Ladda ner presentationen
1
Prognoser Prognoser i tidsserier: ”Gissa” ett framtida värde i tidsserien Skillnad gentemot prognoser i regression: Det framtida värdet tillhör inte dataområdet. Syftet med en prognosmodell är att göra prognos, inte att förklara det historiska skeendet. Modeller för prognoser behöver inte vara korrekta ur ekonomisk-teoretisk synvinkel. Sunt förnuft i kombination med effektiv matematik ger i regel de bästa prognoserna.

2
Exempel 1: Om utomhustemperaturen under två dagar är c:a -20°C är en förnuftiga prognos att temperaturen under nästkommande dag nog kan vara mellan -15 °C och -25 °C . Med mer kunskap om meteorologi och insamlande av information runt luftfuktighet, vindar, tryckförändringar m m kan dock en precisare prognos med fysikaliska modeller räknas fram. Blir den bättre? En kombination av vad meteorologerna säger och vad man själv tror resulterar förmodligen i en tillfredsställande prognos: Ställ in långfärdsskridskoturen i morgon!

3
Exempel 2: En historisk studie av försäljningen av satellit-TV-abonnemang visar en genomsnittlig ökning med ungefär 3% per år de senaste tre åren. Vidare har den genomsnittliga försäljningen varit lägre i maj än i september. Om man i augusti innevarande år vill göra en prognos av försäljningen i september kan man skriva upp den genomsnittliga årsförsäljningen föregående år med (9/12)3% (eftersom det i september har gått 9 månader sedan föregående år) multiplicera eller addera en faktor/term som motsvarar september månads avvikelse från genomsnittet. ev. kan man också göra en bedömning av konjunkturläget och justera prognosen efter detta.
3% (eftersom det i september har gått 9 månader sedan föregående år) multiplicera eller addera en faktor/term som motsvarar september månads avvikelse från genomsnittet. ev. kan man också göra en bedömning av konjunkturläget och justera prognosen efter detta.")
4
Man kan också: sätta sig ned och resonera om hur man tror att försäljningen kommer att bli i september, baserat på diverse personers individuella känslor om hur försäljningsutvecklingen ser ut. Vad verkar mest förnuftigt? Kanske en kombination?

5
Ett klassiskt exempel inom prognosticering är aktiekursförändring
Jakten på bra prognosmodeller för kommande dags aktiekurs kan liknas vid alkemisternas försök att på artificiell väg framställa guld. Ingen av de hittills gjorda försöken har lyckats! Varför? Ingen ekonomisk eller statistik modell har lyckats förklara den variation i aktiekurs som finns från dag till dag. Det mesta ”hamnar i ”. Bästa prognos hittills av morgondagens aktiekurs är dagens kurs, s k persistensprognos . …och är inte detta egentligen ganska sunt? Obs! Aktieportföljer är något vars värdeförändring är lättare att prognositicera

6
Varför skall vi då lära oss om prognosmodeller?
Modellerna hjälper till med att ta hand om den variation, som trots allt kan ordnas in i en modell. I många fall kan inte olika subjektiva uppfattningar samlas i en enda prognos, då krävs något objektivt. I flera fall blir de modellbaserade prognoserna bra och bättre än alla konkurrerande alternativ. Engelskspråkig term: forecasting Svenska språket använder termerna prognos och prediktion, men skulle kanske ha bruk av termen framåtskrivning

