Ladda ner presentationen
1
732G71 Statistik B Institution: IDA, avd. för statistik Kursansvarig: Anders Nordgaard, ANd –Anders.Nordgaard@liu.se –013-281974 –B-huset, ing. 27, 1 tr, korridor E (ovanför Café Java) –Arbetar deltid ( främst tor, fre) Övriga lärare: –Olle Eriksson (OE) –Josefine Johansson (JJ) –Handledare vid datorövningar (NN)
 –Arbetar deltid ( främst tor, fre) Övriga lärare: –Olle Eriksson (OE) –Josefine Johansson (JJ) –Handledare vid datorövningar (NN).")
2
Kurshemsida: www.ida.liu.se/~732G71 Kurslitteratur: –Andersson G, Jorner U, Ågren A: Regressions- och tidsserieanalys. 3:e uppl. StudentlitteraturBokakademin –Nordgaard: Något om indexHemsidan –Extra övningsuppgifterHemsidan –(Formelsamling) Hemsidan Undervisning: –10 föreläsningar (ANd, Teori och exempel) –6 lektioner (OE, JJ, ANd, Genomgång av övningsuppgifter, alla studerande förväntas ta aktiv del i diskussionen av lösningar) –5 räknestugor (OE, JJ, eget räknande med tillgång till handledning) –7 datorlaborationer (OE, JJ, ANd, NN) viktiga övningar i att använda dator (Minitab) för regressions- och tidsserieanalys Rekommenderade övningar till lektioner och räknestugor: Se undervisningsplanen på hemsidan. Instruktioner till datorövningar: Finns löpande på hemsidan.
 Hemsidan Undervisning: –10 föreläsningar (ANd, Teori och exempel) –6 lektioner (OE, JJ, ANd, Genomgång av övningsuppgifter, alla studerande förväntas ta aktiv del i diskussionen av lösningar) –5 räknestugor (OE, JJ, eget räknande med tillgång till handledning) –7 datorlaborationer (OE, JJ, ANd, NN) viktiga övningar i att använda dator (Minitab) för regressions- och tidsserieanalys Rekommenderade övningar till lektioner och räknestugor: Se undervisningsplanen på hemsidan. Instruktioner till datorövningar: Finns löpande på hemsidan..")
3
Examination –Projektarbete i grupp, 2.5 hp: Projektmomentet bedöms med något av betygen Godkänd eller Underkänd. För de flesta blir den praktiska betygsskalan Godkänd eller Komplettering. – Tentamen, 5.5 hp: 4-5 uppgifter. Till den första uppgiften skall fullständig lösning inlämnas, till övriga ges svar på svarsblankett enl. ”multiple choice”-modellen. Formelsamling och tabeller kommer att finnas fasthäftade i tentan. Bedöms med något av betygen Väl godkänd, Godkänd eller Underkänd. –Slutbetyg: Väl Godkänd, Godkänd eller Underkänd För Godkänd krävs att bägge examinationsmomenten är godkända För Väl Godkänd krävs att bägge examinationsmomenten är godkända samt betyget Väl Godkänd på tentamen.

4
Projektarbetet: –Grupparbete i grupp om max 4 personer. Gruppindelningen skall vara klar och meddelad senast 12 november. –Arbetet handlar om tidsserieanalys och bygger på Datorövning 6 och 7. –Skriftlig redovisning till kursansvarig senast 7 december. –Vid komplettering: Komplettering skall normalt göras inom 5 arbetsdagar. Om kompletteringen inte räcker till ges normalt ytterligare 5 arbetsdagar för förnyad komplettering etc. Mer information kommer att finnas på hemsidan.

5
Återkoppling till närmast tidigare kursvärdering Följande punkter togs speciellt upp vid föregående års kursvärdering: Lektionslärarna hade helt olika sätt att lösa problemen, vilket ledde till överbesökta lektioner för den ene av lärarna Formelsamlingen överensstämde inte tillfredsställande med lärobokens formler Mer information om vad finansiella data är behövs inför projektarbetet Lärobokens facit innehöll väl många fel Föreläsningsunderlagen bör komma ut något tidigare Dålig disciplin hos studenterna på att hålla sig till de schemalagda tiderna för datorövningar för respektive grupp

6
Kursdefinition Kursboken täcker tyvärr inte helt upp vad kursplanen förespråkar om innehållet. Den har dock valts efter tidigare års konstanta kritik av den dåvarande engelskspråkiga kursboken. Kursen Statistik B definieras utifrån kurslitteraturen och föreläsningarna Föreläsningsunderlag kommer alltid att hållas tillgängligt på kurshemsidan

7
Litet om vad kursen handlar om Enkel linjär regressionsanalys Exempel: Försäljning av pizza relaterat till antalet studenter i restaurangens omgivning för 10 slumpmässigt valda restauranger

8
Kan man tänka sig att försäljningen ökar linjärt med antal studenter i omgivningen? Förmodligen! Hur tillförlitlig är den framräknade ekvationen för linjen: y =5x + 60 ? Hur kan vi tolka värdena 5 och 60 i ekvationen? Om vi har en “ny” restaurang med 15000 studenter i omgivningen, vad kan vi förvänta oss att kvartalsförsäljningen blir?

