden. (iv) Modellen med x 1 bör väljas p g a att den har högst värde på C. (v) Modellen med x 1, x 3 och x 4 är bäst eftersom dess C–värde är närmast 2 · k + 1. (1p) Alternativ (ii) stämmer bäst. C =4.9 som är det lägsta värdet och samtidigt lägre än antal variabler (4) + 1 Alternativ (i) stämmer inte eftersom förklaringsgraden alltid ökar med antalet variabler. Alternativ (iii) stämmer inte bra. Värdena skall inte vara ”gynnsamma” utan kriterierna skall användas (högst justerad förklaringsgrad eller lägsta godkända värde på C) Alternativ (iv) är tvärt emot vad kriterierna säger Alternativ (v) är nonsens. Sådana kriterier finns inte.
 Modellen med fem förklaringsvariabler är bäst eftersom den har högst förklaringsgrad. (ii) Modellen med x 1, x 2, x 3 och x 4 bör väljas eftersom dess C–värde är i paritet med vad det bör vara. (iii) Modellen med fem förklaringsvariabler bäst eftersom R 2, R 2 och s 2 samtidigt får gynnsamma värden. (iv) Modellen med x 1 bör väljas p g a att den har högst värde på C. (v) Modellen med x 1, x 3 och x 4 är bäst eftersom dess C–värde är närmast 2 · k + 1. (1p) Alternativ (ii) stämmer bäst. C =4.9 som är det lägsta värdet och samtidigt lägre än antal variabler (4) + 1 Alternativ (i) stämmer inte eftersom förklaringsgraden alltid ökar med antalet variabler. Alternativ (iii) stämmer inte bra. Värdena skall inte vara gynnsamma utan kriterierna skall användas (högst justerad förklaringsgrad eller lägsta godkända värde på C) Alternativ (iv) är tvärt emot vad kriterierna säger Alternativ (v) är nonsens. Sådana kriterier finns inte..")
27
Indexen Beräkning av index brukar ofta upplevas som “jobbigt”! Det finns inga genvägar utan det gäller att behärska formlerna och inse vad man gör. Exempel på uppgift ni förväntas kunna lösa (Övningstentan, uppgift 3) Ett företag säljer golv och färg. Man vill beräkna ett prisindex som speglar företagets prisutveckling på kort sikt och väljer därför ut representantvaror för de två varugrupperna. Följande data har sammanställts: År Varugrupp Golv Färg Totalt Pris, representantvara försäljningsvärde 2003 350 92 280 140 200438095 300 140 2005 340 97 300 145 Beräkna ett sammansatt kedjeprisindex av Laspeyre-typ för företagets priser. Ange indexv ärdena för 2003, 2004 och 2005. (1p)
 Ett företag säljer golv och färg. Man vill beräkna ett prisindex som speglar företagets prisutveckling på kort sikt och väljer därför ut representantvaror för de två varugrupperna. Följande data har sammanställts: År Varugrupp Golv Färg Totalt Pris, representantvara försäljningsvärde Beräkna ett sammansatt kedjeprisindex av Laspeyre-typ för företagets priser. Ange indexv ärdena för 2003, 2004 och (1p).")
28
Svarsalternativen i facit är följande: (a) 100.0, 105.0, 106.1 (b) 100.0, 101.5, 104.4 (c) 100.0, 101.8, 104.6 (d) 100.0, 101.8, 102.8 (e) 100.0, 105.0, 101.1 (f) 100.0, 101.5, 102.9 Alternativ (c) är det korrekta. Övriga alternativ uppstår om man blandar ihop vad som är försäljningsvärden och priser, om man använder länkarna som index etc. Avrundningsfel kan inte ge ett av de andra svarsalternativen. Sådant kollas alltid noggrant när alternativen skapas!

29
Elasticitetsmodellerna och de exponentiella modellerna “Knäcknöten” är logaritmerandet. I elasticitetsmodellerna står förklaringsvariabeln/variablerna i basen/baserna och parametern/parametrarna i exponenten/exponenterna (som tidigare används 10-logaritmen lg här för att inte komplicera saker och ting): Modell i originalskala Logaritmerad modell Räknande “för hand” kan bara göras i modeller med en förklaringsvariabel Då kan allt användas från enkel linjär regression
: Modell i originalskala Logaritmerad modell Räknande för hand kan bara göras i modeller med en förklaringsvariabel Då kan allt användas från enkel linjär regression.")
