Ladda ner presentationen
Presentation laddar. Vänta.

1
Tidsserieanalys Vad karaktäriserar data? Exempel:
Observationerna är inte oberoende Observationerna ger ett mönster över tiden t ex stigande värden med tiden t ex periodisk variation över en tidsperiod av bestämd längd

2
Exempel på tidsseriedata
Olika typer av ekonomiska data: Arbetslöshetssiffror Försäljningsvärden Konsumentprisindex och andra index Export- och importmängder Miljömätdata: Fosforhalt i havsvattenbassänger Ozonhalt i luftrummet över en storstad

4
Modeller för tidsseriedata
Tidsserieregression: TRt står här för trendfunktionen i modellen

5
Skapande av säsongdummies x1, x2, … , x11:
sold time month x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11

6
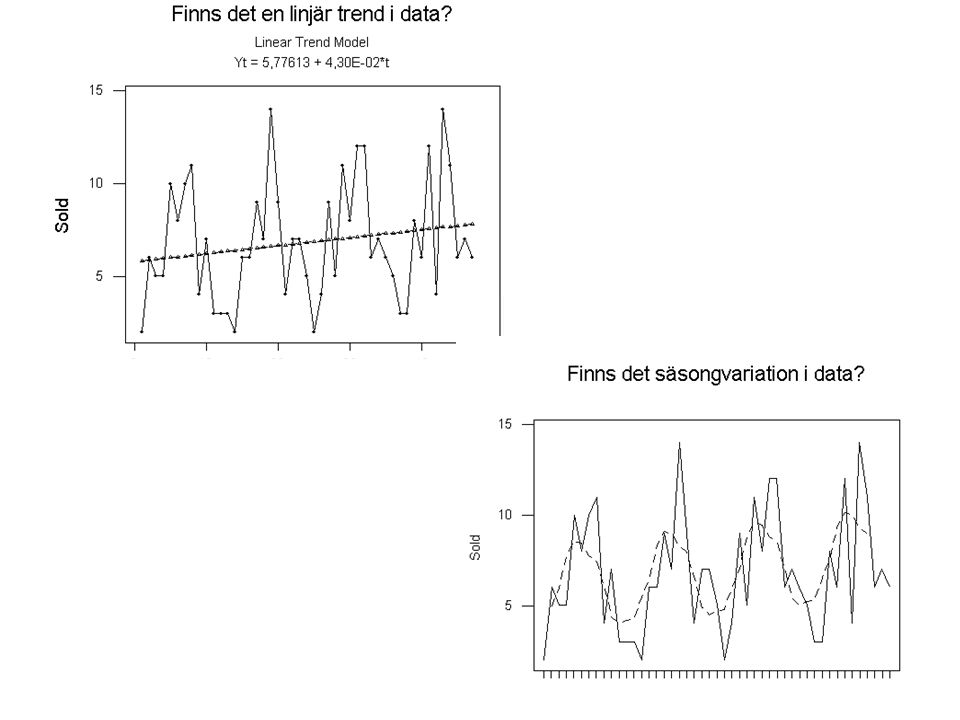
StatRegressionFitted Line plot…

7
Regression Analysis: sold versus time
The regression equation is sold = 5,78 + 0,0430 time Predictor Coef StDev T P Constant , , , ,000 time , , , ,215 S = 3, R-Sq = 3,4% R-Sq(adj) = 1,2% Analysis of Variance Source DF SS MS F P Regression , , , ,215 Residual Error , ,12 Total ,28
 = 1,2% Analysis of Variance. Source DF SS MS F P. Regression 1 16,00 16,00 1,58 0,215. Residual Error ,27 10,12. Total ,28.")
8
StatRegressionRegression…