9
Multipel linjär regressionsanalys Exempel: Restider för ett transportföretag relaterade till transportavstånd och antal leveranser för 10 slumpmässigt valda transporter Kan vi kombinera till “ett” samband?

10
Framräknat matematiskt samband: Restid = - 0.869 + 0.0611 Transp.avstånd + 0.923 Leveranser Tillförlitligt? Tolkningar? Prognoser?

11
Index Exempel: fastighetsprisindex, fritidshus, Stockholms län 1975-2005 Hur har värdena på y-axeln räknats fram? Hur kan indexserien användas?

12
Exponentiella modeller och elasticitetssamband Exempel: Befolkningsutveckling i Göteborgs och Bohus län 1805-2000 Är det rimligt med ett linjärt samband här? Hur kan vi räkna fram ett icke-linjärt samband?

13
Exempel: Efterfrågad volym av en viss varugrupp i förhållande till pris Hur kan vi avgöra om varan är priskänslig? Hur kan vi relatera Nationalekonomins modeller till statistiska modeller?

14
Tidsserier Exempel: Antal på arbetsmarknaden sysselsatta kvinnor januari 1995 – mars 2005 Vad för slags variation består data av? Trend? Säsongsmönster? Konjunkturmönster? Hur kan vi prognosticera? 2 år framåt? 10 år framåt?

15
Inte så bra…Bättre?…

16
Enkel linjär regressionsanalys Exempel: En pizzakedja har undersökt försäljningen vid restauranger som ligger i anslutning till högskolecampus. Följande data har sammanställts in från 10 slumpmässigt valda restauranger: RestaurangFörsäljning senaste kvartalAntal studenter vid (i 1000-tals € )campus (i 1000-tal) 1582 21056 3888 41188 511712 613716 715720 816920 914922 1020226
campus (i 1000-tal)")
17
Vi plottar kvartalsförsäljningen mot Antal studenter Försäljningen tycks ha ett positivt samband med Antal studenter

18
Kan sambandet vara linjärt?

19
Den räta linjen? Betyder alla punkter lika mycket? Drar alla som tittar på plotten ungefär samma linje? Försöker man få så många punkter som möjligt att ansluta till linjen? Finns det någon sann linje? Räta linjens ekvation: Kan den utnyttjas här på lämpligt sätt?

20
Blå linje: Bygger enbart på punkten längst t.v. och punkten längs t.h. Grön linje: Bygger på alla punkter utom den längst t.v. och den längst t.h. Rosa linje: Bygger på de fem punkterna längst t.v.

21
Målsättning: Att anpassa en linje till punkterna så att avstånden mellan punkterna och linjen blir så små som möjligt enligt något gemensamt (globalt) mått. Låt y=b 0 +b 1 ·x vara det matematiska uttrycket för den linje som skall anpassas. b 0 =skärningspunkten på y-axeln (interceptet) b 1 =lutningskoefficienten (lutningsparametern) y står alltså för kvartalsförsäljning och x står för antalet studenter (Observera att vi frångår beteckningssättet y=k·x+m.) Kursboken (AJÅ) skriver y=a+b·x, men i föreläsningsunderlagen används genomgående b 0 i stället för a (av internationella skäl) Problemet att lösa är hur vi skall bestämma b 0 och b 1 i det matematiska uttrycket
 b 1 =lutningskoefficienten (lutningsparametern) y står alltså för kvartalsförsäljning och x står för antalet studenter (Observera att vi frångår beteckningssättet y=k·x+m.) Kursboken (AJÅ) skriver y=a+b·x, men i föreläsningsunderlagen används genomgående b 0 i stället för a (av internationella skäl) Problemet att lösa är hur vi skall bestämma b 0 och b 1 i det matematiska uttrycket.")
22
Betrakta avstånden mellan punkterna och den dragna linjen. (Gröna klamrar) Dessa är såväl positiva som negativa
 Dessa är såväl positiva som negativa.")
23
Avståndet mellan en punkt (restaurang) med koordinaterna (x i, y i ) och linjen kan skrivas: y i står alltså för kvartalsförsäljningen x i står för antalet studenter Summan av alla avstånd blir men denna summa blir 0 så fort de negativa avstånden ”tar ut” de positiva även om de faktiska avstånden (absolutavvikelserna) skulle vara mycket stora. Det är alltså inte särskilt vettigt att använda sig av positiva och negativa avstånd. för restaurang i