30
Exempel Modellen analyseras genom att tillämpa enkel linjär regression på det logaritmerade sambandet I formlerna ersätts därför y med log y och x med log x. I den logaritmerade modellen ingår 1 på samma sätt som i en enkel regression, dvs. framför det som utgör x-variabel 0 ingår dock inte på samma sätt som i enkel linjär regression utan i logaritmerad form.

31
Exempel på uppgift ni förväntas kunna lösa (Övningstentan, uppgift 4) Man har anpassat en modell där efterfrågan, Q av en viss vara förklaras av en prisvariabel, P. Såväl Q som P har justerats för inflationseffekter. Modellen är följande: där E P är priselasticiteten och är en slumpvariabel. Nedanstående Minitab-analys har genomförts: The regression equation is lg(Q) = 4.54 - 1.58 lg(P) Predictor Coef SE Coef T P Constant 4.5370 0.8814 5.15 0.000 lg(P) -1.5764 0.4355 -3.62 0.002 S = 0.0166237 R-Sq = 42.1% R-Sq(adj) = 38.9% Analysis of Variance Source DF SS MS F P Regression 1 0.0036214 0.0036214 13.10 0.002 Residual Error 18 0.0049743 0.0002763 Total 19 0.0085957 Testa på 5% nivå H 0 : E P −1 mot H 1 : E P > −1. Ange teststorhetens värde samt om H 0 förkastas eller ej.
 = lg(P) Predictor Coef SE Coef T P Constant lg(P) S = R-Sq = 42.1% R-Sq(adj) = 38.9% Analysis of Variance Source DF SS MS F P Regression Residual Error Total Testa på 5% nivå H 0 : E P −1 mot H 1 : E P > −1. Ange teststorhetens värde samt om H 0 förkastas eller ej..")
32
Den logaritmerade modellen som analyserats är Det innebär att det skattade värdet (b 1 ) i utskriften, dvs. –1.5764 är skattningen av E P (alltså inte något logaritmerat värde). Däremot går det inte att använda den beräknade T-kvoten i utskriften, för den gäller ju ett test av hypotesen H 0 : E P = 0 och det är inte den hypotesen vi testar. Den testvariabel vi behöver för att testa H 0 : E P −1 mot H 1 : E P > −1 beräknas som Jfr. Formelsamlingen, sid. VI. B är i detta fall = –1. (Där skrivs ”log” istället för ”lg” men det har ingen betydelse.) Här behöver vi dock inte manuellt beräkna nämnaren. Den fås ur utskriften under kolumnen ”SE Coef”. Notera att denna inte påverkas av vilket B som sätts in i formeln! Predictor Coef SE Coef Constant 4.5370 0.8814 lg(P) -1.5764 0.4355 Frihetsgraderna är 18 och testet är enkelsidigt. Tabellvärdet blir därför 1.73 (kolumnen 0.90 i tabellen) –1.32 > –1.73 H 0 förkastas ej!
. Däremot går det inte att använda den beräknade T-kvoten i utskriften, för den gäller ju ett test av hypotesen H 0 : E P = 0 och det är inte den hypotesen vi testar. Den testvariabel vi behöver för att testa H 0 : E P −1 mot H 1 : E P > −1 beräknas som Jfr. Formelsamlingen, sid. VI. B är i detta fall = –1. (Där skrivs log istället för lg men det har ingen betydelse.) Här behöver vi dock inte manuellt beräkna nämnaren. Den fås ur utskriften under kolumnen SE Coef . Notera att denna inte påverkas av vilket B som sätts in i formeln. Predictor Coef SE Coef Constant lg(P) Frihetsgraderna är 18 och testet är enkelsidigt. Tabellvärdet blir därför 1.73 (kolumnen 0.90 i tabellen) –1.32 > –1.73 H 0 förkastas ej!.")
33
Svarsalternativen i facit är följande: 1. Testvariabelns värde= –3.62, H 0 förkastas ej 2. Testvariabelns värde=5.15, H 0 förkastas ej 3. Testvariabelns värde= – 1.32, H 0 förkastas ej 4. Testvariabelns värde=6.28, H 0 förkastas 5. Testvariabelns värde= – 3.62, H 0 förkastas 6. Testvariabelns värde=13.10, H 0 förkastas Alternativ 3 är alltså det korrekta. Värdet –3.62 är T-kvoten i utskriften, som alltså inte är korrekt att använda. Övriga värden är mer långsökta. Värdet 5.15 är T-kvoten i utskriften för konstanten, som inte har med detta att göra. Övriga alternativ är mer långsökta.

