Ladda ner presentationen
Presentation laddar. Vänta.

1
Stickprovsförfaranden
De flesta typer av studier bygger på stickprov från den population som skall undersökas Stickprov kan vara En serie mätningar av en företeelse Ett urval av enheter ur en stor mängd Ett ändligt antal observationer av en eller flera egenskaper mm. Storleken hos ett stickprov (antal mätningar, urvalssorlek, antal observationer etc. bestäms utifrån olika syften För att uppnå en viss precision i en skattning För att med hög sannolikhet kunna påvisa något (t.ex. att ett visst gränsvärde har överskridits, att två halter inte är likadana mm.) För att kunna göra uttalanden om sammansättningar i populationer
 För att kunna göra uttalanden om sammansättningar i populationer.")
2
Bestämning av stickprovsstorlek för uppnående av precision
Tillämpas i forensiska sammanhang typiskt för en serie av mätningar av en egenskap. Skattning av medeltal : punktskattas som regel med ett aritmetiskt medelvärde Precisionen i skattningen uttrycks med ett konfidensintervall för . Om vi antar att våra mätningar är (hyfsat) normalfördelade blir det teoretiska konfidensintervallet där z/2 är aktuella normalfördelningskvantil (1.96 för 95%-iga intervall, för 99%-iga intervall etc.) och är den teoretiska standardavvikelsen för mätningarna.
 normalfördelade blir det teoretiska konfidensintervallet. där z/2 är aktuella normalfördelningskvantil (1.96 för 95%-iga intervall, för 99%-iga intervall etc.) och är den teoretiska standardavvikelsen för mätningarna.")
3
I praktiken är inte känd och då används t-fördelningen istället med följande formel
där t/2,n – 1 är motsvarande kvantil i t-fördelningen men n – 1 frihetsgrader och sär stickprovsstandardavvikelsen. Eftersom vi inte tagit något stickprov ännu är inte något s beräknat. Vidare är vår avsikt att bestämma n och då kan vi heller inte känna till vilket värde på t/2,n – 1 som skall användas. Dimensionering av stickprovsstorlek, dvs. bestämning av n måste därför göras på basis av det teoretiska konfidensintervallet. (Anm. Om antalet mätningar måste begränsas, t.ex. av kostnadsskäl, finns det stor anledning att på experimentell basis fastställa en stabil skattning av och använda denna som ett ”teoretiskt” värde för att kunna använda det smalare teoretiska konfidensintervallet)
")
4
Antag nu att vi vill ha en precision sådan att bredden hos ett 95%-igt konfidensintervall för är högst B. Bredden hos ett sådant intervall är Precisionskravet kan därför uttryckas Om det istället är ett 99%-igt konfidensintervall som skall ha högst bredden B blir precisionskravet Generellt uttryck är

5
Vi väljer själv konfidensgrad och bredd utifrån de allmänna precisionsönskemål som finns för studien. är däremot del av expertkunskapen. Exempel: Antag att vi skall uppskatta THC-halten hos en beslagtagen hampaplanta. Hur många mätningar behöver göras om vi vill uppskatta halten med ett 99% konfidensintervall med bredd högst 0.01 och vi bedömer att standardavvikelsen hos våra mätningar är ungefär 0.005? Vi bör göra minst 7 mätningar

