Ladda ner presentationen
Presentation laddar. Vänta.

1
y=β0 + β1·x1 + β2·x2 + β3·x3 + β4·x4 + β5·x32 + ε
Om sambandet inte är linjärt? Om sambandet till en variabel inte är linjärt så kan vi inkludera ytterligare en term i regressionsmodellen I en modell med alla förklaringsvariabler inkluderade: y=β0 + β1·x1 + β2·x2 + β3·x3 + β4·x4 + β5·x32 + ε Intercept Area Acres Rooms Baths Rooms Felterm Den nya variabeln är alltså antal rum i kvadrat och har ingen praktisk tolkning, men vi kan genomföra en analys där vi förväntar oss ett högt pris om fastigheten har lagom många rum.

2
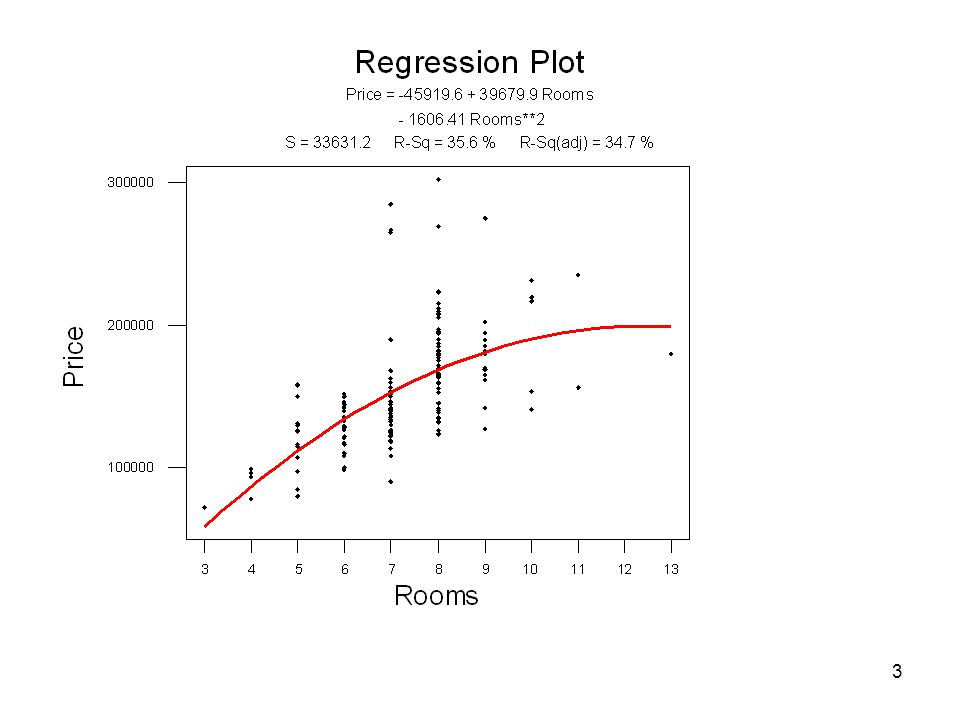
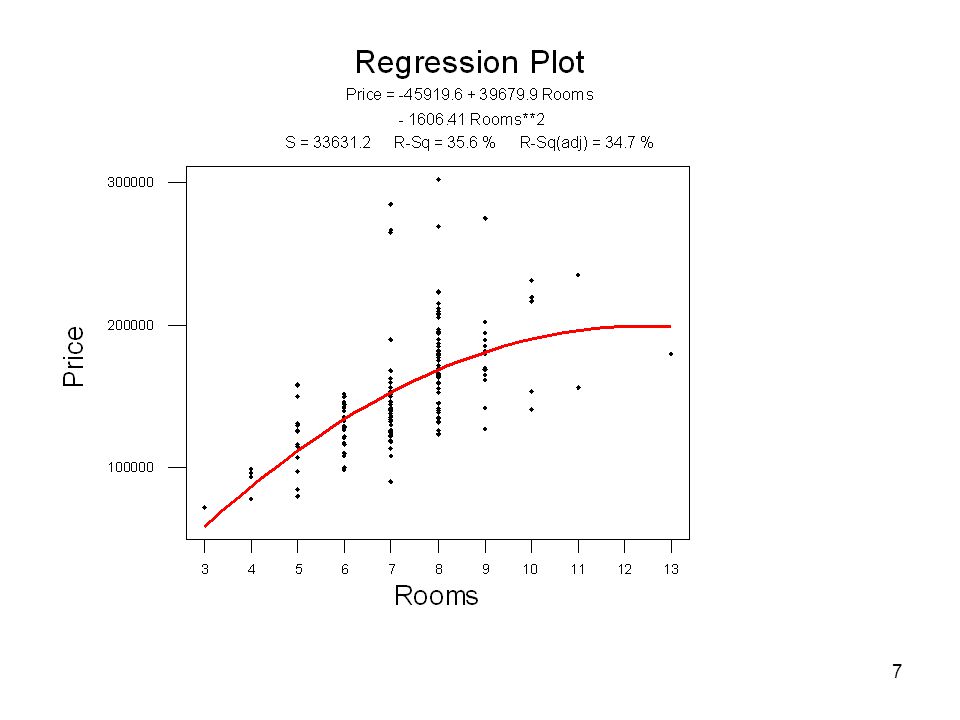
Pris mot antal rum

