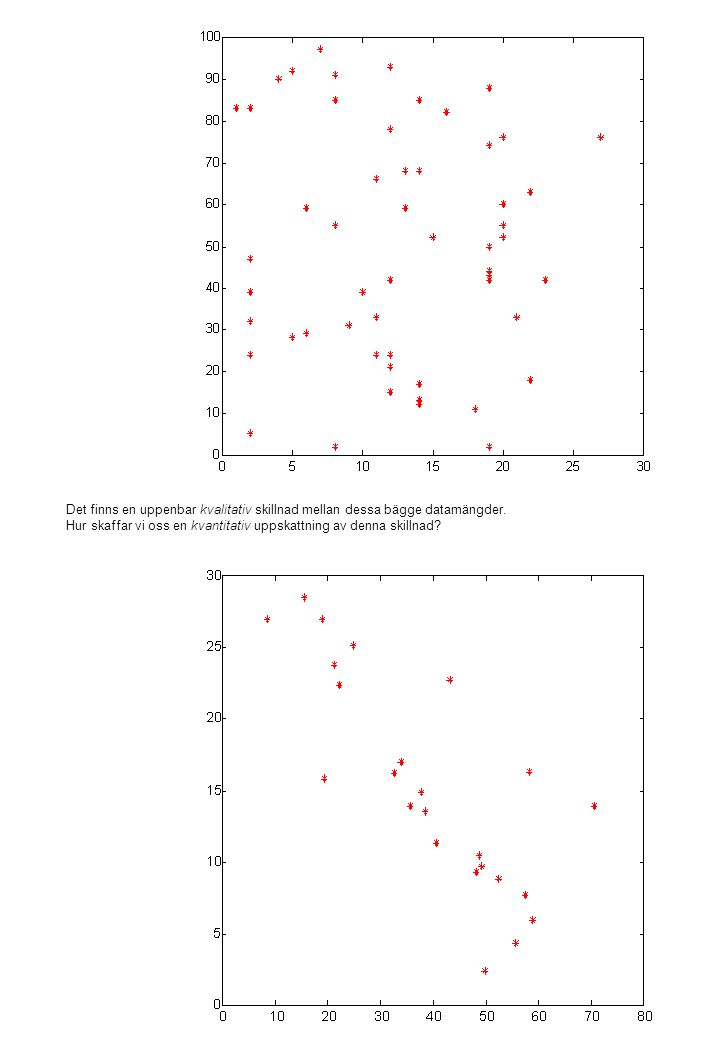
En mycket vanlig frågeställning gäller om två storheter har ett samband eller inte, många gånger är det helt klart: y x För en mätserie som denna är det ganska klart att det finns en koppling mellan x-variabeln och y-variabeln. Tekniskt så talar man om att det finns en korrelation mellan variablerna. Man skiljer mellan olika typer av korrelation: y x y y y x x x Ingen korrelation Icke-linjär korrelation Positiv korrelation Negativ korrelation Exemplen ovan är renodlade, normalt ser man oftast fall där det inte är lika klart om det föreligger en korrelation mellan variablerna eller inte. Det är också så att om man väljer x och y helt slumpmässigt så får man ibland fördelningar som ser mer korrelerade ut än andra, detta är man som vanligt mer känslig för ju färre punkter man betraktar. Figurerna nedan är två av tio stycken plottar där var och en innehåller tio slumpvis fördelade talpar I den högra ser man ingen tydlig korrelation, i den vänstra tycks det finnas en negativ korrelation
Det finns en uppenbar kvalitativ skillnad mellan dessa bägge datamängder. Hur skaffar vi oss en kvantitativ uppskattning av denna skillnad?