34
I de exponentiella modellerna står parametern/parametrarna i basen/baserna och förklaringsvariabeln/variablerna i exponenten/exponenterna. Modell i originalskala Logaritmerad modell Räknande “för hand” kan bara göras i modeller med en förklaringsvariabel Då kan allt användas från enkel linjär regression

35
Exempel Modellen analyseras genom att tillämpa enkel linjär regression på det logaritmerade sambandet: I formlerna ersätts därför y med log y men x logaritmeras inte. I det logaritmerade sambandet ingår parametrarna 0 och 1 i logaritmerad form.

36
Exempel på uppgift om exponentiella modeller ni förväntas kunna lösa (ej ingående i övningstentan) 4. Ett okänt belopp placerades för länge sedan i en intressant fond och har behållits i denna. För att skatta avkastningen på fonden mellan åren 1990 och 2004 införs en parameter, r och man antar att modellen v t = v 0 · (1 + r) t−1989 t Gäller, där v t är värdet år t, v 0 är det förväntade värdet år 1989 och t är en slumpstörning sådan att lg är N(0, ). För befintliga data över värdena de aktuella åren har följande analyser gjorts i Minitab.
 t−1989 t Gäller, där v t är värdet år t, v 0 är det förväntade värdet år 1989 och t är en slumpstörning sådan att lg är N(0, ). För befintliga data över värdena de aktuella åren har följande analyser gjorts i Minitab..")
37
Regression Analysis: v versus (t-1989) The regression equation is v = 167 + 21.5 (t-1989) Predictor Coef SE Coef T P Constant 167.15 18.43 9.07 0.000 (t-1989) 21.497 2.027 10.61 0.000 S = 33.91 R-Sq = 89.6% R-Sq(adj) = 88.8% Regression Analysis: v versus lg(t-1989) The regression equation is v = 133 + 255 lg(t-1989) Predictor Coef SE Coef T P Constant 133.00 37.68 3.53 0.004 lg(t-1989) 255.18 43.21 5.90 0.000 S = 54.91 R-Sq = 72.8% R-Sq(adj) = 70.8%
 The regression equation is v = (t-1989) Predictor Coef SE Coef T P Constant (t-1989) S = R-Sq = 89.6% R-Sq(adj) = 88.8% Regression Analysis: v versus lg(t-1989) The regression equation is v = lg(t-1989) Predictor Coef SE Coef T P Constant lg(t-1989) S = R-Sq = 72.8% R-Sq(adj) = 70.8%")
38
Regression Analysis: lg(v) versus (t-1989) The regression equation is lg(v) = 2.29 + 0.0276 (t-1989) Predictor Coef SE Coef T P Constant 2.29163 0.01823 125.72 0.000 (t-1989) 0.027639 0.002005 13.79 0.000 S = 0.03355 R-Sq = 93.6% R-Sq(adj) = 93.1% Regression Analysis: lg(v) versus lg(t-1989) The regression equation is lg(v) = 2.23 + 0.344 lg(t-1989) Predictor Coef SE Coef T P Constant 2.23463 0.03666 60.95 0.000 lg(t-1989) 0.34430 0.04205 8.19 0.000 S = 0.05343 R-Sq = 83.8% R-Sq(adj) = 82.5% Skatta på lämpligt sätt parametern r och testa på 5% nivå H 0 : r > 0. Svara med det skattade värdet samt om testet är signifikant eller ej. (1p)
.")
39
Modellen är en exponentiell modell. Den beroende variabeln är i detta fall v t och förklaringsvariabeln är t eller t – 1989. Att man här har valt att dra bort 1989 är för att få en naturlig koppling till “nollan” i v 0. År 1989 blir här alltså år 0, den tidpunkt som motsvarar grundkapitalet. För att kunna analysera med regressionsanalys måste vi logaritmera modellen: I en regressionsanalys skall alltså lg v utgöra y-variabeln och t – 1989 x-variabeln. Det blir därför den tredje av de fyra Minitab-analyserna som skall användas. Från den kan vi avläsa skattad lutningsparameter (dvs. tillfällig b 1 ): 0.027639 Genomsnittlig avkastning skattas alltså till c:a 6.6%
: Genomsnittlig avkastning skattas alltså till c:a 6.6%.")