4
y=β0 + β3·x3 + β5·x32 + ε Vi använder en kvadratisk term i modellen:
men vi behåller även originalvariabeln (alltså x3) för att göra modellen mer flexibel.
 för att göra modellen mer flexibel.")
5
Regression Analysis: Price versus Rooms
The regression equation is Price = Rooms Predictor Coef SE Coef T P Constant , ,007 Rooms , ,000 S = R-Sq = 33,2% R-Sq(adj) = 32,8%
 = 32,8%")
6
parametern b5 är negativ: den anpassade funktionen har ett maximum
Regression Analysis: Price versus Rooms, Rooms_sq The regression equation is Price = Rooms Rooms_sq Predictor Coef SE Coef T P Constant Rooms Rooms_sq S = R-Sq = 35.6% R-Sq(adj) = 34.7% parametern b5 är negativ: den anpassade funktionen har ett maximum båda signifikanta
 = 34.7% parametern b5 är negativ: den anpassade funktionen har ett maximum. båda signifikanta.")
8
Om parametern b5 är positiv skulle vi istället ha en funktion som visar ett minimum.
Jämfört med en regression där alla termer är linjära är parametrarna i en kvadratisk regression svårare att tolka. I modellen y=b0 + b3·x3 + ε kan vi säga att priset för fastigheten ökar med b3 USD för varje ytterligare rum. I modellen y=b0 + b3·x3 + b5·x32 + ε ökar priset för fastigheten med varje ytterligare rum, men bara upp till ett visst antal rum, sen minskar priset.

9
Komplexa samband mellan en förklarande variabel och en responsvariabel kan alltså tas med i modellen genom kvadratiska eller även kubiska termer (x3). Samtidigt måste man fundera på om det verkligen är den här variablen själv som har ett krökt samband till priset eller om det istället är en samspel variabeln ‘antal rum’ och andra förklarande variabler: en liten fastighet med många rum eller en stor fastighet med få rum.....