9
Regression Analysis: sold versus time, x1, ...
The regression equation is sold = 3,65 + 0,0285 time - 1,69 x1 - 0,47 x2 + 2,75 x3 + 1,22 x4 + 6,20 x5 + 2,42 x6 + 8,14 x7 + 6,36 x8 + 0,58 x9 + 2,55 x10 + 1,02 x11 Predictor Coef StDev T P Constant , , , ,000 time , , , ,063 x , , , ,109 x , , , ,651 x , , , ,011 x , , , ,241 x , , , ,000 x , , , ,024 x , , , ,000 x , , , ,000 x , , , ,575 x , , , ,018 x , , , ,326 S = 1, R-Sq = 87,0% R-Sq(adj) = 82,4% Analysis of Variance Source DF SS MS F P Regression , , , ,000 Residual Error , ,801 Total ,277
 = 82,4% Analysis of Variance. Source DF SS MS F P. Regression ,031 34,169 18,97 0,000. Residual Error 34 61,246 1,801. Total ,277.")
10
Tolkning av parametrar:
Predictor Coef StDev T P Constant , , , ,000 time , , , ,063 x , , , ,109 x , , , ,651 x , , , ,011 x , , , ,241 x , , , ,000 x , , , ,024 x , , , ,000 x , , , ,000 x , , , ,575 x , , , ,018 x , , , ,326 Fungerar statistiskt som vanlig regression Tolkning av parametrar: Givet att vi håller oss inom en månad ökar sales med i genomsnitt 0,0285 enheter per tidsenhet I januari sjunker sales med i genomsnitt 1.69 enheter, i mars ökar sales med i genomsnitt 2.75 enheter etc. Residualanalys bör göras för att kontrollera om villkoren för regression är uppfyllt: Oberoende residualer Normalfördelade residualer (för att kunna lita på testen) Residualer med konstant varians (inga strutmönster)
 Residualer med konstant varians (inga strutmönster)")
11
Vanligtvis är inte oberoendeantagandet uppfyllt.
Följs residualerna åt eller är de mer sammanhängande här?

12
Test av oberoende (Durbin-Watson)
")
13
Durbin-Watson’s test bedömer om s k enstegs autokorrelation eller seriell korrelation förekommer bland residualerna: Corr(et,et-1 ) Positiv autokorrelation innebär att värdena följs åt: en positiv residual åtföljs oftast av en annan positiv residual, en negativ residual åtföljs oftast av en annan negativ residual. Negativ autokorrelation innebär att en positiv residual oftast åtföljs av en negativ residual och vice versa.
 Positiv autokorrelation innebär att värdena följs åt: en positiv residual åtföljs oftast av en annan positiv residual, en negativ residual åtföljs oftast av en annan negativ residual. Negativ autokorrelation innebär att en positiv residual oftast åtföljs av en negativ residual och vice versa.")
14
d MTB > regress ’sold' 1 'time'; SUBC> DW.
Regression Analysis: Sold versus time The regression equation is sold = time Predictor Coef SE Coef T P Constant time S = R-Sq = 3.4% R-Sq(adj) = 1.2% Analysis of Variance Source DF SS MS F P Regression Residual Error Total Unusual Observations Obs time Sold Fit SE Fit Residual St Resid R R R denotes an observation with a large standardized residual Durbin-Watson statistic = 1.51 d
 = 1.2% Analysis of Variance. Source DF SS MS F P. Regression Residual Error Total Unusual Observations. Obs time Sold Fit SE Fit Residual St Resid R R. R denotes an observation with a large standardized residual. Durbin-Watson statistic = d.")
15
Bedömningen av d görs enligt följande approximativa tumregler (tabeller för mer ordentlig bedömning finns men inte i den aktuella kursboken) Om d är nära 2 Ingen signifikant autokorrelation Om d är < 1 Signifikant positiv autokorrelation Om d är > 3 Signifikant negativ autokorrelation 1.51 i vår analys är varken lägre än 1 eller högre än 3Ingen autokorrelation kan påvisas.

16
Vissa tidsserier har s k exponentiell trend:
Modell: där 0 och 1 är konstanter och t är en multiplikativ felterm med väntevärde 1. Modellen logaritmeras och analyseras sedan med regression som vanligt. Jämför avsnittet om exponentiella modeller.