6
Skattning av en proportion, p, enheter med en viss egenskap:
Klassiskt görs detta på liknande sätt som vid skattning av ett medeltal. Stickprovsstorlekarna blir dock betydligt större. Mätdata består i detta fall av ettor och nollor, eftersom varje mätning syftar till att avgöra om enheten ifråga besitter egenskapen eller ej. I dessa sammanhang gäller att Vår formel för att bestämma n blir generellt Vi behöver alltså ha en förhandsuppfattning om värdet hos p. Konservativt kan detta sättas till 0.5 vilket maximerar p(1 – p) och ger största nödvändiga stickprovsstorlek. Detta leder dock till mycket stora n (runt 400 för rimliga precisionskrav) och är definitivt inte praktiska för forensiska laboratorier.
 och ger största nödvändiga stickprovsstorlek. Detta leder dock till mycket stora n (runt 400 för rimliga precisionskrav) och är definitivt inte praktiska för forensiska laboratorier.")
7
Ett alternativ: Om egenskapen i fråga är sådan att den kan relateras till en kontinuerlig mätbar variabel, X, i form av ett intervall, t.ex. X > 0.20 200 < X < 300 etc. kan vi utnyttja en skattad fördelningsfunktion för X för att skatta p. Exempel: Antag att vi vill skatta proportionen p hampaplantor i en odling som skall klassas som Cannabis. Detta innebär att THC-halten i en planta överstiger värdet 0.20. Ett mätvärde X av THC-halten i en slumpmässigt vald planta kan antas vara normalfördelad med väntevärde (sann halt) och standardavvikelse Proportionen kan då uttryckas
 och standardavvikelse Proportionen kan då uttryckas.")
8
I ett stickprov hampaplantor från odlingen beräknar vi medelhalten
och vi skattar sedan p med Ett konfidensintervall för p kan med utnyttjande av samma transformation beräknas som Detta är helt i sin ordning eftersom en fördelningsfunktion ( ovan) för en kontinuerlig variabel alltid är en strängt växande funktion. Via litet mer matematiskt (och datormässigt) fixande kan vi nu bestämma n så att ovanstående konfidensintervall får önskad bredd.
 för en kontinuerlig variabel alltid är en strängt växande funktion. Via litet mer matematiskt (och datormässigt) fixande kan vi nu bestämma n så att ovanstående konfidensintervall får önskad bredd.")
9
Bestämning av stickprovsstorlek för att med hög sannolikhet kunna påvisa något
Antag att vi vill testa hypotesen H0 : Hampaplantan har en THC-halt som är högst 0.20 mot Ha : Hampaplantan har en THC-halt som överstiger 0.20 I en klassisk statistisk hypotesprövning väljer vi signifikansnivå hos testet, vilket är sannolikheten för fel av första slaget (typ-I-fel), som i sin tur är att förkasta en sann nollhypotes. Denna sannolikhet betecknas . Typisk teststorhet i detta fall är där och s är medelvärde och standardavvikelse för n (oberoende) mätningar av THC-halten i plantan.
, som i sin tur är att förkasta en sann nollhypotes. Denna sannolikhet betecknas . Typisk teststorhet i detta fall är. där och s är medelvärde och standardavvikelse för n (oberoende) mätningar av THC-halten i plantan.")
10
H0 förkastas nu om (Observera att i detta fall används bara ena svansen i t-fördelningen då testet är enkelsidigt) Om vi nu vill kunna förkasta H0 med hög sannolikhet när Ha är sann så ställer detta krav på stickprovsstorleken n . Här behöver vi använda oss av begreppen fel av andra slaget och styrka. Fel av andra slaget Detta värde som synes av det sanna värdet hos halten, . Om t.ex. den sanna halten är 0.30 skulle felet av det andra slaget skrivas Vi inser också att

11
Oftast använder man sig istället av funktionen 1 – ( ) som kallas testets styrkefunktion.
När nu n skall bestämmas utgår man från ett krav som innebär att styrkan hos ett test med en given signifikansnivå skall ha en viss storlek för ett visst värde på . T.ex. kanske vi vill att styrkan i testet ovan utfört på 1% signifikansnivå skall vara minst 90% då den sanna halten är 0.22. Vi får då följande ekvation att lösa: Ekvationen kan dock inte lösas så att en snygg explicit formel erhålls. Även här krävs förstås kunskap om men ett större problem är att vi måste införa en s.k. icke-central t-fördelning. När den sanna halten är 0.22 blir nämligen t* icke-centralt t-fördelad och inte centralt (som tabeller och Excel bygger på). Det krävs att problemet programmeras för datorlösning.
. Det krävs att problemet programmeras för datorlösning.")
12
Minitab (m fl programpaket) kan generera styrkefunktionskurvor baserade på givna signifikansnivåer och variansantaganden För exemplet ovan kan vi t.ex. ta fram följande kurvor T.ex. kan man avläsa att för att få en styrka > 90% när halten är =0.22 krävs minst 4 mätningar