10
Interaktionstermer – samspelstermer
Vi bildar då nya variabeln x1·x3 och analyserar modellen y=β0 + β1·x1 + β3·x3 + β5·x32 + β6 ·x1·x3 + ε bostadsyta antal rum (antal rum) bostadsyta*antal rum
2 bostadsyta*antal rum.")
11
Regression Analysis: Price versus Area; Rooms; Rooms_sq
The regression equation is Price = ,3 Area Rooms Rooms_sq Predictor Coef SE Coef T P Constant , ,647 Area , , , ,000 Rooms , ,020 Rooms_sq , , , ,014 S = R-Sq = 50,7% R-Sq(adj) = 49,6%
 = 49,6%")
12
Samspelstermen har tagit över den kvadratiska termens roll.
The regression equation is Price = Area Rooms Rooms_sq Area*Rooms Predictor Coef SE Coef T P Constant Area Rooms Rooms_sq Area*Roo S = R-Sq = 53.4% R-Sq(adj) = 52.2% Samspelstermen har tagit över den kvadratiska termens roll.
 = 52.2% Samspelstermen har tagit över den kvadratiska termens roll.")
13
Regression Analysis: Price versus Area; Rooms; Area*Roo
The regression equation is Price = Area Rooms - 7,32 Area*Roo Predictor Coef SE Coef T P Constant , ,330 Area , , , ,000 Rooms , ,008 Area*Roo , , , ,001 S = R-Sq = 52,7% R-Sq(adj) = 51,7%
 = 51,7%")
14
1... upp till 5 rum; 2... mellan 6 och 8 rum; 3...mer än 8 rum

15
Regressionslinjen som bekriver sambandet mellan priset och bostadsytan är beroende på hur många rum det finns i huset. I regressionsanalysen för detta datamaterial kan vi alltså ersätta den kvadratiska termen för antal rum med en samspelsterm (bostadsyta * antal rum). Modellen är då: y=β0 + β1·x1 + β3·x3 + β6 ·x1·x3 + ε De motsvarande linjära termerna (x1 och x2) behåller vi vanligtvis också i modellen.
. Modellen är då: y=β0 + β1·x1 + β3·x3 + β6 ·x1·x3 + ε. De motsvarande linjära termerna (x1 och x2) behåller vi vanligtvis också i modellen.")
16
Kvalitativa variabler
inga numeriskt tolkningsbara värden utan värden som är koder för olika klasser av observationer. Ett exempel är en variabel för kön, som kan anta värdet man eller kvinna En sådan variabel skulle man kunna koda som 0 för män och 1 för kvinnor och därmed använda i en regressionsanlays Ett annat exempel är en variabel som är 1 för småföretag, 2 för mellanstora företag och 3 för stora företag.

17
För att kunna använda sådana kvalitativa variabler i regressionsanalysen krävs att de görs om till s k indikatorvariabler eller dummyvariabler. (Andra namn är 0/1-variabler resp. dikotoma variabler) Om vi inför en kodning 0 för män och 1 för kvinnor så har vi redan en indikatorvariabel som direkt kan användas. I fallet där vi kodar företagen, måste vi skapa flera nya variabler: en som är 1 om företaget är liten och 0 annars en som är 1 om företaget är mellanstor och 0 annars Den tredje variabel som vi kunde skapa (1 om stor, 0 annars) får inte vara med i analysen.
 får inte vara med i analysen.")
18
Alltså: Företag Företagstyp Ursprunglig kod D1 D2 1 Liten 2 Mellanstor 3 Stor 4 5 Grundregel: Om den kvalitativa variabeln har m olika koder eller värden (kallas också nivåer) skall m1 indikatorvariabler användas.
 skall m1 indikatorvariabler användas.")
19
Minitab har funktioner för att
manuellt koda om en variabels värden till andra värden skapa indikatorvariabler för att ersätta en kvalitativ variabel

20
I datamaterialet med fastighetspriser skulle vi kunna koda om variabeln ’antal rum’ på följande sätt: fastigheter med högst 6 rum fastigheter med fler än 6 rum För att göra detta kan vi skapa en indikatorvariabel som är =0 för fastigheter med högst 6 rum och 1 för övriga, dvs