17
Klassisk komponentuppdelning
En tidsserie kan tänkas bestå av ett antal komponenter: 1) Trend, som beskriver en långsiktig ökning (eller minskning) i nivån hos värdena. Vid tidpunkten t betecknas denna komponent TRt 2) Säsong(svariation) som beskriver förändringsmönstret inom vanligtvis ett år (förändring från kvartal till kvartal, från månad till månad etc.) Vid tidpunkten t betecknas denna komponent SNt 3) Cyklisk variation, som beskriver långsiktiga svängningar i nivån hos värdena (konjunkturvariationer, meteorologisk variation) Vid tidpunkten t betecknas denna komponent CLt 4) Oregelbunden variation: Sådant som ej kan förklaras, betecknas IRt
 Trend, som beskriver en långsiktig ökning (eller minskning) i nivån hos värdena. Vid tidpunkten t betecknas denna komponent TRt. 2) Säsong(svariation) som beskriver förändringsmönstret inom vanligtvis ett år (förändring från kvartal till kvartal, från månad till månad etc.) Vid tidpunkten t betecknas denna komponent SNt. 3) Cyklisk variation, som beskriver långsiktiga svängningar i nivån hos värdena (konjunkturvariationer, meteorologisk variation) Vid tidpunkten t betecknas denna komponent CLt. 4) Oregelbunden variation: Sådant som ej kan förklaras, betecknas IRt.")
18
Trenden är som regel ganska måttlig, men givetvis dominerande för exponentiellt växande tidsserier. Trenden kan annars vara linjär (som kanske här) eller kvadratisk Säsongsvariation brukar vara den mest dominerande och som ger tidsserien dess ständigt svängande mönster Den cykliska variation är för korta serier närmast obefintlig och syns bäst i långa tidsserier av speciellt nationalekonomisk karaktär Vanligt är (som i AJÅ) att trend och cyklisk komponent hålls ihop till en, oftast betecknad TCt . Orsaken är att vissa analytiker inte vill tala om för långsiktiga trender utan menar att den cykliska variationen ingår i det man avser med “trend”
 att trend och cyklisk komponent hålls ihop till en, oftast betecknad TCt . Orsaken är att vissa analytiker inte vill tala om för långsiktiga trender utan menar att den cykliska variationen ingår i det man avser med trend")
19
Modeller för klassisk komponentuppdelning:
Denna beskrivning överensstämmer inte helt med AJÅ, men är mer fullständig Som tidigare betecknar vi tidsseriens värde vid tidpunkten t med yt Multiplikativ modell: Karaktäriseras av att säsongseffekter och cykliska mönster verkar multiplikativt på nivån hos tidsserien. Ju högre nivå desto större säsongsvariation. Passar bra för ekonomiska data som ofta har den karaktären Additiv modell: Denna modell passar bättre för tidsserier där säsongsvariationen inte har särskilt mycket med nivån att göra (oftast där mänskliga faktorn inte är lika dominant) Passar bra för naturvetenskapliga data (variation i vattenflöden, naturlig nedbrytning av näringsämnen i mark, nederbörd mm.)
 Passar bra för naturvetenskapliga data (variation i vattenflöden, naturlig nedbrytning av näringsämnen i mark, nederbörd mm.)")
20
Skattning av komponenter, arbetsgång
Säsongrensning: Säsongkomponenten är den komponent som varierar mest och med detta överskuggar de övriga komponenterna. Serien rensas från säsongkomponenten genom beräkning av s k centrerade och viktade glidande medelvärden (centered moving avereages): där L=Antal säsonger i serien (L=2 för halvårsdata, 4 för kvartalsdata och 12 för månadsdata)
: där L=Antal säsonger i serien (L=2 för halvårsdata, 4 för kvartalsdata och 12 för månadsdata)")
21
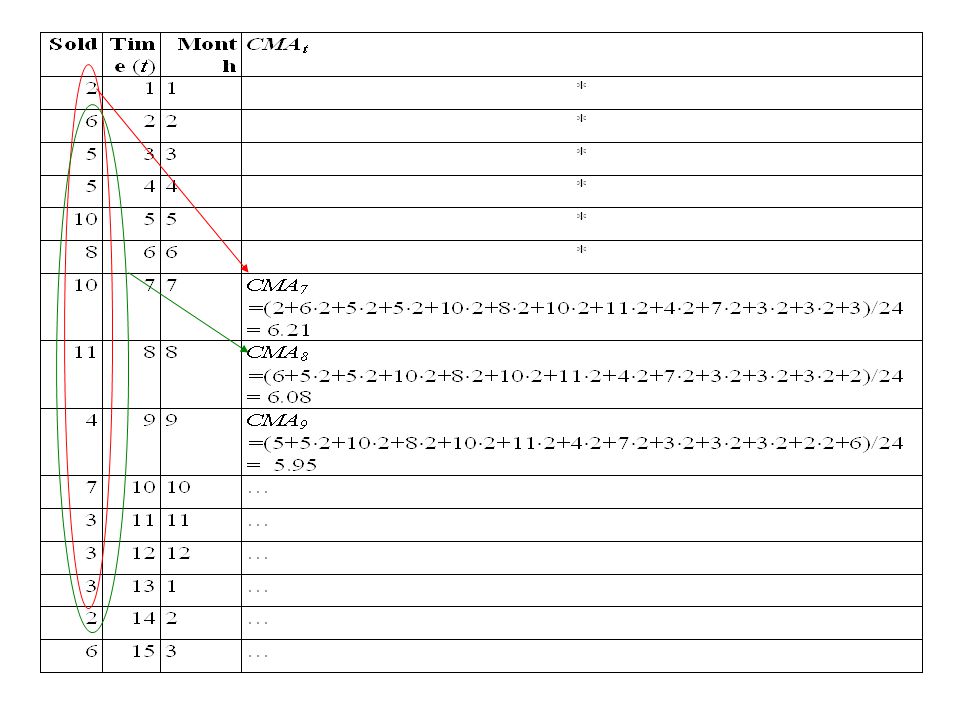
Exempel (sales data från tidigare)
")
23
Trend och cyklisk komponent (TCt ) skattas tillfälligt (grovt) av CMAt.
 skattas tillfälligt (grovt) av CMAt.")
24
Grova säsongkomponenter erhålls genom
yt/CMAt i en multiplikativ modell yt – CMAt i en additiv modell Medelvärden av dessa bildas över alla säsonger, t ex vid månadsdata bildas medelvärden av alla grova säsongkomponenter för januari, för februari, etc. Totalt L medelvärden. Medelvärdena justeras så att de vid multiplikativ modell får medelvärde 1, dvs. summan av alla justerade säsongmedelvärden skall bli L (4 för kvartalsdata, 12 för månadsdata). vid additiv modell får medelvärde 0, dvs. summan av alla justerade säsongmedelvärden skall bli 0. Slutligt skattade säsongkomponenter blir dessa justerade medelvärden och betecknas sn1, sn2, … , snL
. vid additiv modell får medelvärde 0, dvs. summan av alla justerade säsongmedelvärden skall bli 0. Slutligt skattade säsongkomponenter blir dessa justerade medelvärden och betecknas sn1, sn2, … , snL.")
25
Exempel, forts Med multiplikativ modell får vi