40
För att kunna testa H 0 : r > 0 krävs att vi omformar hypotesen så att den istället gäller för lg(1+r). r > 0 blir detsamma som att 1 + r > 1 vilket blir detsamma som att lg(1+r) > 0. Vi kan alltså direkt från analysen använda den beräknade t-kvoten (eftersom den just handlar om lg(1+r). T är 13.79. Vi ser på P-värdet att den är signifikant, men observera att detta P- värde gäller för en dubbelsidig mothypotes, dvs. för hypotesparet H 0 : lg(1+r) = 0 H a : lg(1+r) 0 Vad blir skillnaden med en enkelsidig mothypotes? 1)Kolla först så att själva värdet på T-kvoten är positivt. Det är det i detta fall, men om det skulle ha varit negativt har vi inget bevis för att lg(1+r) är större än noll. 2) Om det dubbelsidiga testet är signifikant så är även det enkelsidiga det (förutsatt att testvariabeln är positiv, vilket den alltså är)
 > 0. Vi kan alltså direkt från analysen använda den beräknade t-kvoten (eftersom den just handlar om lg(1+r). T är Vi ser på P-värdet att den är signifikant, men observera att detta P- värde gäller för en dubbelsidig mothypotes, dvs. för hypotesparet H 0 : lg(1+r) = 0 H a : lg(1+r) 0 Vad blir skillnaden med en enkelsidig mothypotes. 1)Kolla först så att själva värdet på T-kvoten är positivt. Det är det i detta fall, men om det skulle ha varit negativt har vi inget bevis för att lg(1+r) är större än noll. 2) Om det dubbelsidiga testet är signifikant så är även det enkelsidiga det (förutsatt att testvariabeln är positiv, vilket den alltså är).")
41
Den här uppgiften är förstås aningen svårare, men räkna med att det kan finnas en och annan “kluring” med. Felaktiga svarsalternativ på denna uppgift skulle utgöras av svar där man använd resultat från de andra Minitab-anayserna, kombinerade med olika slutsatser om signifikansen.

42
Tidsserieanalysen Mycket av detta examineras genom inlämningsuppgiften. Det handlar om att lära sig använda modeller för tidsserieregression och klassisk komponentuppdelning samt exponentiella utjämningsmetoder för prognoser. Själva räknandet görs dock uteslutande med datorns hjälp. Visst hum om stationaritet och ARMA-modeller ingår också, men ingen kunskap om hur man räknar förutsätts. För att få den totala examinationen individuell finns en uppgift med på tentan. Den brukar vara värd max. 1.5 poäng. Denna kan handla om att kunna tolka en utskrift från tidsserieregression eller klassisk komponentuppdelning kunna tolka en utskrift från enkel eller dubbel exponentiell utjämning eller Winters’ metod kunna för hand beräkna en prognos med hjälp av skattade komponenter från en komponentuppdelning kunna besvara diverse teorifrågor runt tidsserieanalys