24
För att förtydliga det här med summatecknet: Det är ganska enkelt att hitta värden på b 0 och b 1 så att detta blir =0, dvs. Så att de positiva och negativa avstånden tar ut varandra. t.e.x b 0 =0, b 1 =9.29 ; b 0 =50, b 1 =5.71 ; b 0 =100, b 1 =2.14 …

25
Hur vore det då att utnyttja absolutavvikelserna: ? (Absolutbeloppet | · | är sådant att t ex | 2|=2 och |2|=2 ) Vi borde då välja b 0 och b 1 så att summan av alla absolutavvikelser blir så liten som möjligt. Fullt tänkbart och vettigt för vissa datamaterial men matematiskt svårt.
 Vi borde då välja b 0 och b 1 så att summan av alla absolutavvikelser blir så liten som möjligt. Fullt tänkbart och vettigt för vissa datamaterial men matematiskt svårt..")
26
Matematiskt enklare blir att välja b 0 och b 1 så att följande summa minimeras: De resulterande värdena på b 0 och b 1 kalla Minsta Kvadrat – skattningarna av linjens parametrar (se längre fram) Hur går detta till?
 Hur går detta till")
27
Låt Dvs. Q är en matematisk funktion av b 0 och b 1. För att minimera denna krävs att vi deriverar Q med avseende på såväl b 0 som b 1, sätter dessa derivator till 0 och löser ut b 0 och b 1 ur det ekvationssystem som då bildas. Matte!!

28
Vi behöver alltså beräkna xy, x 2 samt medeltalen för x och y ur vårt datamaterial: x y x 2 x·y 2 58 4 116 610536 630 8 8864 704 811864 944 12117 144 1404 16137 256 2192 20157 400 3140 20169 400 3380 22149 484 3278 26202 676 5252 140 1300 252821040 Medel 14 130 Den resulterande linjen blir då y=60+5·x

29
60 xx yy y=60+5·x

30
Om alla dessa summor Ur beräknings- och skrivmässig synvinkel är det bra att använda snabbformler och dessutom ha bra beteckningar på ingående summor Vänj er därför vid följande:

31
Notera dock att kursboken (AJÅ) använder sig av ytterligare en formelvariant för b 1 (som skrivs b i AJÅ): Alla formler ger samma värde, men AJÅ motiverar denna formel med att den är enklare beräkningsmässigt. Samma argument kan användas för följande fjärde variant av formeln: Alla formler är helt ekvivalenta. Det handlar egentligen bara om var man placerar n:et

32
Om sambandet mellan y och x är linjärt, dvs. följer en rät linje, gäller detta överallt? Svar: Nej! Endast i det område där vi har observationer.

33
Vad har detta med statistik att göra? Om det finns ett generellt linjärt samband mellan y och x Vi kan knappast ha sådan tur att vi prickar in detta exakt med de 10 observationer vi har. Data utgörs av ett urval. Nytt urval Nya punkter Annan anpassad rät linje y=60+5·x skall ses som en skattning av det bakomliggande generella sambandet, den teoretiska räta linjen

34
Modell: Låt y och x ha ett teoretiskt samband enligt: E (y )= μ y|x = 0 + 1 · x dvs. väntevärdet hos y (eller det genomsnittliga värdet hos y ) beror linjärt av det aktuella värdet hos x.
 beror linjärt av det aktuella värdet hos x..")
35
För varje värde på x tänker vi oss att det finns en (del)population av möjliga värden på y sådan att sambandet stämmer, dvs. att väntevärdet av y är lika med y-värdet i den punkt på linjen som motsvarar x-värdet. Det inses att en anpassad linje b 0 +b 1 ·x kan få många olika utseenden beroende på vilka punkter som fås i urvalet.