26
Medelvärden av grova säsongkomponenter:
Juli: ( )/3 Aug: ( )/3 Sep: ( )/3 Okt: ( )/3 Nov: ( )/3 Dec: ( )/3 Jan: ( )/3 Feb: ( )/3 Mar: ( )/3 Apr: ( )/3 Maj: ( )/2 Obs! Bara två värden här! Juni: ( )/2 …och här!
/3 Aug: ( )/3 Sep: ( )/3 Okt: ( )/3 Nov: ( )/3 Dec: ( )/3 Jan: ( )/3 Feb: ( )/3 Mar: ( )/3 Apr: ( )/3 Maj: ( )/2 Obs! Bara två värden här! Juni: ( )/2 …och här!")
27
Summan av de beräknade medelvärdena:
) Summan skall bli L=12 För att få den till 12 multipliceras samtliga medelvärden med 12/ Alternativt kan samtliga medelvärden divideras med medelvärdet av dem, dvs. divideras med /12, vilket ju blir samma sak.
 Summan skall bli L=12. För att få den till 12 multipliceras samtliga medelvärden med. 12/ Alternativt kan samtliga medelvärden divideras med medelvärdet av dem, dvs. divideras med /12, vilket ju blir samma sak.")
28
Slutligt skattade säsongkomponenter:
Jan: sn1 = · 0.403 Feb: sn2 = · 0.440 Mar: sn3 = · 1.126 Apr: sn4 = · 0.843 Maj: sn5 = · 1.483 Juni: sn6 = · 1.097 Juli: sn7 = · 1.809 Aug: sn8 = · 1.617 Sep: sn9 = · 0.702 Okt: sn10 = · 1.056 Nov: sn11 = · 0.782 Dec: sn12 = · 0.641

