Ladda ner presentationen
Presentation laddar. Vänta.

1
Hur bra är modellen som vi har anpassat?
Vi bedömer modellen med hjälp av ett antal kriterier: visuell bedömning, om möjligt p-värden för de individuella variablerna förklaringsgraden, R2 F-test, signifikanstest för hela regressionsmodellen Residualanalys, för att avgöra om regressionsantagandena är uppfyllda

2
Visuell bedömning:

3
Hur bra är modellen som vi har anpassat?
The regression equation is Hyra = Kv-meter Predictor Coef SE Coef T P Constant Kv-meter S = R-Sq = 85.5% R-Sq(adj) = 84.8% Analysis of Variance Source DF SS MS F P Regression Residual Error Total enskilda p-värden R2 och justerad R2 F-test och dess p-värde Residualanalys kan också göras i MINITAB
 = 84.8% Analysis of Variance. Source DF SS MS F P. Regression Residual Error Total enskilda p-värden. R2 och justerad R2. F-test och dess p-värde. Residualanalys kan också göras i MINITAB.")
4
Varför behöver vi så många olika mått på hur bra modellen är?
Om vi bara har en förklarande variabel, så spelar det inte så stor roll vilket mått vi använder: p-värden, R2 och F-test är i princip utbytbara. Residualanalys måste dock alltid genomföras. I de flesta fall kommer vi dock att ha modeller med mer än bara en förklarande variabel. Då är det viktigt att titta på de olika kriterierna var för sig, eftersom de ger olika information.

5
Vi har redan genomfört t-testet för de enskilda parametrarna (intercept och lutning) för att se om de är signifikant skilda från noll. Hur beräknas då R2 och F-testet? Båda är baserade på en jämförelse av hur mycket av variationen i responsvariabeln som kan förklaras genom modellen och hur mycket av variationen inte kan förklaras

6
Vi har redan räknat med ett mått för den oförklarade variationen: Residualkvadratsumman, som också ofta betecknas med SSE (Sum of Squared Errors). Ett mått på den totala variationen är också ganska enkelt att ta fram: variationen i responsvariabeln, SSyy, som i regressionssammanhang ofta kallas för SST (Totalkvadratsumman).
.")
7
För att göra kvadratsummeuppdelningen komplett kan vi beräkna SSR (Sum of Squares Regression), den förklarade variationen. SSR = SST - SSE eller SST = SSR + SSE Den totala variationen är summan av den (av modellen) förklarade variationen och den återstående variationen. SSR är den del av variationen som inte är slump, men kan förklaras av regressionssambandet.
 förklarade variationen och den återstående variationen. SSR är den del av variationen som inte är slump, men kan förklaras av regressionssambandet.")
8
Förklaringsgrad och korrelationskoefficient
Förklaringsgraden betecknas med R2 Ju högre förklaringsgrad, desto bättre lyckas vår skattade modell förklara variationen i data Modellen kan anses vara bra. I vårt exempel blev R2 = 85.5%, dvs. att 85.5% av all variation i data kan förklaras med hjälp av modellen.

9
Utvikning: Kom ihåg korrelationskoefficienten som mäter det linjära sambandet mellan x och y. I motsats till regressionsmodellen finns det i korrelationskoefficienten ingen kausalitet: regressionsmodellen: x påverkar y, men inte tvärtom korrelationskoefficienten: x och y hänger ihop

10
Korrelationskoefficienten ligger alltid mellan –1 och 1
Korrelationskoefficienten ligger alltid mellan –1 och 1. Om den är = – 1 eller = 1 säger man att det råder ett perfekt linjärt samband mellan y och x. Om r = 0 finns inget linjärt samband mellan y och x. (Det kan dock finnas andra samband, t.ex. kvadratiska) I vårt fall blir korrelationskoefficienten r=0.925 Observera att r2=(0.925)2=0.8556R2 Men detta gäller bara i fallet med en förklaringsvariabel, inte om vi inkluderar fler oberoende variabler i modellen.
 I vårt fall blir korrelationskoefficienten r= Observera att r2=(0.925)2=0.8556R2. Men detta gäller bara i fallet med en förklaringsvariabel, inte om vi inkluderar fler oberoende variabler i modellen.")
11
Vi kan pröva hypotesen:
H0: b1=0 mot H1: b1≠0 med ett F-test:

12
MSE har vi träffat på förut, men då kallade vi den för .
På MINITAB-utskriften kan vi hitta både MSE och . Om vi bara har en förklarande variabel, så är SSR/1=MSR. I vårt fall: Ur tabellen signifikant

13
F är ett mått på hur stor den förklarade variationen är jämfört med den oförklarade.
Om F är stor då har vi en bra modell som kan förklara mycket och lämnar lite oförklarat. Om vi bara har en förklarande variabel i modellen, så är F = t2 där t kommer från t-testet, när man testar om .