36
Korrelation I vardagligt tal hör man ofta resonemang som talar om huruvida två företeelser är korrelerade. Detta sätt att uttrycka sig är något missvisande. Två företeelser kan ha ett samband men att de är korrelerade innebär att detta samband är till stor del linjärt. Ett perfekt linjärt samband mellan två variabler är det starkaste samband som finns. För två sådana variabler y och x betyder det att känner man till den ena så känner man automatiskt till den andra. För ett datamaterial av det slag vi hittills har tagit upp (dvs. n parvisa observationer av två variabler y och x ) mäts graden av linjärt samband med den s.k. korrelationskoefficienten: r antar endast värden mellan –1 och 1. Om r = 0 kan inget linjärt samband sägas finnas (okorrelerade variabler) och om r = +1 eller –1 råder perfekt linjärt samband.
 mäts graden av linjärt samband med den s.k. korrelationskoefficienten: r antar endast värden mellan –1 och 1. Om r = 0 kan inget linjärt samband sägas finnas (okorrelerade variabler) och om r = +1 eller –1 råder perfekt linjärt samband..")
37
Även här finns beräkningstekniskt sett ”enklare” formler för r : Notera likheten mellan b och r, men märk väl att det är två skilda storheter! r mäter alltså graden av linjärt samband medan b anger hur det innehållande linjära sambandet ser ut

38
I vårt exempel blir Jämför detta med b = 5 som ju är ett helt annat värde. Värdet r = 0.95 anger att graden av linjärt samband är mycket hög, näst intill perfekt. Vidare är sambandet positivt, dvs. höga värden hos den ena variabeln åtföljs som regel av höga värden hos den andra och motsvarande för låga värden. Ett negativt värde på r anger ett negativt samband, dvs. höga värden hos den ena variabeln åtföljs som regel av låga värden hos den andra och vice versa.

39
En modell som beskriver sambandet mellan ett enskilt värde y i och ett enskilt värde x i kan nu skrivas y i = 0 + 1 · x i + i (1) där i är en slumpvariabel med väntevärde 0. Vanligast är att anta att i är fördelad N (0, ) 0 + 1 · xi är då det betingade väntevärdet av yi givet att x=xi. kan också skrivas e eller bara kort . Med modellen (1) kan vi förklara varför observationerna inte ligger samlade på en rät linje, medan deras genomsnittliga värden gör det. Man kan visa att statistiskt har då punktskattningarna b 0 och b 1 följande egenskaper (stickprovsfördelningar): där i detta exempel n=10. Räknar vi ut termerna innehållande x-värden får vi
 0 + 1 · xi är då det betingade väntevärdet av yi givet att x=xi. kan också skrivas e eller bara kort . Med modellen (1) kan vi förklara varför observationerna inte ligger samlade på en rät linje, medan deras genomsnittliga värden gör det. Man kan visa att statistiskt har då punktskattningarna b 0 och b 1 följande egenskaper (stickprovsfördelningar): där i detta exempel n=10. Räknar vi ut termerna innehållande x-värden får vi.")
40
Skattning av : I ett ”vanligt” stickprov med observationer y 1, y 2,…, y n skattar vi populationsvariansen, 2 med Här måste vi ersätta med något som följer genomsnittsvärdet hos y då x ändras. Bäst är att sätta in uttrycket för den skattade linjen: Observera att vi här dividerar med n – 2 i stället för n – 1. Orsaken är att vi annars underskattar 2 (Samma skäl som till varför vi tidigare dividerade med n – 1 och inte med n. ) Eftersom vi egentligen skattar en linje och inte använder den teoretiska linjen är det mer korrekt att skriva ekvationen för denna som Det blir då naturligt att förkorta skrivsättet för se2 enligt Termen brukar betecknas e i och kallas residual (avvikelsen mellan observerat värde och anpassat värde) och kan vara såväl positiv som negativ. s e kallas därför ofta residualspridningen och s e 2 residualvariansen
 Eftersom vi egentligen skattar en linje och inte använder den teoretiska linjen är det mer korrekt att skriva ekvationen för denna som Det blir då naturligt att förkorta skrivsättet för se2 enligt Termen brukar betecknas e i och kallas residual (avvikelsen mellan observerat värde och anpassat värde) och kan vara såväl positiv som negativ. s e kallas därför ofta residualspridningen och s e 2 residualvariansen.")
41
x y ŷ i y i - ŷ i (y i – ŷ i ) 2 2 58 70 –12 144 6105 90 15 225 8 88100 –12 144 8118100 18 324 12117 120 –3 9 16137 140 –3 9 20157 160 –3 9 20169 160 9 81 22149 170 –21 441 26202 190 12 144 140 1300 1300 0 1530
 – – – – – – ")
42
De gröna klamrarna visar residualerna e 1, e 2, …, e 10 och det är standardavvikelsen hos dessa som beräknas till s e =13.83