29
Obs! Värdena hos denna komponent varierar runt 1 vid multiplikativ modell och runt 0 vid additiv modell Ingen större mening att plotta denna komponent tillsammans med y

30
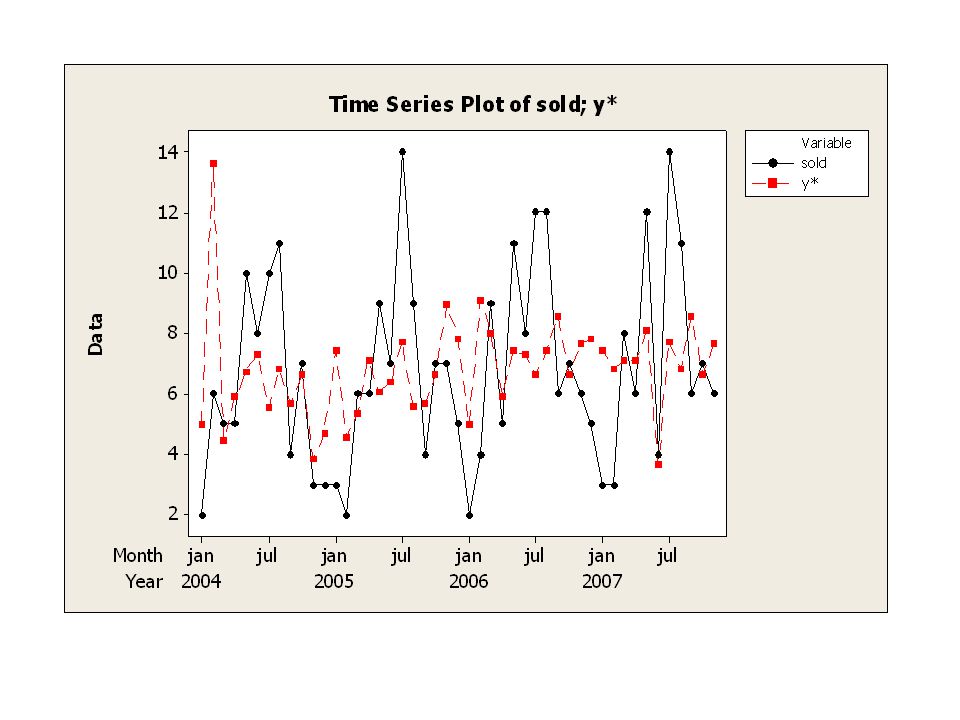
Tidsserien säsongrensas genom
vid multiplikativ modell vid additiv modell där är något av värdena beroende på vilken av säsongerna som t motsvarar.

31
Exempel, forts

33
De säsongrensade värdena används för att skatta trendkomponent
Tillämpa regressionsanalys på de säsongrensade värdena. Skatta en linjär eller kvadratisk trend TRt. trt

34
3. Cyklisk och oregelbunden komponent:
Om cyklisk komponent ej finns med: Residualerna från regressionsanalysen utgör skattning av termen IRt i den klassiska modellen. irt Om cyklisk komponent finns med: Skatta cyklisk och oregelbunden komponent ihop (dvs. sära ej på dem) med
 med.")
35
Även värdena hos denna komponent varierar runt 1 vid multiplikativ modell och runt 0 vid additiv modell Ingen större mening här heller att plotta denna komponent tillsammans med y

36
Den cykliska komponenten skattas nu genom ett centrerat oviktat glidande medelvärde:
och den oregelbundna komponenten skattas slutligen som

37
2m+1 väljs i regel till något av värdena 3, 5, 7, 9, 11, 13
Hur m skall väljas bestäms genom att titta på den slutliga skattningen av IRt m väljs så att autokorrelationen och variansen för dessa värden blir så låg som möjligt. 2m+1 kallas antal punkter i det glidande medelvärdet