7
Statistiska prognosmodeller:
Anpassad modell för tidsserieregression kan framåtskrivas Klassisk modell för komponentuppdelning kan framåtskrivas beträffande trend och säsong, i mer subjektiv anda beträffande konjunktur Exponentiella utjämningsmetoder: Enkel exponentiell utjämning Dubbel exponentiell utjämning (Holt’s metod) Winters’ metod kan ta hand om de flesta komponenterna i en tidsserie utan att kräva en historiskt anpassad modell. 4. Autoregressiv modellering av tidsserien ger såväl historisk och nulägesbeskrivning som en användbar modell för prognoser, men är matematiskt svårare.
 Winters’ metod. kan ta hand om de flesta komponenterna i en tidsserie utan att kräva en historiskt anpassad modell. 4. Autoregressiv modellering av tidsserien ger såväl historisk och nulägesbeskrivning som en användbar modell för prognoser, men är matematiskt svårare.")
8
Enkel exponentiell utjämning
Bygger på tanken att den studerade tidsserien varken innehåller trend-eller säsongskomponenter, t ex årlig försäljning av bildäck Tänkbar modell: yt=0 + t Modellen skall dock inte ses som statisk utan vi kan tillåta att nivån (0 ) kan ändras, dock inte enligt någon typisk trendstruktur. Enkel exponentiell utjämning innebär att man använder historiska data för att ”jämna ut” serien och därmed plocka bort den rent slumpmässiga variationen. Vid utjämningen kan man låta gamla värden och nyare värden spela olika stora roller. Den utjämnade serien framskrivs efter det sista värdet.
 kan ändras, dock inte enligt någon typisk trendstruktur. Enkel exponentiell utjämning innebär att man använder historiska data för att jämna ut serien och därmed plocka bort den rent slumpmässiga variationen. Vid utjämningen kan man låta gamla värden och nyare värden spela olika stora roller. Den utjämnade serien framskrivs efter det sista värdet.")
9
Beteckna de tillgängliga historiska observationerna y1,y2,…yT
Inför följande uppdateringsmodell: dvs vi har här infört termen l(t) som anger det utjämnade värdet vid tidpunkt t är den s k utjämningskonstanten eller utjämningsparametern (smoothing parameter). 0 1 Med ett lågt värde på (nära 0) kommer de tidigare värdena i serien att spela en större roll än de senare Serien blir mer utjämnad (mer lik ett medelvärde av samtliga observationer) Med ett högt värde på kommer de senare värdena i serien att spela en större roll än de tidigare Serien blir mindre utjämnad och l(t) kommer i högre grad att fånga upp de successiva förändringarna i tidsserien.
 som anger det utjämnade värdet vid tidpunkt t. är den s k utjämningskonstanten eller utjämningsparametern (smoothing parameter). 0 1. Med ett lågt värde på (nära 0) kommer de tidigare värdena i serien att spela en större roll än de senare Serien blir mer utjämnad (mer lik ett medelvärde av samtliga observationer) Med ett högt värde på kommer de senare värdena i serien att spela en större roll än de tidigare Serien blir mindre utjämnad och l(t) kommer i högre grad att fånga upp de successiva förändringarna i tidsserien.")
10
Som prognos för ett framtida värde (vilket som helst!) används:
Uppdateringsformeln kallas rekursionsformel och ger vid handen två viktiga frågor: Hur skall vi välja ? Var skall vi börja, dvs vilket värde skall vi välja på l0? Valet av är mer invecklat och får ofta lösas med ”trial-and-error”. anger antal tidssteg efter tidpunkten T och kallas på engelska lead.

11
Många historiska värden:
Valet av l0 kan göras på litet olika sätt beroende på tillgången till historiska data: Många historiska värden: Använd 10-50% av de historiska värdena och beräkna ett medelvärde av dessa. Detta medelvärde är en skattning av 0 i modellen och blir också det värde vi sätter l0 till. Låt y1 vara endera den första observationen i det resterande datamaterialet och börja utjämningen från denna. den första observationen i hela datamaterialet och börja utjämningen från denna. Ett fåtal historiska värden: Använd samtliga historiska data och beräkna ett medelvärde av dessa. Detta medelvärde är en skattning av 0 i modellen och blir också det värde vi sätter l0 till. Låt y1 vara den första observationen i hela datamaterialet och börja utjämningen från denna.