43
Mer terminologi och beräkningsteknik: s e 2 har en mer internationell beteckning. Vanligt är att beteckna Square Sum of Errors. På svenska säger man residualkvadratsumman. (Residual översätts ibland till Error) se2 blir då SSE/(n–2) och denna brukar internationellt även betecknas MSE (Mean Square sum of Errors) Vanligen skriver man också s och s 2 och utelämnar alltså ”e” i beteckningen. För att beräkna SSE behöver man inte gå den ”långa” vägen som vi gjorde tidigare. Man kan visa att De ingående summorna skrivs (enligt ovan) enklare som och sätts in i formeln:
 se2 blir då SSE/(n–2) och denna brukar internationellt även betecknas MSE (Mean Square sum of Errors) Vanligen skriver man också s och s 2 och utelämnar alltså e i beteckningen. För att beräkna SSE behöver man inte gå den långa vägen som vi gjorde tidigare. Man kan visa att De ingående summorna skrivs (enligt ovan) enklare som och sätts in i formeln:.")
44
Med värden i exemplet erhålls: eller snabbare:

45
Vi understryker att summorna har beräkningstekniskt enklare former. Alla dessa kommer att stå i formelsamlingen. Använd dem och inte den mer tidsödande metoden att beräkna samtliga differenser, kvadrater och/eller produkter innan de summeras. “Vanliga” fel: Låt t.ex. n = 3 och x 1 = 1, x 2 = 2, x 3 = 3 samt y 1 = 2, y 2 = 4, y 3 = 5 Testa och upptäck att ovanstående stämmer!

46
Med hjälp av s kan vi beräkna konfidensintervall för 0 1 0 + 1 ·x 0 dvs. väntevärdet hos y då x= x 0 eller annorlunda betecknat Vi kan också testa hypoteser rörande specifika värden hos dessa parametrar. Vidare kan vi beräkna s k prognos- eller prediktionsintervall för det faktiska värdet hos y då x= x 0

47
Exempel: Ett 95% konfidensintervall för 1 beräknas med formeln där t 0.025,n–2 hämtas från en tabell över t-fördelningen med n – 2 frihetsgrader. Observera att vi alltså har en frihetsgrad mindre här jämfört med de test och intervall ni beräknade i grundkursen Med våra data får vi

48
Antag också att vi vill testa följande hypotes: H 0 : 1 =0 motH a : 1 0på 5% nivå dvs. vi vill testa om det överhuvudtaget förekommer något linjärt samband mellan y och x. Alt. 1: Använd det nyss framräknade 95%-iga konfidensintervallet. Om detta inte omfattar värdet 0 kan H0 förkastas på (100-95)%=5% nivå. Intervallet 5.0 1.3 = (3.7, 6.3) omfattar inte värdet 0 och alltså kan H0 förkastas Alt. 2: Använd ett formellt test. Teststorheten blir då där 1,0 är värdet på 1 i nollhypotesen, dvs i vårt fall =0. (Vanligast men det finns situationer då det är ett annat värde.) H 0 förkastas om teststorheten är t 0.0025,n-2 eftersom alternativhypotesen är dubbelsidig. Med våra data: 8.62>2.306 H0 förkastas
%=5% nivå. Intervallet 5.0 1.3 = (3.7, 6.3) omfattar inte värdet 0 och alltså kan H0 förkastas Alt. 2: Använd ett formellt test. Teststorheten blir då där 1,0 är värdet på 1 i nollhypotesen, dvs i vårt fall =0. (Vanligast men det finns situationer då det är ett annat värde.) H 0 förkastas om teststorheten är t ,n-2 eftersom alternativhypotesen är dubbelsidig. Med våra data: 8.62>2.306 H0 förkastas.")
49
Konfidensintervall och test kan också göras för parametern β 0. Formler för detta kommer att finnas i formelsamlingen. Om dock datamaterialet ligger på ett tydligt avstånd från y-axeln blir tolkningen av β0 av liten betydelse. Det linjära sambandet gäller ju bara inom datamaterialets gränser. Antag nu att vi vill skatta väntevärdet av y för ett specifikt värde x 0 hos x, dvs. vi vill skatta x0 kan vara en punkt inom datamaterialets gränser för vilken inga observationer finns. Alternativt: Vi vill skatta det genomsnittliga värdet av y för alla observationer i populationen för vilka x = x 0

50
En väntevärdesriktig punktskattning av blir Kombination av de statistiska egenskaperna hos b0 och b1 Ett 95% konfidensintervall för blir Väntevärdesriktig: Om förfarandet upprepas gång på gång kommer de i genomsnitt att bli = Notera alltså att det är samma t-fördelning som tidigare. Denna bestäms uteslutande av SSE.