38
Exempel, forts Glidande medelvärde med 2m + 1 = 5 (dvs. m = 3)
")
39
Minitab kan användas för komponentuppdelning med
StatTime seriesDecomposition Multiplikativ modell är dock något annorlunda i Minitab: yt = TRt·SNt + IRt Val av modelltyp Möjlighet att välja komponenter, men dock begränsat

40
Tidsskalan sätts något annorlunda här
Säsongrensade data

41
Det här är trt men anges något missvisande som Yt
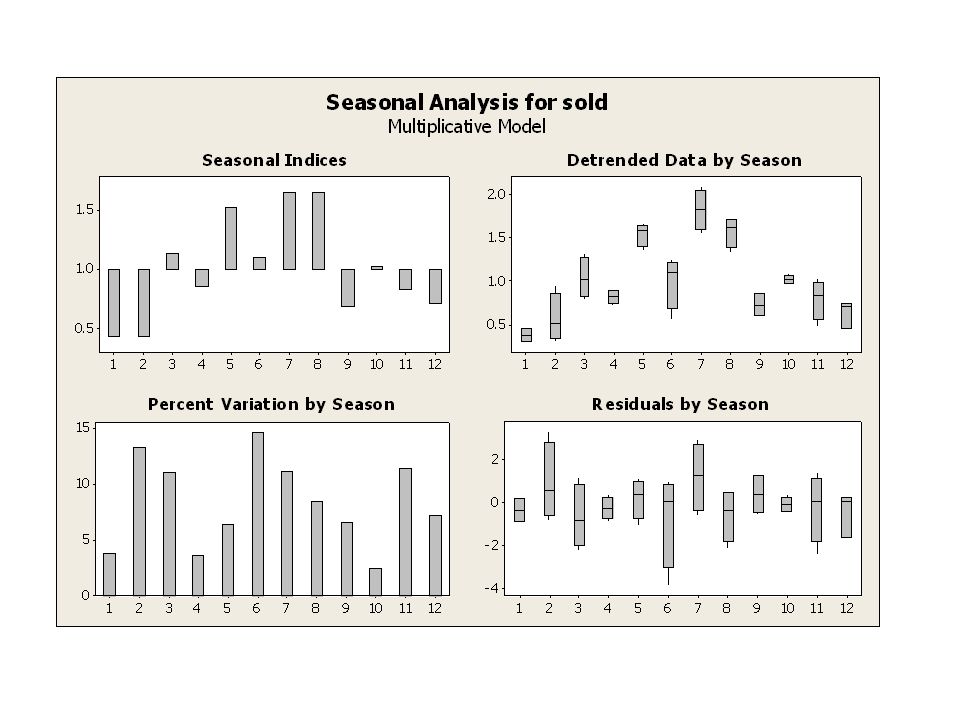
Time Series Decomposition for sold Multiplicative Model Data sold Length 47 NMissing 0 Fitted Trend Equation Yt = *t Seasonal Indices Period Index Det här är trt men anges något missvisande som Yt Dessa blir något annorlunda jämfört med handräkningen tidigare p g a att modellen är något annorlunda Accuracy Measures MAPE MAD MSD

42
Vad står måtten MAPE, MAD och MSD för?
Alla tre är mått på anpassning och kan delvis jämföras med MSE i den multipla regressionen: Denna är den som är mest lik MSE. Notera dock att vi dividerar med n och inte med n – k – 1. Orsaken är att vi här inte har någon regressionsmodell med parametrar, typ 2 som skall skattas väntevärdesriktigt. MSD är bara ett mått på anpassning som kan jämföras mellan olika modeller. Storleksmässigt kan dock MSD jämföras med MSE från tidsserieregressionen och är skillnaden markant kan vi också se vilken av modellerna som får bäst anpassning. Mean Square Deviation

43
Mean Absolute Deviation
MAD mäter ”direkt” anpassning som MSD men skillnaden är att här tar vi absolutavvikelser istället för kvadratiska avvikelser. Det blir alltså stor skillnad på värdena mellan MAD och MSD och de skall inte jämföras inom en modell. MAD är mindre känslig för avvikande värden och blir mer användbar när vi har något enstaka värde som uppträder konstigt, t ex att campingintäkterna en viss sommar är extremt lågt p g a att det har regnat hela juli. Ytterligare en fördel med MAD är att dess värde är i samma skala som yt-observationerna själva, vilket gör det lättare att tolka