21
bostadsyta dummy som är 1 om fastigheten har mer än 6 rum
Nu kan vi använda denna indikatorvariabel (dummy) istället för originalvariabeln. y=β0 + β1·x1 + β7·D + ε bostadsyta dummy som är 1 om fastigheten har mer än 6 rum Regression Analysis: Price versus Area, D The regression equation is Price = Area D Predictor Coef SE Coef T P Constant Area D S = R-Sq = 49.3% R-Sq(adj) = 48.6%
 istället för originalvariabeln. y=β0 + β1·x1 + β7·D + ε. bostadsyta dummy som är 1 om fastigheten har mer än 6 rum. Regression Analysis: Price versus Area, D. The regression equation is. Price = Area D. Predictor Coef SE Coef T P. Constant Area D S = R-Sq = 49.3% R-Sq(adj) = 48.6%")
22
Predictor Coef SE Coef T P
Constant Area D Om man ignorerar att dummyvariabeln D inte är signifikant så går det att tolka modellen på följande sätt. Varje fastighet som har 7 rum eller fler får ett försäljningspris som är USD högre än jämförbar fastighet med färre rum. Med D=1: Med D=0:

23
Parallella linjer, men skillnad i y-nivån

24
Eftersom vi såg förut att en samspelsterm (för interaktioner mellan bostadsyta och antal rum) verkar vara bra, kan vi lägger till en sådan även nu. y=β0 + β1·x1 + β7·D + β8·x1·D + ε Regression Analysis: Price versus Area, D, Area*D The regression equation is Price = Area D Area*D Predictor Coef SE Coef T P Constant Area D Area*D S = R-Sq = 93.3% R-Sq(adj) = 93.2% Samtliga variabler är signifikanta och förklaringsgraden är mycket bra.
 = 93.2% Samtliga variabler är signifikanta och förklaringsgraden är mycket bra.")
25
Hur blir nu tolkningen av denna modell?
Predictor Coef SE Coef T P Constant Area D Area*D Hur blir nu tolkningen av denna modell? Vi måste återigen skilja på de två fallen med D=0 och D=1. Med D = 1 Med D = 0

26
I detta fall får vi alltså två regressionslinjer som skiljer sig i både y-nivån (intercept) och lutningen. Högst 6 rum: Priset ökar med i genomsnitt 7454 dollar då bostadsytan ökar med 1000 ft2 7 eller fler rum: Priset ökar med i genomsnitt 8403 dollar då bostadsytan ökar med 1000 ft2

27
Det finns ett samband mellan dummyvariabeln (fler än 6 rum eller ej) och bostadsytan. Regressionslinjernas lutningar är olika.

28
Om vi har fler än 2 grupper behöver vi fler dummy variabler.
t.ex. grupp 1: 0-4 rum grupp 2: 5-8 rum grupp 3: 8:10 rum grupp 4: 11- rum Vi skapar 3 dummy variabler: antal rum D1 D2 D3 3 1 6 10 8 13