51
Antag t ex att vi vill skatta då x 0 =10, dvs. en restaurang vid ett campus med 10000 studenter. (Detta värde finns ju inte representerat bland observationerna, men ligger inom datamaterialets gränser.) Ett 95% konfidensintervall blir då
 Ett 95% konfidensintervall blir då.")
52
Förutom att skatta väntevärdet hos y i en ny punkt kan vi också vilja göra en prognos eller prediktion av det faktiska värdet hos y i denna punkt. Punktprognos: Sammanfaller med punktskattningen av väntevärdet, dvs. Osäkerhet i denna prognos? Prognosfelet kan uttryckas: Detta prognosfel har väntevärde 0 samt en osäkerhetskomponent i själva värdet y0 och en osäkerhetskomponent i prognosen. Variansen för prognosfelet blir ty den nya punkten har ej ingått i beräkningen av prognosen, vilket gör de två variablerna oberoende. y 0 = 0 + 1 · x 0 + 0 Var (y 0 ) = Var ( 0 ) = 2
 = Var ( 0 ) = 2.")
53
Variansen hos prognosen blir (enligt tidigare beräkningar och kombinationer): Om vi skattar 2 med s 2 i variansuttrycken erhålls t. ex. ett 95% osäkerhetsintervall för prognosfelet: ett 95% prognos- eller prediktionsintervall för y 0 : Prognosintervall är inte konfidensintervall och dess bredd blir betydligt större än bredden hos motsvarande konfidensintervall för

54
Ett 95% prognosintervall för y då x 0 =10 blir

55
I den tidigare läroboken (och i formelsamlingen) används ibland följande definition Uttrycket kan nämligen ses som avståndet i x-led från den nya punkten till centrum av alla punkter när man tar hänsyn till att det finns kopplingar mellan punkterna. Detta synsätt underlättar uppställningen av motsvarande intervall vid multipel linjär regression. En något tydligare tolkning av Distance value kommer att ges längre fram.

56
Residualanalys Residualerna e i = y i – ŷ i kan användas till mer än bara variansskattning. De residualer vi erhållit i vår analys är: x y ŷ i e i = y i - ŷ i 2 58 70 –12 6105 90 15 8 88100 –12 8118100 18 12117 120 –3 16137 140 –3 20157 160 –3 20169 160 9 22149 170 –21 26202 190 12

57
Notera att e i = y i - ŷ i = 0 + 1 · x i + i - ( b 0 + b 1 · x ) = ( 0 – b 0 ) + ( 1 - b 1 ) · x i + i i om vi antar att b 0 och b 1 är bra skattningar av 0 och 1. Vi kan förvänta oss att e 1,…, e 10 skall bete sig ungefär som oberoende och N (0, )-fördelade. Oberoende?Normalfördelade?
-fördelade. Oberoende Normalfördelade .")
58
Verkar vara konstant och oberoende av nivån hos y? ŷiŷi eiei

59
Finns det något samband kvar mellan y och x som ej har tagits med i regressionen?

60
”Typiska” Histogram Mot anpassade värden I tidsordning Mot x-variabeln OK Inte OK