44
Mean Absolute Percentage Error
Måttet går också på absoluta avvikelser, men mäter dem relativt nivån hos y. Vi får alltså relativa (procentuella) avvikelser istället för absoluta avvikelser. Måttet är praktiskt för multiplikativa modeller där den oregelbundna komponenten (IRt ) är ganska betydande, eftersom avvikelserna då blir stora när vi har stora värden på y och vice versa. Gemensamt för alla tre mått är att de skall vara så små som möjligt. Vid val mellan t ex additiv modell och multiplikativ modell kan det hända att något av måtten är högre för den ena modellen mellan ett annat mått är lägre. Det gäller alltså att tolka måtten med visst förnuft.
 avvikelser istället för absoluta avvikelser. Måttet är praktiskt för multiplikativa modeller där den oregelbundna komponenten (IRt ) är ganska betydande, eftersom avvikelserna då blir stora när vi har stora värden på y och vice versa. Gemensamt för alla tre mått är att de skall vara så små som möjligt. Vid val mellan t ex additiv modell och multiplikativ modell kan det hända att något av måtten är högre för den ena modellen mellan ett annat mått är lägre. Det gäller alltså att tolka måtten med visst förnuft.")
45
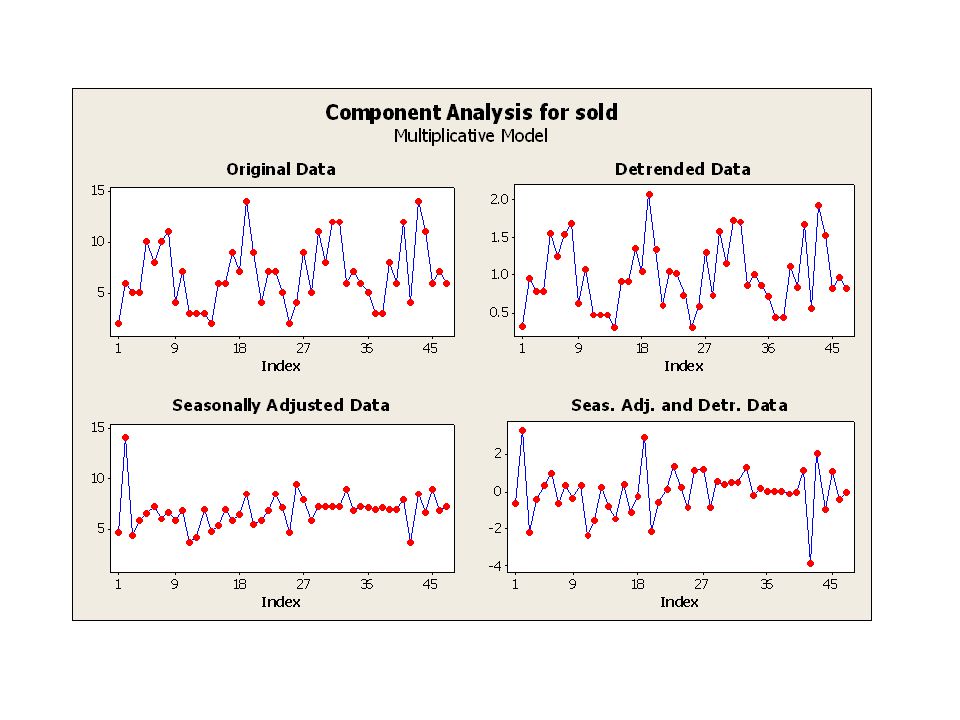
Till analysen följer automatiskt (men kan väljas bort) tre diagram:
 tre diagram:")
48
Skattade trend- och säsongkomponenter har lagrats i kolumnerna TREN1 resp. SEAS1
Beräkning av (cl ir )t kan göras genom att dividera originaldata med produkten av dessa två CLIR1=Sold/(TREN1· SEAS1) Den cykliska komponenten skall nu skattas genom beräkning av glidande medelvärden på CLIR1
t kan göras genom att dividera originaldata med produkten av dessa två. CLIR1=Sold/(TREN1· SEAS1) Den cykliska komponenten skall nu skattas genom beräkning av glidande medelvärden på CLIR1.")
49
StatTime SeriesMoving Average…
Antal punkter i det glidande medelvärdet

