Schedule F6: Segmentation and Clustering F7: Multispectral Images (Sune Svanberg) F8: Segmentation and Fitting F9: Segmentation, Recognition and Classification (Kalle Åström) F10: Statistical Image Analysis (Finn Lindgren) F11: Computer Vision …
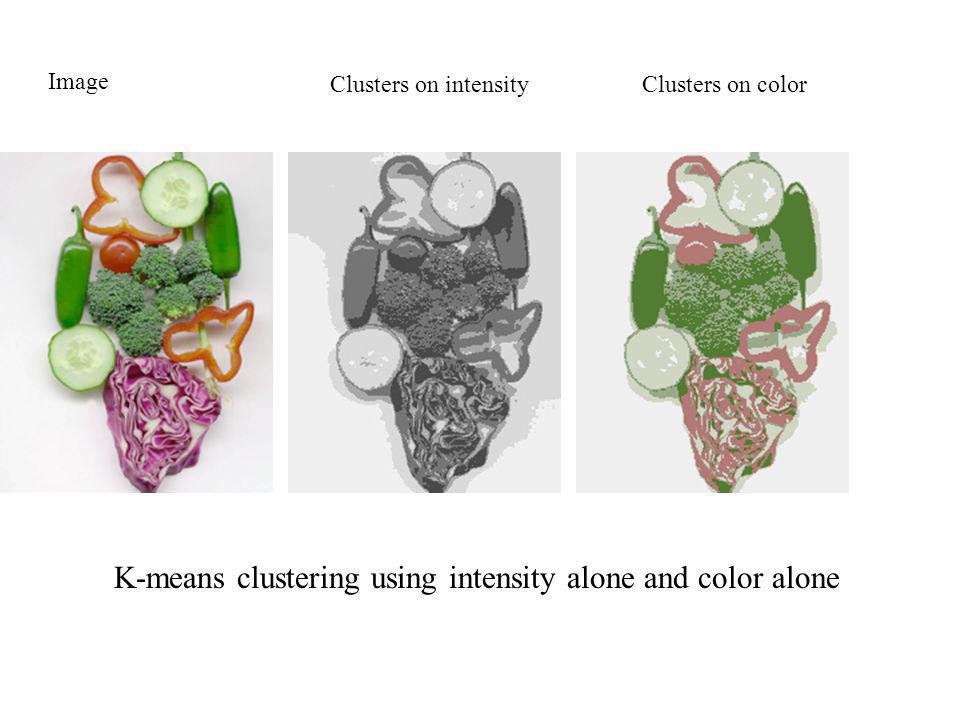
K-means clustering using intensity alone and color alone Image Clusters on intensityClusters on color
K-means using color alone, 11 segments Image Clusters on color
Results of Two-Class Segmentation P. Strandmark, F. Kahl, Optimizing Parametric Total Variation Models,Optimizing Parametric Total Variation Models to appear, International Conference on Computer Vision, Sep., Kyoto, Japan 2009.
RANSAC (RANdom SAmple Consensus) 1.Slumpmässigt välj minimal delmängd av datapunkter för att anpassa modellen (ett sampel) 2.Punkter med avstånd mindre än en tröskel t av modellen är en consensus-mängd. Storleken av mängden är modellens stöd 3.Repetera för k sampel; modell med största stöd är den med “bästa” robusta anpassningen –Punkter med avstånd mindre än t är inliers –Anpassa sedan slutgiltiga modellen till alla inliers Två sampel Och deras stöd för linje-anpassning från Hartley & Zisserman
RANSAC : Hur många iterationer? Hur många iterationer behövs? Antag w är andelen inliers. n punkter, ett sampel, behövs för att definiera en hypotes (2 för linjer) k iterationer. Sannolikheten att ett sampel av n punkter är korrekt: Sannolikheten att alla sampel misslyckas är: Välj k så stort att den önskade misslyckande-frekvensen är uppfylld.
RANSAC: Beräknat k ( p = 0.99 ) Sampel storlek Andelen outliers N 5%10%20%25%30%40%50% från Hartley & Zisserman
Efter RANSAC RANSAC delar data i inliers och outliers, och även ett estimat på modellparametrar Förbättra detta estimat med alla inliers (t.ex. med minstakvadrat metoden) Detta kan ändra inlier-mängden så upprepa klassificering av inlier- resp. outlier-mängder från Hartley & Zisserman