Korrelationskoefficient Korrelationskoefficienten, r, definieras som: För variabler som har en linjär relation kommer r att ligga nära ±1 (idealt exakt lika med ±1), linjära relationer med positiv riktiningskoefficient har r = 1 (oavsett storleken på riktningskoefficienten) och samband med negativ riktiningskoefficient har r = -1. Poängen är att vi kan testa hypotesen om ett linjärt samband även om vi inte har någon uppfattning om mätfelen i de enskilda punkterna. Men korrelationskoefficienten har en vidare betydelse än så. r=0 är ett nödvändigt, men inte tillräckligt, villkor för att två variabler skall vara oberoende. Finner vi r signifikant skilt från noll finns det alltså anledning att tro att variablerna i fråga inte är oberoende. Några exempel: Y = 3 + 4X r = 1 Y = X2 r = 0.978 Y = 3 + 4X - 5X2 r = - 0.974 Y = 3 +4X -5X2 r = -0.991
Som vi har sett exempel på ovan så kan även helt okorrelerade variabler ge värden på den linjära korrelationskoefficienten som är skiljt från noll. Man kan beräkna sannolikheten för att en slumpmässig fluktuation skall ge en linjör korrelationskoefficient större än ett visst värde. Som oftast så är sannolikheten för slumpmässiga fluktuationer större om vi har ett litet antal talpar, tittar vi på många par så jämnar fluktuationerna ut sig. Tabeller över denna sannolikhet kan vi använda för att bedöma sannolikheten för att korrelationen i en given datamängd är slumpmässig eller inte. En sådan tabell är tabell 7.3 i läroboken. I denna visas, för varierande antal punkter, hur stort absolutbeloppet av korrelationskoefficienten skall vara för att uppnå två olika signifikansnivåer för korrelationen, 5% respektive 1%. Tabellen läses så att om vi t ex har 7 punkter så skall absolutbeloppet av korrelationskoefficienten vara större än 0.754 för att nå en signifikansnivå om 5% (0.875 för 1% signigikansnivå). Detta innebär att om vi tar ett stort antal icke-korrelerade tal och bildar grupper om 7 stycken i varje och sedan beräknar den linjära korrelationskoefficienten för dessa så kommer absolutbeloppet vara större ån 0.754 i 5% av dessa grupper, och större än 0.875 för 1% av dessa grupper. Har vi 7 talpar och en korrelationskoefficient med absolutbelopp större än 0.875 så är alltså sannolikheten att detta är en statistisk flukutation och att de sju talparen är okorrelerade mindre än 1%. Med så låg sannolikhet för en statistisk fluktuation väljer man ofta att tolka detta som att en korrelation faktiskt föreligger. Nu har vi kvantitativa verktyg för att analysera de data vi såg tidigare: Sannolikheten att 50 par av okorrelerade variabler har |r| > 0.05 är 73% => det verkar relativt sannolikt att första bokstaven i gatunamnet inte har något att göra med de två sista siffrorna i telefonnummret.
listad i tabeller som 7.3 i läroboken. Sannolikheten att 25 okorrelerade par av variabler har |r| > 0.7 är mindre än 0.05% => vi kan utesluta (med mer än 99.9% sannolikhet) att breddgrad inte påverkar årsmedeltemperatur Det är viktigt att minnas att även saker med så låga sannolikheter som 1% kommer i genomsnitt att inträffa en gång på 100. Betraktar vi ett tillräckligt stort antal parametrar och letar efter korrelationer mellan dessa så kommer vi att hitta till synes korrelerade variabler enbart på grund av slumpmässiga variationer. 15 variabler kan kombineras på över 100 sätt, så väljer vi att leta efter korrelationer mellan dessa så kommer statistiska fluktuationer ner mot 1%-nivån att uppträda! Allmänt så kan ett högt värde på korrelationskoefficienten bero på en av tre saker: 1: slumpmässiga fluktuationer. Sannolikheten för dessa kan beräknas och finns listad i tabeller som 7.3 i läroboken. 2: bägge variablerna påverkas av en gemensam faktor. Att sjukskrivningar för vård av sjukt barn är mycket vanliga kring månadsskiftet augusti-september beror inte först och främst på att det är särskilt lätt att bli sjuk just denna tid på året, utan på att terminen i skola och förskola börjar då. 3: en variabel beror av den andra, vi säger då att det finns ett kasualt samband. Ett viktigt sätt att försöka avgöra vilket som är fallet är att försöka hitta en model för kasualiteten, en modell som har förankring i något man tidigare observerat i andra sammanhang. Detta sätt att resonera har en mycket stark förankring inom naturvetenskapen.