29
Ibland kan vi även arbeta med en annan kodning:
t.ex. grupp 1: 0-4 rum 1 grupp 2: 5-8 rum 2 grupp 3: 8-10 rum 3 grupp 4: 11- rum 4 men detta är bara möjligt om man kan anta att effekten (prisökningen) är samma när man går över från grupp 1 till grupp 2, som när man går över från grupp 2 till grupp 3, osv.
 är samma när man går över från grupp 1 till grupp 2, som när man går över från grupp 2 till grupp 3, osv.")
30
Partiellt F-test Vi har nu en modell för fastighetspriset som använder sig av följande förklarande variabler: bostadsyta (area) antal rum (rooms) samspelsterm (area*rooms) Dessutom har vi sett att även tomtyta har betydelse. För den sista förklarande variabeln som är tillgänglig (antal badrum) skulle vi kunna anta att den beter sig som variabeln ‘antal rum’. Vi skulle därför kunna använda oss av själva variabeln, men också inkludera en samspelsterm (area*baths).
 antal rum (rooms) samspelsterm (area*rooms) Dessutom har vi sett att även tomtyta har betydelse. För den sista förklarande variabeln som är tillgänglig (antal badrum) skulle vi kunna anta att den beter sig som variabeln ‘antal rum’. Vi skulle därför kunna använda oss av själva variabeln, men också inkludera en samspelsterm (area*baths).")
31
The regression equation is
Price = Area Acres Rooms Area*Rooms Baths Area*Baths Predictor Coef SE Coef T P Constant Area Acres Rooms Area*Roo Baths Area*Bat S = R-Sq = 70.9% R-Sq(adj) = 69.7% Förklaringsgraden är ganska bra, men ingen av variablerna som har med antal badrum att göra är signifikant på 5%-nivån.
 = 69.7% Förklaringsgraden är ganska bra, men ingen av variablerna som har med antal badrum att göra är signifikant på 5%-nivån.")
32
Analysis of Variance Source DF SS MS F P Regression E Residual Error Total E+11 Source DF Seq SS Area E+11 Acres Rooms Area*Roo Baths Area*Bat F-testet anger att minst en av de ingående x-variablerna har betydelse. t-testen (på föreg. sida) visar att fyra variabler har det, men inte de två sista. Räcker det då med 4 förklarande variabler (area, acres, rooms, area*rooms)?
 visar att fyra variabler har det, men inte de två sista. Räcker det då med 4 förklarande variabler (area, acres, rooms, area*rooms)")
33
Alla variabler signifikanta, något lägre justerat R2-värde.
Vi kan köra regressionsanalysen en gång till och då lämna bort de två variablerna som inte var signifikanta. The regression equation is Price = Area Acres Rooms Area*Rooms Predictor Coef SE Coef T P Constant Area Acres Rooms Area*Roo S = R-Sq = 68.0% R-Sq(adj) = 67.1% Analysis of Variance Source DF SS MS F P Regression E Residual Error Total E+11 Alla variabler signifikanta, något lägre justerat R2-värde.
 = 67.1% Analysis of Variance. Source DF SS MS F P. Regression E Residual Error Total E+11. Alla variabler signifikanta, något lägre justerat R2-värde.")
34
Kan vi jämföra de två modellerna och bestämma om vi ska ha med antal badrum som förklarande variabel? Den fullständiga modellen kan skrivas: y= 0 + 1 · x1 2· x2 + 3· x3 + 5· x1x3 + 4· x4 + 6· x1x4 + där x1=area, x2=acres, x3=rooms, x4=baths och därmed x1x3 samspelet mellan ’area’ och ’rooms’, och x1x4 samspelet mellan ’area’ och ’baths’. Den reducerade modellen kan skrivas y= 0 + 1 · x1 2· x2 + 3· x3 + 5· x1x3 + Det är alltså den modellen, som vi tror kan räcka för att förklara fastighetspriset.

35
Vi vill nu testa om någon av de variabler som vi har tagit bort har (signifikant) betydelse för vilket värde responsvariabeln antar. Om vi vill testa om någon av x4 och x1x4 skall läggas till blir nollhypotesen: H0: 4= 6=0 Alternativhyptesen: H1: minst en av 4, 6 är skild från 0

36
Som testfunktion kan vi använda
där SSER=Residualkvadratsumman (SSE) i den Reducerade modellen och SSEC=Residualkvadratsumman i den Fullständiga modellen p-1=Antal förklaringsvariabler i den fullständiga modellen q-1=Antal förklaringsvariabler i den reducerade modellen Vi testar alltså om minskningen i residualkvadratsumman är så pass stor (när vi lägger till de två variablerna) att vi inte kan ignorera den.
 i den Reducerade modellen och SSEC=Residualkvadratsumman i den Fullständiga modellen. p-1=Antal förklaringsvariabler i den fullständiga modellen. q-1=Antal förklaringsvariabler i den reducerade modellen. Vi testar alltså om minskningen i residualkvadratsumman är så pass stor (när vi lägger till de två variablerna) att vi inte kan ignorera den.")
37
I vårt fall: Den reducerade modellen
Om H0 är sann får F en F-fördelning med k-g och n-k-1 frihetsgrader och vi kan alltså jämföra värdet på F med F[](k-g,n-k-1) I vårt fall: Den reducerade modellen Analysis of Variance Source DF SS MS F P Regression E Residual Error Total E+11 Den fulla modellen Regression E Residual Error SSER SSEF
 I vårt fall: Den reducerade modellen. Analysis of Variance. Source DF SS MS F P. Regression E Residual Error Total E+11. Den fulla modellen. Regression E Residual Error SSER. SSEF.")
38
F(0.05;2,143) 3.07 < 7.2296 H0 ska förkastas!
Fastän varken antal badrum eller samspelstermen bostadsyta/antal badrum var signifikant, finns det ändå information i minst en av variablerna.