12
Exempel: Försäljning av dagligvaror i USA
Year Sales values

13
Tidsserieplott Med annan skala på y-axeln

14
Antag modellen: Skatta β0 med medelvärdet av de första 8 observationerna i tidsserien Låt l0= =146.75

15
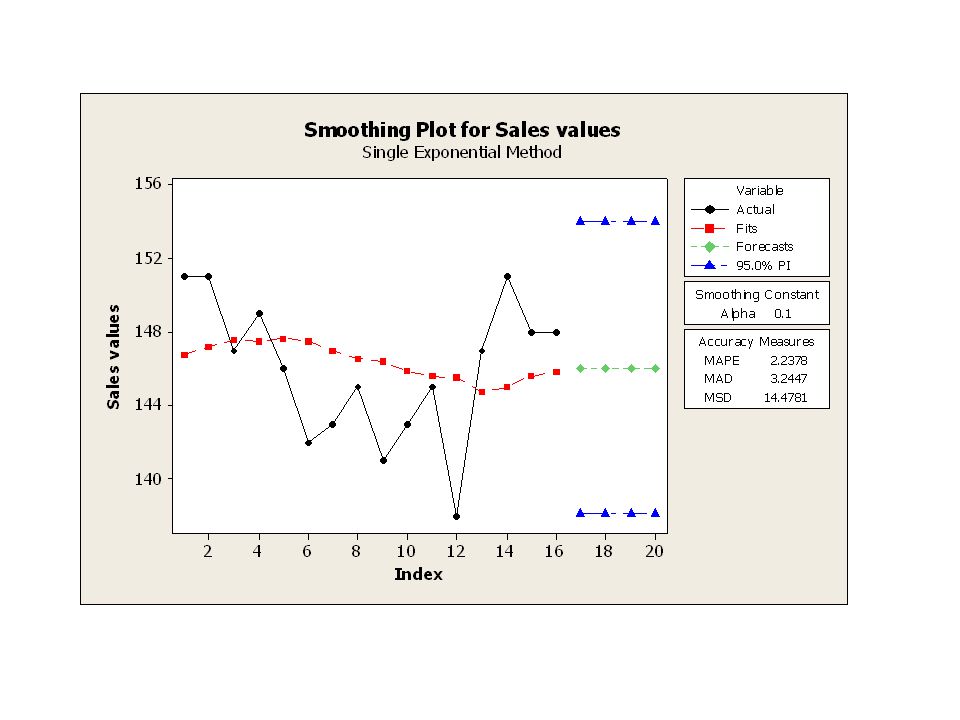
Antag först att försäljningen är ganska stabil, dvs, under den studerade perioden antas inte genomsnittsvärdet β0 ändra sig nämnvärt. Välj ett relativt lågt värde på . Detta innebär att de tidigare värdena i serien kommer att spela en större roll i prognoserna än de senare. Vi låter =0.1 Vi använder nu uppdateringsformeln, som egentligen uppdaterar skattningen av β0. Vi låter vårt y1 här vara det första värdet i tidsserien.

17
Prognoser

18
Analys med hjälp av Minitab
StatTime SeriesSingle Exp Smoothing…

19
Year T Sales val. lT yT - lT Forecasts
,750 4,25000 * ,175 3,82500 * ,558 -0,55750 * ,502 1,49825 * ,652 -1,65158 * ,486 -5,48642 * ,938 -3,93778 * ,544 -1,54400 * ,390 -5,38960 * ,851 -2,85064 * ,566 -0,56557 * ,509 -7,50902 * ,758 2,24188 * ,982 6,01770 * ,584 2,41593 * ,826 2,17433 * ,043 ,043 ,043 ,043

21
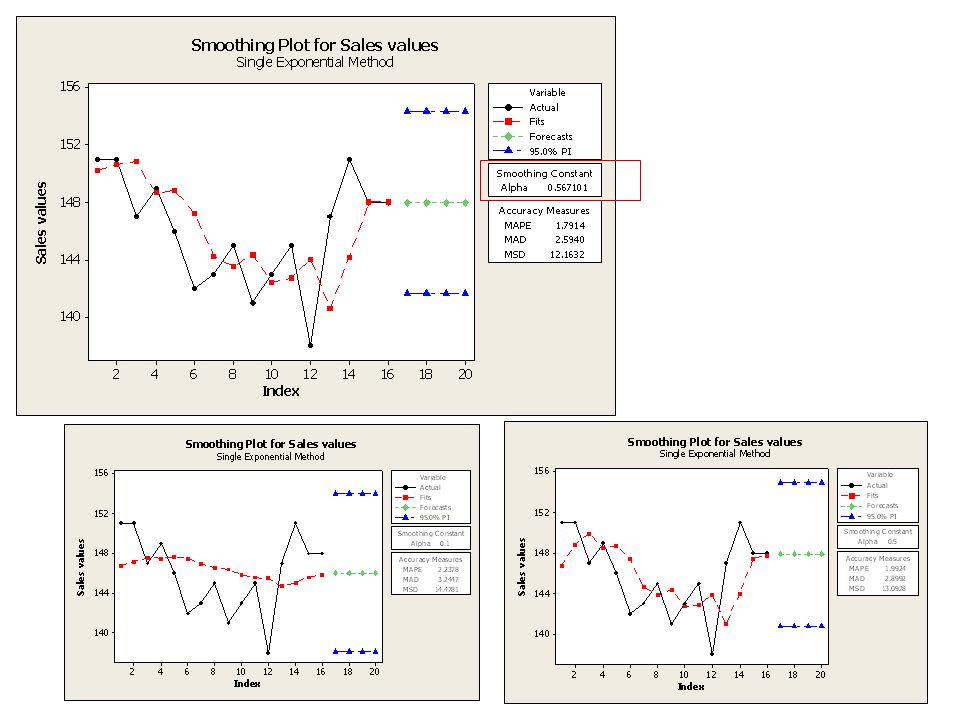
Antag nu att försäljningsvärdena är mindre stabila, dvs
Antag nu att försäljningsvärdena är mindre stabila, dvs. under den studerade perioden kan β0 tänkas ändra sig Låt vara relativt stor, vilket innebär att senare observationer får större betydelse i prognosen. Låt =0.5