50
Vi vill se de glidande medelvärdena och inte hur de kan användas för att beräkna ettstegsprognoser
Sparar de glidande medelvärdena, dvs. den skattade cykliska komponenten i en ny kolumn, som får namnet AVER1

52
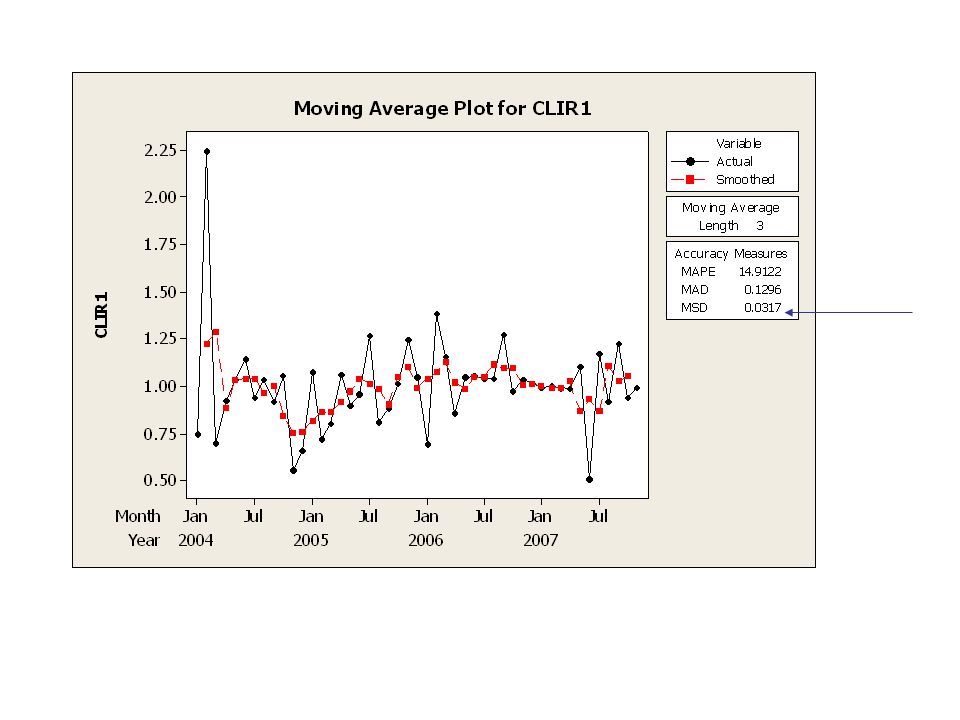
Den oregelbundna komponenten (IR) skattas slutligen genom att dividera CLIR1 med AVER1
De resulterade värdena studeras sedan med avseende på spridning, s och seriell korrelation, Corr ( irt , irt-1) 2m+1 s Corr(irt,irt-1) 3 0.219 -0.685 5 0.197 -0.293 7 0.173 -0.343 9 0.171 -0.345 11 0.181 -0.277 13 0.166 -0.199
 2m+1. s. Corr(irt,irt-1)")
54
Seriella korrelationer kan enkelt beräknas med
StatTime seriesLag och sedan StatBasic statisticsCorrelation eller manuellt i Session window: MTB > lag ’IR6’ c125 MTB > corr ’IR6’ c125

55
Analys med additiv modell:

56
Inga större skillnader i skattad trend
Time Series Decomposition for sold Additive Model Data sold Length 47 NMissing 0 Fitted Trend Equation Yt = *t Seasonal Indices Period Index Inga större skillnader i skattad trend Accuracy Measures MAPE MAD MSD Dessa blir alla något lägre än vid multiplikativ modell vilket indikerar att den additiva modellen är något bättre Dessa blir helt annorlunda jämfört med multiplikativ modell (summerar till 0 istället för till 1)
")
57
additiv multiplikativ

58
multiplikativ

Liknande presentationer