39
Testmetoden kallas Partiellt F-test eftersom vi i ett test testar om en del (partition) av modellen skall uteslutas. Om vi bara vill testa en enda variabel (om den ska uteslutas eller ej), så är det partiella F-testet ekvivalent med t-testet för denna variabel.
, så är det partiella F-testet ekvivalent med t-testet för denna variabel.")
40
Om vi kommer (som i det här fallet) till slutsatsen att det finns information i minst en variabel av alla de vi testade, så får vi gå vidare med att ta reda på vilken variabel det kunde vara. I vårt fall skulle vi kanske välja att ta bort samspelstermen area*baths och behålla variabeln baths. The regression equation is Price = Area Acres Rooms Area*Rooms Baths Predictor Coef SE Coef T P Constant Area Acres Rooms Area*Roo Baths S = R-Sq = 70.2% R-Sq(adj) = 69.2%
 = 69.2%")
41
I vissa fall kan vi förenkla beräkningen något:
Vi kan skriva: SSER –SSEF = SSRF –SSRR Det går alltså att använda regressionskvadratsummorna istället för residualkvadratsummorna.

42
SSRF=SSR(Area) + SSR(Acres | Area) + SSR(Rooms | Area, Acres) +
Analysis of Variance Source DF SS MS F P Regression E Residual Error Total E+11 Source DF Seq SS Area E+11 Acres Rooms Area*Roo Baths Area*Bat Vi kan då använda utskriften för enbart den kompletta modellen för att beräkna det partiella F-testet. SSRF=SSR(Area) + SSR(Acres | Area) + SSR(Rooms | Area, Acres) + + SSR(Area*Rooms | Area, Acres, Rooms ) + SSR(Baths | Area, Acres, Rooms, Area*Rooms) + SSR (Area*Baths | Area, Acres, Rooms, Area*Rooms, Baths) Observera ordningen! sekventiella regressionskvadratsummor
 + SSR(Acres | Area) + SSR(Rooms | Area, Acres) + + SSR(Area*Rooms | Area, Acres, Rooms ) + SSR(Baths | Area, Acres, Rooms, Area*Rooms) + SSR (Area*Baths | Area, Acres, Rooms, Area*Rooms, Baths) Observera ordningen! sekventiella regressionskvadratsummor.")
43
I den reducerade modellen blir:
SSRR= SSR(Area) + SSR(Acres | Area) + SSR(Rooms | Area, Acres) + SSR(Area*Rooms | Area, Acres,Rooms ) SSRF – SSRR= SSR(Baths | Area, Acres, Rooms, Area*Rooms) + + SSR(Area*Baths | Area, Acres, Rooms, Area*Rooms, Baths) Source DF Seq SS Area E+11 SSR(Area) Acres SSR(Acres|Area) Rooms SSR(Rooms|Area, Acres) Area*Roo SSR(Area*Rooms|Area, Acres, Rooms) Baths osv. Area*Bat SSRF-SSRR= = SSRR= E+11
 + SSR(Acres | Area) + SSR(Rooms | Area, Acres) + SSR(Area*Rooms | Area, Acres,Rooms ) SSRF – SSRR= SSR(Baths | Area, Acres, Rooms, Area*Rooms) + + SSR(Area*Baths | Area, Acres, Rooms, Area*Rooms, Baths) Source DF Seq SS. Area E+11 SSR(Area) Acres SSR(Acres|Area) Rooms SSR(Rooms|Area, Acres) Area*Roo SSR(Area*Rooms|Area, Acres, Rooms) Baths osv. Area*Bat SSRF-SSRR= = SSRR= E+11.")
Liknande presentationer




 5. Problem med nedskräpning (fråga 1a) 6. Problem med skadegörelse (fråga 1b)>")