14
SSR MSR F-test MSE SSE SST The regression equation is
Hyra = Kv-meter Predictor Coef SE Coef T P Constant Kv-meter S = R-Sq = 85.5% R-Sq(adj) = 84.8% Analysis of Variance Source DF SS MS F P Regression Residual Error Total SSR MSR F-test MSE SSE SST
 = 84.8% Analysis of Variance. Source DF SS MS F P. Regression Residual Error Total SSR. MSR. F-test. MSE. SSE. SST.")
15
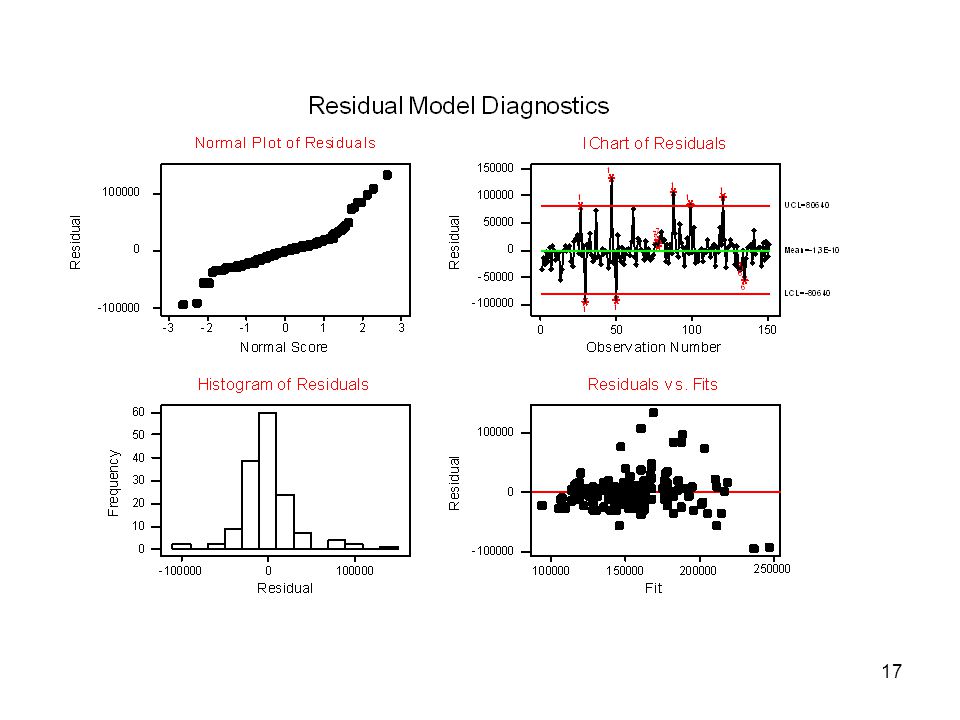
Residualanalys För att överhuvudtaget kunna ta resultaten av regressionsanalysen på allvar, måste vi undersöka om regressionsantagandena är uppfyllda. Har residualerna en konstant varians? Är residualerna normalfördelade? Är residualerna oberoende? Är alla samband linjära?

16
Har residualerna en konstant varians?
Plotta residualerna mot anpassade värden (residuals vs fits) Är residualerna normalfördelade? Histogram av residualerna Normalfördelningsdiagram av residualerna (Normal plot...) Är residualerna oberoende? Plotta residualerna i observationsordning (residuals vs order). Är alla samband linjära? Plotta residualerna mot enskilda förklarande variabler (Residuals vs the variables)
 Är residualerna normalfördelade Histogram av residualerna. Normalfördelningsdiagram av residualerna (Normal plot...) Är residualerna oberoende Plotta residualerna i observationsordning (residuals vs order). Är alla samband linjära Plotta residualerna mot enskilda förklarande variabler (Residuals vs the variables)")
Liknande presentationer
![78 respondenter. 2 [1] Hur har det varit hemma sedan du var här sist?](/7/1925646/big_thumb.jpg "78 respondenter. 2 [1] Hur har det varit hemma sedan du var här sist?>")
 November 2010 2010-10-22 Peter Blid Helena Björck Ida af Robson 2064.>")









>")


>")