43
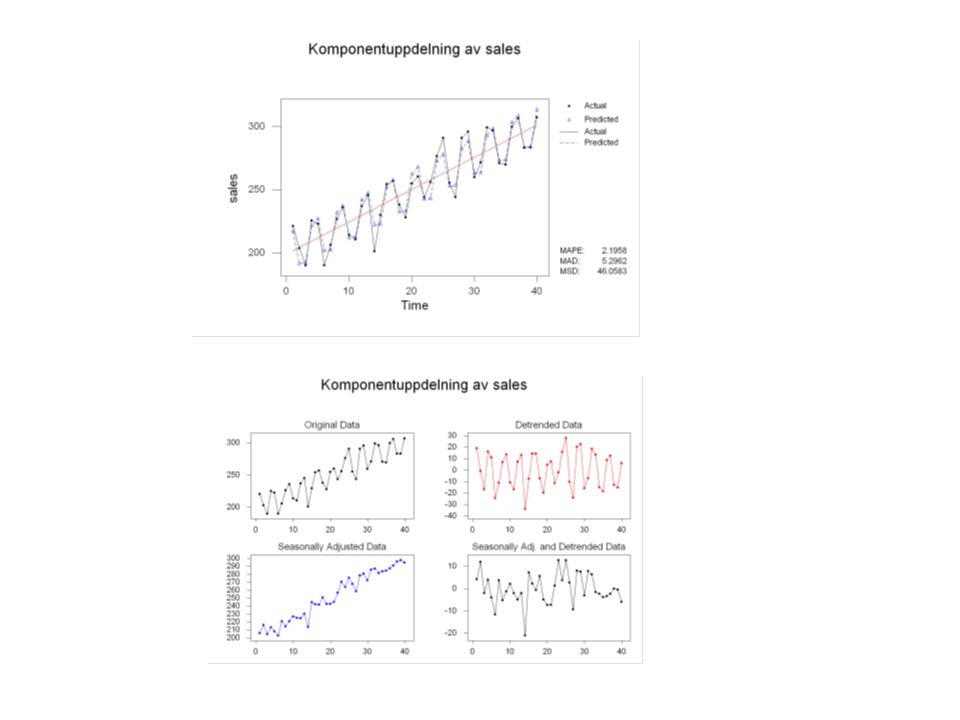
Exempel på uppgift ni förväntas kunna lösa (Övningstentan, uppgift 5) Nedanstående diagram visar kvartalsvisa försäljningsvärden 1985–1994 hos ett företag, som säljer vintersportartiklar. Man har gjort en analys med Minitab och bl a fått följande resultat: Time Series Decomposition Data sales Length 40.0000 NMissing 0 Trend Line Equation Yt = 199.017 + 2.55586*t Seasonal Indices Period Index 1 15.1719 2 -12.7031 3 -14.7031 4 12.2344 Accuracy of Model MAPE: 2.1958 MAD: 5.2962 MSD: 46.0583

45
a) Vilken av följande tolkningar rörande de skattade säsongkomponenterna är korrekt? (i) Försäljningen i första kvartalet är i genomsnitt c:a 15 enheter högre än trendnivån. (ii) Försäljningen i första kvartalet är i genomsnitt c:a 15% högre än trendnivån. (iii) Försäljningen under april-september ligger i genomsnitt drygt 13% under årsgenomsnittet. (iv) Försäljningen i fjärde kvartalet ligger i genomsnitt c:a 3% under försäljningen i det första kvartalet. (v) Försäljningen i fjärde kvartalet ligger i genomsnitt c:a 12 enheter över genomsnittet under perioden 1985–1994. (vi) Försäljningen i fjärde kvartalet ligger i genomsnitt c:a 12 procent över genomsnittet under perioden 1985–1994. (0.5p) Seasonal Indices Period Index 1 15.1719 2 -12.7031 3 -14.7031 4 12.2344 Den modell som anpassats är additiv. Detta syns på att säsongskomponenterna varierar runt 0. Säsongskomponenterna skall därför tolkas som avvikelser i enheter och inte i %. Vidare tolkas alltid säsongskomponenter som avvikelse från trendnivån i en komponentupp- delningsmodell. Alternativ (i) är korrekt, övriga är felaktiga.
 Försäljningen i första kvartalet är i genomsnitt c:a 15 enheter högre än trendnivån. (ii) Försäljningen i första kvartalet är i genomsnitt c:a 15% högre än trendnivån. (iii) Försäljningen under april-september ligger i genomsnitt drygt 13% under årsgenomsnittet. (iv) Försäljningen i fjärde kvartalet ligger i genomsnitt c:a 3% under försäljningen i det första kvartalet. (v) Försäljningen i fjärde kvartalet ligger i genomsnitt c:a 12 enheter över genomsnittet under perioden 1985–1994. (vi) Försäljningen i fjärde kvartalet ligger i genomsnitt c:a 12 procent över genomsnittet under perioden 1985–1994. (0.5p) Seasonal Indices Period Index Den modell som anpassats är additiv. Detta syns på att säsongskomponenterna varierar runt 0. Säsongskomponenterna skall därför tolkas som avvikelser i enheter och inte i %. Vidare tolkas alltid säsongskomponenter som avvikelse från trendnivån i en komponentupp- delningsmodell. Alternativ (i) är korrekt, övriga är felaktiga..")