61
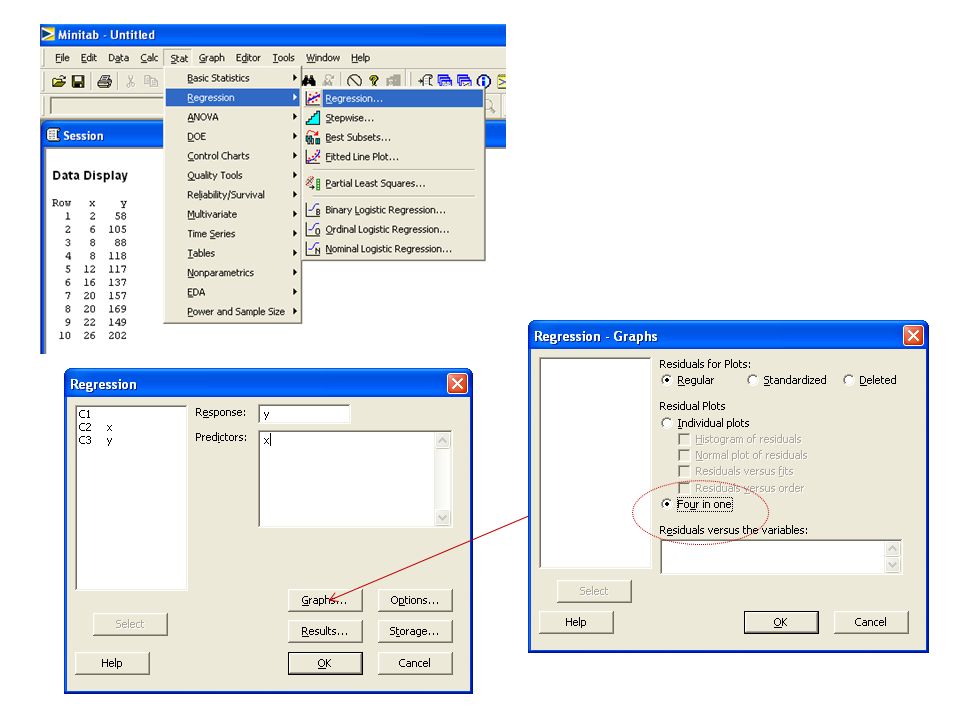
Exempel på datorkörning med Minitab: MTB > print c1 c2 Data Display Row x y 1 2 58 2 6 105 3 8 88 4 8 118 5 12 117 6 16 137 7 20 157 8 20 169 9 22 149 10 26 202

63
y=b 0 +b 1 ·x Tas upp senare i kursen

64
Krav på variabler i regressionsanalys Kan regressionsanalys alltid användas för att beskriva ett samband mellan två variabler y och x ? Nej! Det samband som beskrivs av en regressionsmodell är linjärt i sin konstruktion. Alla koefficienter kan tolkas som en absolut förändring i y-variabeln när x-variabeln ökar med en enhet. Det måste finnas en “mening” med att x-variabeln ökar en enhet och en “mening” i en absolut förändring av y-variabeln.

65
Verkar en ökning av x med en enhet ge i princip samma förändring i y-led överallt i bägge figurerna?

66
y-variabeln måste vidare vara på intervallskala. dvs. det finns ett väldefinierat avståndsmått mellan värdena. T.ex. är avståndet mellan 2 och 4 lika stort som avståndet mellan 5 och 7. Sådant är inte alltid fallet. Tag t.ex. en variabel som utgörs av attityder till en annons. En sådan variabel kanske har graderna 1, 2, 3 och 4, där 1 innebär “gillar inte alls” och 4 innebär “gillar verkligen”. Avståndet mellan 1 och 2 är för denna variabel inte lika stort som avståndet mellan 2 och 3 eller mellan 3 och 4.