13
Liknande studier måste göras för hypoteser av formen
Här utgår man från styrkan (eller fel av andra slaget) för en standardiserad differens mellan 1 och 2 . Olika läroböcker redovisar kurvor över typ-II-felet som funktion av denna standardiserade differens för olika stickprovsstorlekar. En komplikation i detta sammanhang är att det är två stickprov som skall tas. Se vidare i Lucy Motsvarande teknik används vidare vid planering av experimentella försök. Ett sådant exempel är dimensionering av försöksenheter till ett försök där olika tekniker för DNA-extraktion skall genomföras. Här krävs förutom kunskap om bakomliggande slumpstandardavvikelse i mätningarna också val av en bra design där hänsyn tas till försöksenheternas mellanvariation (t.ex. olika tjocklek hos hårstrån om sådana används som försöksenheter)
 för en standardiserad differens mellan 1 och 2 . Olika läroböcker redovisar kurvor över typ-II-felet som funktion av denna standardiserade differens för olika stickprovsstorlekar. En komplikation i detta sammanhang är att det är två stickprov som skall tas. Se vidare i Lucy. Motsvarande teknik används vidare vid planering av experimentella försök. Ett sådant exempel är dimensionering av försöksenheter till ett försök där olika tekniker för DNA-extraktion skall genomföras. Här krävs förutom kunskap om bakomliggande slumpstandardavvikelse i mätningarna också val av en bra design där hänsyn tas till försöksenheternas mellanvariation (t.ex. olika tjocklek hos hårstrån om sådana används som försöksenheter)")
14
Bestämning av stickprovsstorlek för en proportion när ett stickprov i princip alltid ger skattningen 100% Speciellt problem! Om vi skulle utgå från reglerna ovan blir konfidensintervallet bredd alltid Exempel Från ett beslag om en påse med tabletter som misstänks vara Ecstasy skall ett stickprov tas för analys. Erfarenheten säger oss att vi alltid får endera 100% Ecstasytabletter i stickprovet eller 100% av ett annat slag (t.ex. icke-narkotiskt preparat). Förnuftet säger oss att det knappast finns olika sorters tabletter i ett illegalt beslag.
. Förnuftet säger oss att det knappast finns olika sorters tabletter i ett illegalt beslag.")
15
Ett annat synsätt (Bayesianskt):
Alternativlösningen som gavs tidigare är inte särskilt tillämpbar. Att det är Ecstasy avgörs inte genom mätningar av en endimensionell variabel. Ett annat synsätt (Bayesianskt): Istället för att betrakta proportionen som fix så uttrycker vi vår osäkerhet om den som en sannolikhetsfördelning. Proportionen kan anta värden mellan 0 och 1. Frågan är vilka värden som är mer sannolika?
: Istället för att betrakta proportionen som fix så uttrycker vi vår osäkerhet om den som en sannolikhetsfördelning. Proportionen kan anta värden mellan 0 och 1. Frågan är vilka värden som är mer sannolika")
16
Utgår från att alla proportioner mellan 0 och 1 är lika troliga.
Utgår från att proportioner nära 0.5 är mer troliga än proportioner nära 0 eller 1. Utgår från att proportioner nära 0 eller 1 är mer troliga än andra.