22
Ett alternativ kunde vara att successivt ändra värdet på beroende på hur utjämningen blir. Det utjämnade värdet i en tidpunkt utgör ju prognosen av nästa tidpunkt och via jämförelse med det verkliga värdet denna tidpunkt kan man se hur bra det går. Ett annat och kanske rimligare alternativ är att göra uppdateringen med olika och sedan välja det som ger bäst successiva prognoser. Det senare alternativet finns inbyggt i Minitab’s procedur:

24
Dubbel exponentiell utjämning
Data antas här innehålla en linjär trend. Modell: I AJÅ (och i Minitab) används en metod med två utjämningsparametrar och (Holt’s metod): Uppdateringsschema: Prognoser:
 används en metod med två utjämningsparametrar och (Holt’s metod): Uppdateringsschema: Prognoser:")
25
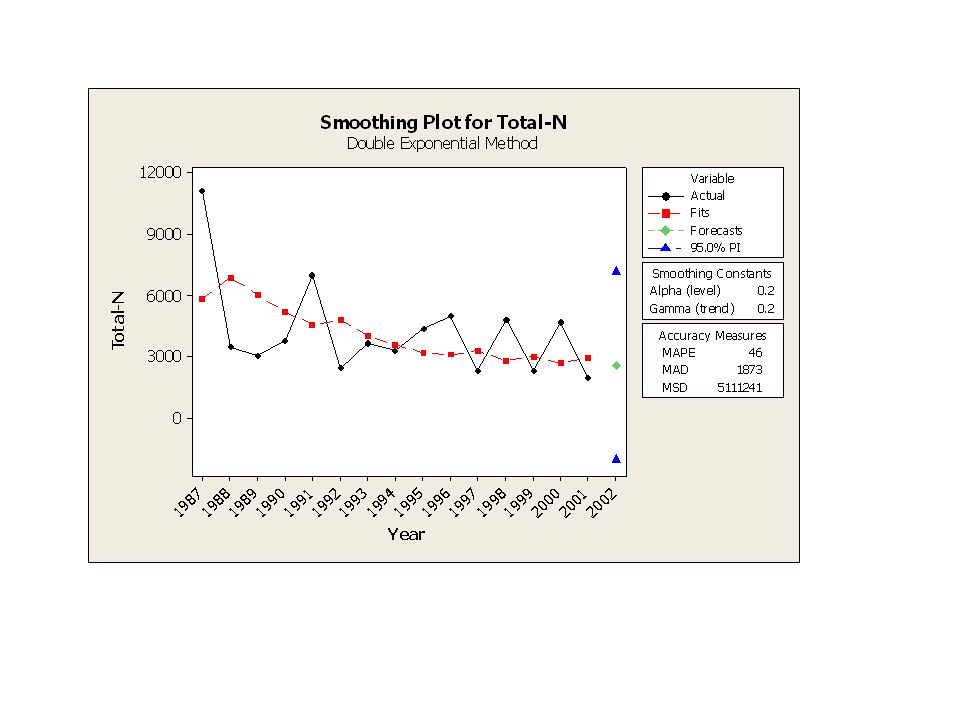
Exempel: Miljöstatistik!
Nedanstående diagram visar koncentrationen i juli månad av kväve i alla dess tänkbara former i Råån vid Helsingborg, åren Diagrammet tyder på en nedåtgående trend. Vad kan värdet i juli 2002 tänkas bli?