67
x-variabeln måste egentligen också vara på intervallskala, men det finns ett undantag: Om variabeln endast kan anta två värden, t.ex. “småföretag” och “storföretag” kan dessa kodas med värden 0 och 1 och variabeln kan användas. Avståndsmåttet har ingen betydelse här eftersom det endast finns två värden. Dock blir tolkningen litet speciell. Det går att öka x med en enhet om nuvärdet är 0, men inte om nuvärdet är 1. Tolkningen av koefficienten blir då följande: Om x = 0 så är y = 0 + , och om x = 1 så är y = 0 + 1 + b 0 blir en skattning av genomsnittet hos y när x = 0 (i exemplet för småföretag) b 0 + b 1 blir en skattning av genomsnittet hos y när x = 1 (i exemplet för storföretag)
 b 0 + b 1 blir en skattning av genomsnittet hos y när x = 1 (i exemplet för storföretag).")
68
Kvadratsummeuppdelning/Variansanalys Låt dvs. ”råvariationen” bland y-värdena får ytterligare en beteckning (Square Sum of Total variation) Tidigare har vi sett att SST inte duger som bas för en skattning av 2 Man kan visa att dvs. SST kan delas upp i två kvadratsummor varav den ena är SSE. Den andra, betecknad SSR, innehåller den del av den totala variationen som inte är slump utan beror på regressionssambandet mellan y och x. SSR står för Square Sum of Regression och det svenska namnet är regressionskvadratsumma. I exemplet från föreläsning med pizzarestaurangerna är SST= 15730 och SSE=1530 SSR=15730 – 1530 = 14200
 Tidigare har vi sett att SST inte duger som bas för en skattning av 2 Man kan visa att dvs. SST kan delas upp i två kvadratsummor varav den ena är SSE. Den andra, betecknad SSR, innehåller den del av den totala variationen som inte är slump utan beror på regressionssambandet mellan y och x. SSR står för Square Sum of Regression och det svenska namnet är regressionskvadratsumma. I exemplet från föreläsning med pizzarestaurangerna är SST= och SSE=1530 SSR=15730 – 1530 =")
69
Förklaringsgrad Den del av SST som utgörs av SSR, dvs. den del av den totala variationen som utgörs av regressionssambandet kallas förklaringsgrad och betecknas r 2, dvs. Ju högre förklaringsgrad, desto bättre lyckas vår skattade modell förklara variationen i data Modellen kan anses vara bra. I exemplet med pizzarestaurangerna blir dvs. 90.3% av den totala variationen i y kan sägas förklaras av sambandet med x. Notera! I den enkla regressionsmodellen är förklaringsgraden = (korrelationskoefficienten) 2 Däremot behöver inte r = kvadratroten ur r2. Det är den bara om sambandet är positivt! r är som tidigare också korrelationskoefficienten
 2 Däremot behöver inte r = kvadratroten ur r2. Det är den bara om sambandet är positivt. r är som tidigare också korrelationskoefficienten.")
70
F-test: Kvadratsummeuppdelningen SST=SSE+SSR kan användas till mer än bra förklaringsgrad. Tidigare har vi tagit upp begreppet frihetsgrader har n 1 frihetsgrader ty om n 1 av termerna i summan är kända så kan man räkna ut den n:e. Motsvarande argument SSE har n 2 frihetsgrader I kvadratsummeuppdelningen SST=SSE+SSR gäller att antalet frihetsgrader till vänster om likhetstecknet skall vara samma som till höger SSR har (n 1) (n 2) = 1 frihetsgrad
 (n 2) = 1 frihetsgrad.")
71
Vi har tidigare definierat MSE=SSE/(n 2) MSE är en medelkvadratsumma och erhålls alltså genom att dividera SSE med dess frihetsgrader Motsvarande definierar vi då MSR=SSR/1 (= SSR ) Betrakta åter hypotesprövningen H 0 : 1 =0 H a : 1 0 Om H0 är sann kan man visa att kvoten MSR/MSE får en regelbunden sannolikhetsfördelning över alla tänkbara stickprov av data. Fördelningen brukar kallas F-fördelning. Fördelningen kännetecknas av att den alltid är över positiva värden på x-axeln. (Just i vårt exempel med 1 frihetsgrad i SSR börjar den dock inte i 0)
.")
72
Om nollhypotesen är sann skall vi alltså få ett värde på MSR/MSE som ligger väl i linje med denna fördelning. Om nollhypotesen (H 0 : 1 =0 ) inte är sann: Det finns ett regressionssamband mellan y och x Förklaringsgraden borde vara hyfsat hög vilket den blir om SSR utgör en stor del av SST. (SST=SSE+SSR ) Kvoten MSR/MSE borde bli högre än vad den är om inget regressionssamband finns. Nollhypotesen bör förkastas om värdet hos MSR/MSE ligger ”långt ut” i den högra svansen av F-fördelningen Man jämför alltså MSR/MSE med ett tabellvärde hämtat ur F-förd. F-fördelningen bestäms av frihetsgraderna hos de två kvadratsummorna, i exemplet med pizzarestaurangerna blir de 1 resp. 10 – 2 = 8 F 1,8 -fördelning
 inte är sann: Det finns ett regressionssamband mellan y och x Förklaringsgraden borde vara hyfsat hög vilket den blir om SSR utgör en stor del av SST. (SST=SSE+SSR ) Kvoten MSR/MSE borde bli högre än vad den är om inget regressionssamband finns. Nollhypotesen bör förkastas om värdet hos MSR/MSE ligger långt ut i den högra svansen av F-fördelningen Man jämför alltså MSR/MSE med ett tabellvärde hämtat ur F-förd. F-fördelningen bestäms av frihetsgraderna hos de två kvadratsummorna, i exemplet med pizzarestaurangerna blir de 1 resp. 10 – 2 = 8 F 1,8 -fördelning.")
73
Vidare har vi i exemplet MSR = 14200/1= 14200 och MSE= 1530/8=191.25 MSR/MSE=14200/191.25 72.25 Statistical table of F distribution, alpha = 0.05 http://www.statsoft.com/textbook/sttable.html#f05, 2009-10-30 Kritisk gräns blir 5.32 72.25 > 5.32 H 0 förkastas på 5% nivå










 Multipel regression Kap 11.3 A.Man har en kvantitativ responsvariabel som är linjärt relaterad till en/flera kvantitativa förklarande.>")




 Tidsserier Kap 13.1 Man har en kvantitativ responsvariabel som mäts vid olika tidpunkter. 1.>")