17
Bayes’ sats applicerad på täthets- och sannolikhetsfunktioner:
Låt den sannolikhetsfördelning vi antar representerar osäkerheten i p betecknas g(p) Detta benämns a priori – tätheten för p (eng. prior density). Vi kombinerar nu g(p) med den information vi har från ett (tänkt) stickprov. Låt X = Antal tabletter som innehåller Ecstasy i stickprovet. X har då sannolikhetsfördelningen Bi(n, p) och dess täthets(sannolikhets)funktion betecknas här f(x | p ) Bayesiansk filosofi bygger på att X är observerad och därmed (tillfälligt) fix medan p fortfarande svävar i det okända.
 Detta benämns a priori – tätheten för p (eng. prior density). Vi kombinerar nu g(p) med den information vi har från ett (tänkt) stickprov. Låt X = Antal tabletter som innehåller Ecstasy i stickprovet. X har då sannolikhetsfördelningen Bi(n, p) och dess täthets(sannolikhets)funktion betecknas här. f(x | p ) Bayesiansk filosofi bygger på att X är observerad och därmed (tillfälligt) fix medan p fortfarande svävar i det okända.")
18
Ur sannolikhetsteoretisk synvinkel betraktar vi dock såväl p som X som ”slumpvariabler” och då gäller följande: där f(x) är den obetingade täthets(sannolikhets)funktionen för X, dvs. en täthetsfunktion som blir en sammanvägning över alla p utifrån hur sannolika de är. Beräkning av f(x) kan göras med som ofta ersätter f(x) i uttrycket ovan. Jämför med Bayes’ sats h(p | x) är en täthetsfunktion för p där vi har tagit i beaktning att antalet Ecstasytabletter blev x i ett stickprov, d vs. att X fick värdet x. Detta är en uppdatering av g(p) och kallas därför a posteriori – täthet (eng. posterior density)
 är den obetingade täthets(sannolikhets)funktionen för X, dvs. en täthetsfunktion som blir en sammanvägning över alla p utifrån hur sannolika de är. Beräkning av f(x) kan göras med. som ofta ersätter f(x) i uttrycket ovan. Jämför med Bayes’ sats. h(p | x) är en täthetsfunktion för p där vi har tagit i beaktning att antalet Ecstasytabletter blev x i ett stickprov, d vs. att X fick värdet x. Detta är en uppdatering av g(p) och kallas därför a posteriori – täthet (eng. posterior density)")
19
I stället för att beräkna ett konfidensintervall för p baserat enbart på data i stickprovet använder vi nu h(p | x) för att konstruera ett s.k. kredibilitetsintervall för p. T.ex. ett nedåt begränsat kredibilitetsintervall för p med tillförlitlighet 99% beräknas med hjälp av ekvationen: Intervallet blir (p0 , 1) eller p > p0
 eller p > p0.")
20
De exempel på g(p) vi tidigare tog upp är alla exempel på s. k
De exempel på g(p) vi tidigare tog upp är alla exempel på s.k. Beta-fördelningar. Dessa varierar mellan 0 och 1 och har följande matematiska täthetsfunktion där den s.k. Beta-funktionen a och b är fördelningens parametrar och det är dessa som avgör formen på täthetsfunktionen. a = b innebär en symmetrisk täthetsfunktion a = b =1 a = b =2 a = b =0.2
 vi tidigare tog upp är alla exempel på s.k. Beta-fördelningar. Dessa varierar mellan 0 och 1 och har följande matematiska täthetsfunktion. där. den s.k. Beta-funktionen. a och b är fördelningens parametrar och det är dessa som avgör formen på täthetsfunktionen. a = b innebär en symmetrisk täthetsfunktion. a = b =1. a = b =2. a = b =0.2.")
21
Om vi nu antar att g(p) är en Beta-fördelning och X är Bi(n, p) hur blir h(p | x) ?
dvs. en annan Beta-fördelning med parametrar a + x resp. b + n – x

22
Vi kan nu bestämma stickprovsstorleken så att den nedre gränsen i ett kredibilitetsintervall blir vad vi önskar. T.ex. kanske vi vill med 99% tillförlitlighet kunna påstå att p är > 0.8 I ett beslag om 1000 tabletter skulle detta innebära att vi med 99% tillförlitlighet kan påstå att minst 800 tabletter innehåller Ecstasy Kan vara tillräckligt för att uppnå en viss straffsats i rätten. Ekvationen blir att bestämma n så att men... Då måste vi ju veta vad x är?