46
b) Beräkna prognoser av försäljningsvärdena för kvartal 1 och 2 år 1995. (1p) Använd skattad trendfunktion och säsongskomponent för respektive kvartal. Tidpunkterna som de två kvartalen motsvarar är 41 och 42. Detta kan inses direkt från utskriften (man behöver inte räkna alla kvartal från 1985 till 1994) Time Series Decomposition Data sales Length 40.0000 NMissing 0 Trend Line Equation Yt = 199.017 + 2.55586*t Seasonal Indices Period Index 1 15.1719 2 -12.7031 3 -14.7031 4 12.2344 Prognoserna blir Kvartal 1, 1995: Kvartal 2, 1995:
 Använd skattad trendfunktion och säsongskomponent för respektive kvartal. Tidpunkterna som de två kvartalen motsvarar är 41 och 42. Detta kan inses direkt från utskriften (man behöver inte räkna alla kvartal från 1985 till 1994) Time Series Decomposition Data sales Length NMissing 0 Trend Line Equation Yt = *t Seasonal Indices Period Index Prognoserna blir Kvartal 1, 1995: Kvartal 2, 1995:.")
47
Svarsalternativen i facit är följande: 1. 319.0, 293.7 2. 303.8, 306.4 3. 349.9, 267.4 4. 316.7, 291.4 5. 242.3, 214.4 6. 261.6, 198.3 Alternativ 1 är det korrekta. Alternativ 2 fås om man glömmer säsongskomponenterna Alternativ 3 fås om man tror att säsongskomponenterna är i % och alltså multiplicerar trendskattningen med 1.151719 resp. med (1 – 0.127031) Övriga alternativ är mer långsökta.
 Övriga alternativ är mer långsökta..")
48
c) Vilket av följande påståenden är sant? (i) Diagrammet med rubrik “Seasonally Adjusted Data” i figur 3 innehåller enbart information om trend- och slumpkomponent (ii) I diagrammet med rubrik “Seasonally Adj. and Detrended Data” i figur 3 kan man se om det kan finnas någon cyklisk variation i data. (iii) I diagrammet med rubrik “Detrended Data” i figur 3 finns enbart information om säsongkomponent. (iv) Diagrammet (och dess bakomliggande värden) med rubrik “Seasonally Adjusted Data” i figur 3 är det som används för att beräkna prognoser av framtida värden. (v) Diagrammet med rubrik “Seasonally Adj. and Detrended Data” i figur 3 visar på en svagt nedåtgående trend i originaldata, som är dold av säsongsvariationen i diagrammet över originaldata. (vi) Inget av diagrammen i figur 3 ger någon information om slumpkomponenten. (0.5p) Alternativ (ii) är sant. Alternativ (i) stämmer inte då man aldrig kan bortse från cyklisk variation. Alternativ (iii) stämmer inte då information om såväl cyklisk som oregelbunden komponent finns där. Alternativ(iv) är nonsens. Alternativ (v) är inte korrekt eftersom såväl säsong som trend är bortrensad Alternativ (vi) stämmer inte. Information om denna finns i alla diagram.
 Diagrammet med rubrik Seasonally Adjusted Data i figur 3 innehåller enbart information om trend- och slumpkomponent (ii) I diagrammet med rubrik Seasonally Adj. and Detrended Data i figur 3 kan man se om det kan finnas någon cyklisk variation i data. (iii) I diagrammet med rubrik Detrended Data i figur 3 finns enbart information om säsongkomponent. (iv) Diagrammet (och dess bakomliggande värden) med rubrik Seasonally Adjusted Data i figur 3 är det som används för att beräkna prognoser av framtida värden. (v) Diagrammet med rubrik Seasonally Adj. and Detrended Data i figur 3 visar på en svagt nedåtgående trend i originaldata, som är dold av säsongsvariationen i diagrammet över originaldata. (vi) Inget av diagrammen i figur 3 ger någon information om slumpkomponenten. (0.5p) Alternativ (ii) är sant. Alternativ (i) stämmer inte då man aldrig kan bortse från cyklisk variation. Alternativ (iii) stämmer inte då information om såväl cyklisk som oregelbunden komponent finns där. Alternativ(iv) är nonsens. Alternativ (v) är inte korrekt eftersom såväl säsong som trend är bortrensad Alternativ (vi) stämmer inte. Information om denna finns i alla diagram..")
Liknande presentationer














>")



>")