26
StatTimes SeriesDouble Exp Smoothing…
Två utjämningspara-metrar Holt-Winters’ metod Prognos i en tidpunkt begärs Vill man ha sina prognoser beräknade efter sista värdet i tillgängliga data låter man denna vara tom

27
Double Exponential Smoothing
Data Total-N Length 15 Smoothing Constants Alpha (level) 0.2 Gamma (trend) 0.2 Accuracy Measures MAPE MAD MSD Forecasts Period Forecast Lower Upper
 0.2. Gamma (trend) 0.2. Accuracy Measures. MAPE 46. MAD MSD Forecasts. Period Forecast Lower Upper")
29
Exponentiell utjämning av tidsserier med trend och säsong:
(Holt-)Winters’ additiva metod (Holt-)Winters’ multiplikativa metod Bägge metoderna använder tre utjämningsparametrar , , för nivå, lutning och säsongssvängning Val av metod görs enligt samma principer som vid klassisk komponentuppdelning
Winters’ additiva metod. (Holt-)Winters’ multiplikativa metod. Bägge metoderna använder tre utjämningsparametrar , , för nivå, lutning och säsongssvängning. Val av metod görs enligt samma principer som vid klassisk komponentuppdelning.")
30
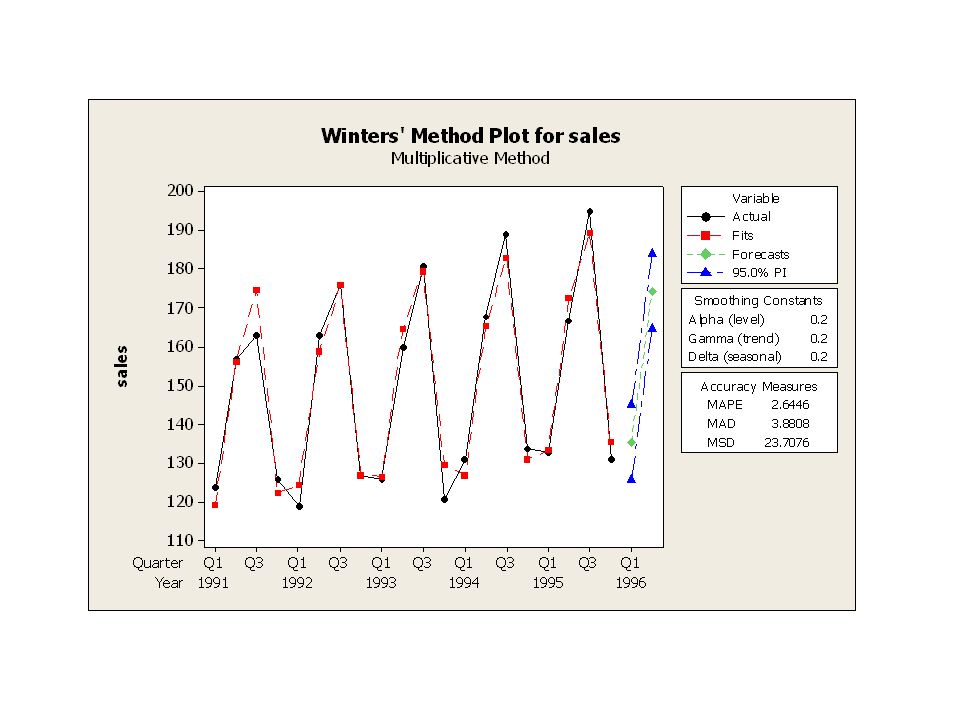
Exempel: Kvartalsvisa försäljningsdata
year quarter sales

31
StatTime SeriesWinters’ Method…
Ingen optimeringsmöjlig-het här

32
Winters' Method for sales
Multiplicative Method Data sales Length 20 Smoothing Constants Alpha (level) Gamma (trend) Delta (seasonal) 0.2 Accuracy Measures MAPE MAD MSD Forecasts Period Forecast Lower Upper Q1/ Q2/
 0.2. Gamma (trend) 0.2. Delta (seasonal) 0.2. Accuracy Measures. MAPE MAD MSD Forecasts. Period Forecast Lower Upper. Q1/ Q2/")
34
Exempel Nyregistrerade bilar

35
Multiplikativ modell Additiv modell

36
Med användande av Minitab’s komponentuppdelning, multiplikativ metod:





















 och ordo>")