23
Som vi inledningsvis sa räknar vi med att x endera är = 0 eller = n.
Vi räknar på fallet x = n och har som beslutsregel att göra om stickprovsförfarandet om det skulle visa sig att x blir < n. Vad skall vi välja för värden på a och b ?

24
ENFSI (European Network of Forensic Science Laboratories) har utvecklat programvara för att bestämma n utifrån egna val av a och b. Tips ges även för val av värdena. Dock inte så ”vetenskapligt” baserade SKL har gjort en egen studie (Nordgaard, ) baserad på historiska fall vid laboratoriet. a och b kan som regel väjas mycket låga (runt 0.2)
 baserad på historiska fall vid laboratoriet. a och b kan som regel väjas mycket låga (runt 0.2)")
26
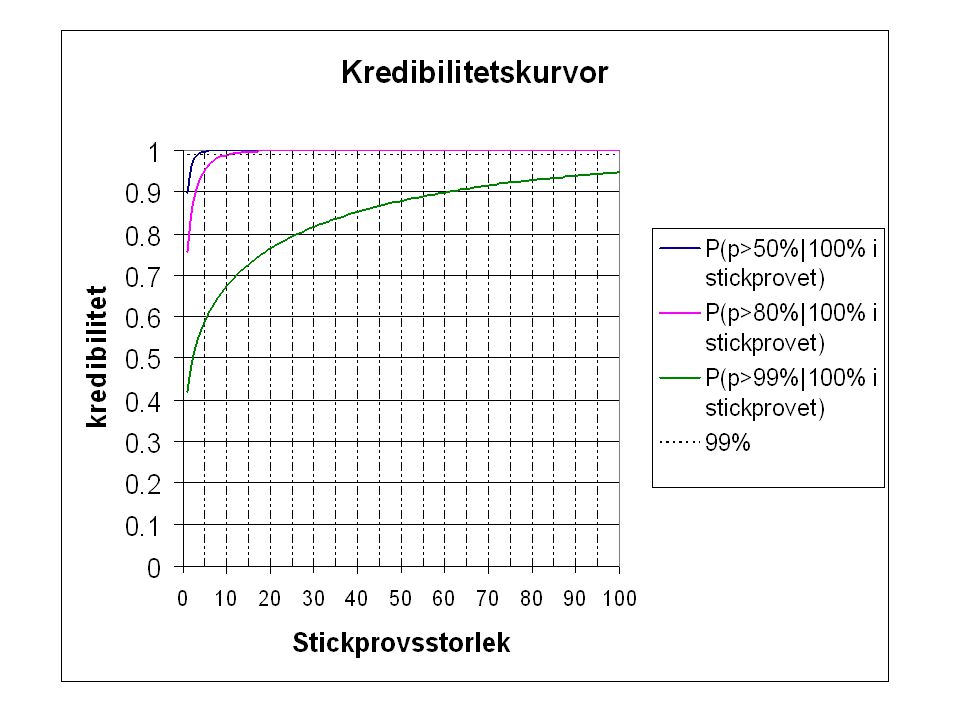
För analyser vid SKL av misstänkt Ecstasy, men även för andra typer av tabletter kan vi använda följande: För att kunna påstå att p är minst 50% krävs endast ett stickprov om 4-5 tabletter För att kunna påstå att p är minst 80% krävs ett stickprov om tabletter. Ett klassiskt angreppssätt på problemet blir knepigt eftersom ett intervall inte kan konstrueras utifrån stickprovsdata. Dessutom, för att de klassiska konfidensintervallen skall vara giltiga krävs stora värden på n. (Centrala gränsvärdessatsen)
")
Liknande presentationer