Ladda ner presentationen
Presentation laddar. Vänta.

1
Tidsserieanalys Exempel: Vilka särdrag har tidsseriedata? Varför behövs nya metoder?

2
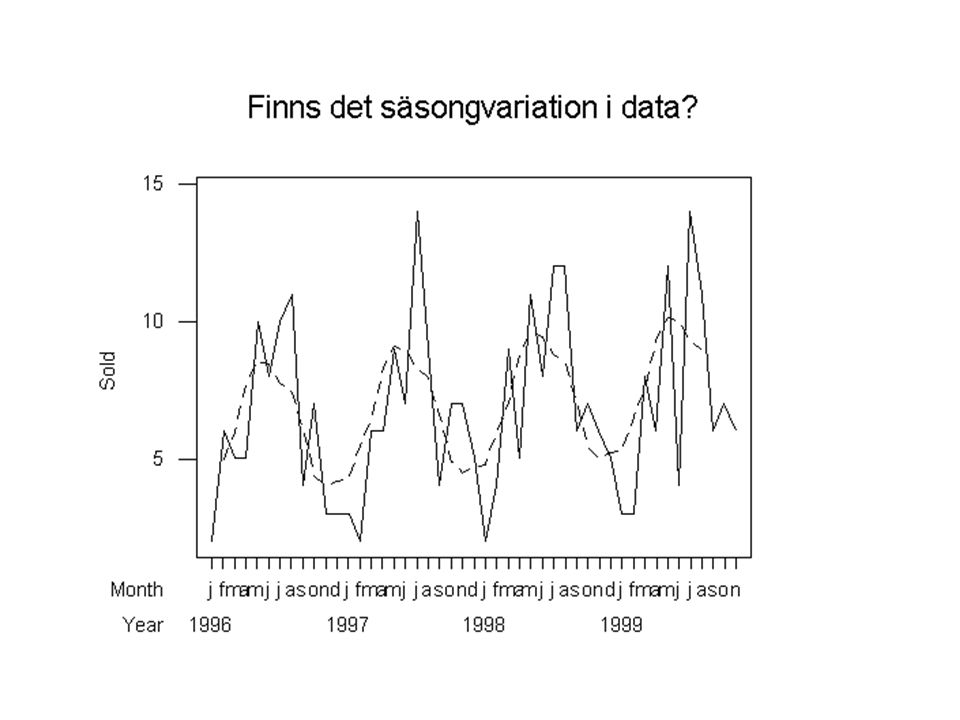
Vilka särdrag har tidsseriedata? Varför behövs nya metoder?
Observationerna är inte oberoende, eftersom det finns ett beroende i tiden Observationerna ger ett mönster över tiden en trend: fallande eller stigande värden med tiden en periodisk variation över en tidsperiod av bestämd längd (säsongseffekter eller liknande)
")
3
Exempel på tidsseriedata
Olika typer av ekonomiska data: Arbetslöshetssiffror Försäljningsvärden Konsumentprisindex och andra index Export- och importmängder Miljömätdata: Fosforhalt i havsvattenbassänger Ozonhalt i luftrummet över en storstad Medicinska data: Antal fall av viss sjukdom (influensa, påssjuka ...)
")
6
Tidsserieregression:

7
sold time month x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11
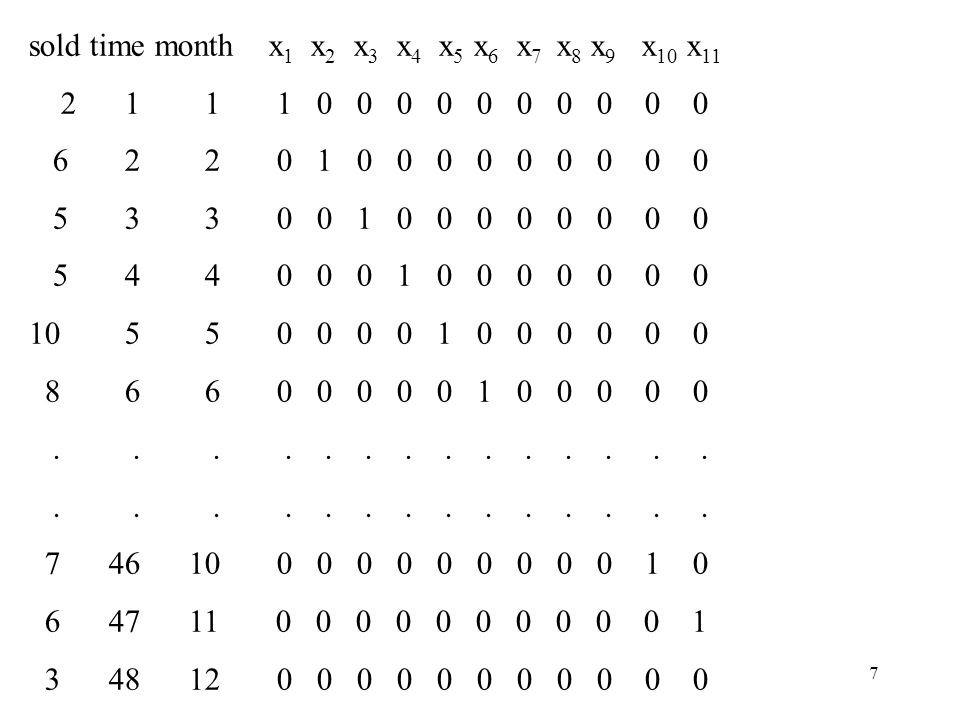
8
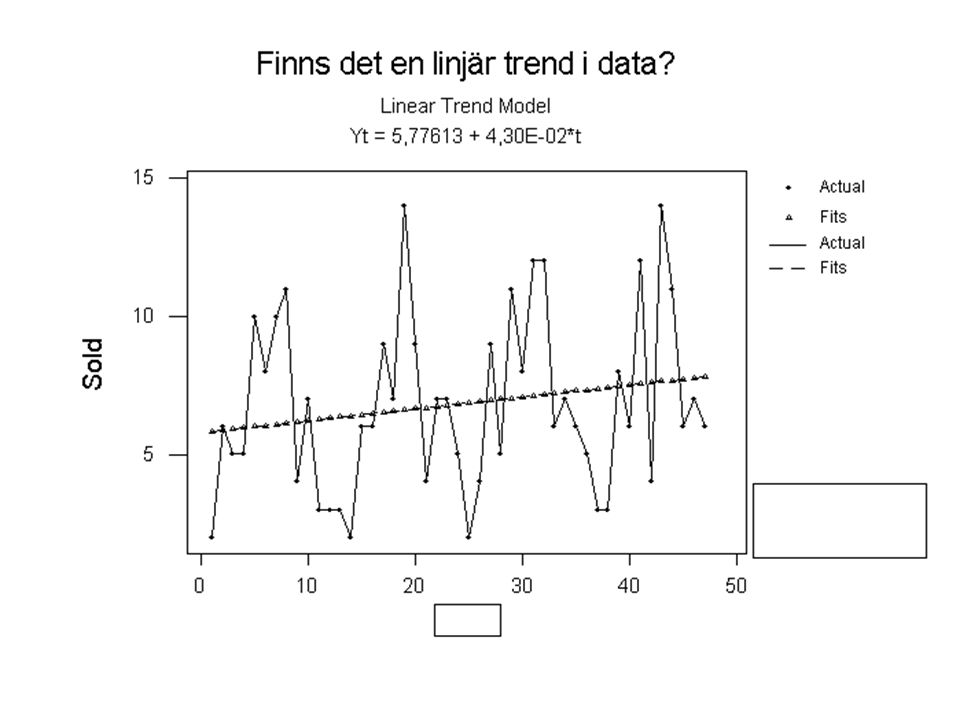
Tidsserieregression med enbart en linjär trend.

9
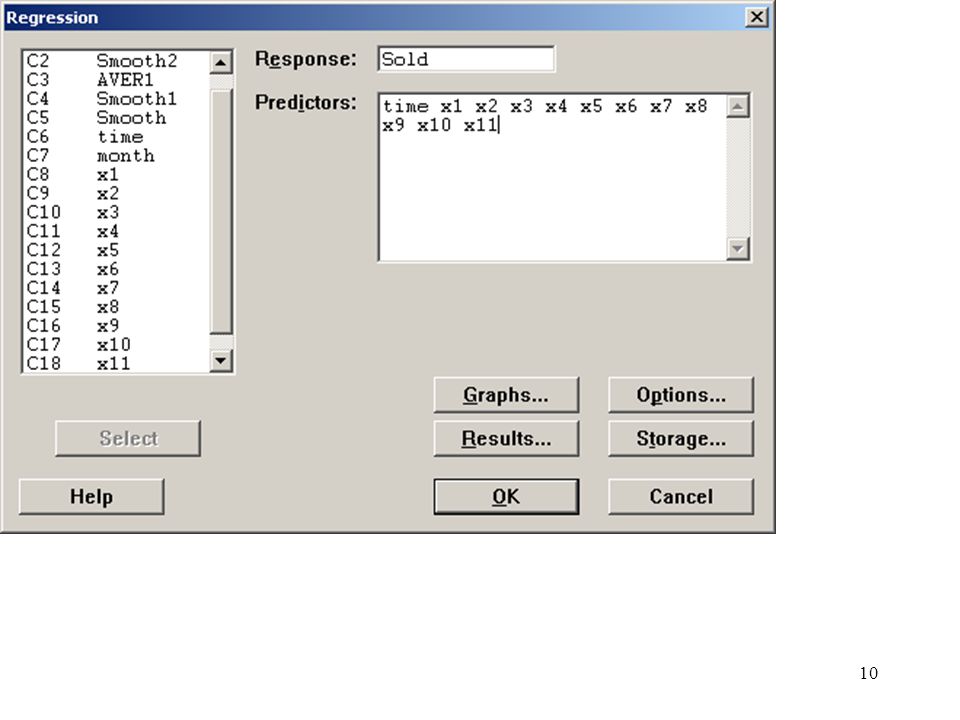
Tidsserieregression fungerar statistiskt som vanlig regression.
Regression Analysis The regression equation is Sold = 5,78 + 0,0430 time Predictor Coef StDev T P Constant , , , ,000 time , , , ,215 S = 3, R-Sq = 3,4% R-Sq(adj) = 1,2% Analysis of Variance Source DF SS MS F P Regression , , , ,215 Residual Error , ,12 Total ,28 Tidsserieregression fungerar statistiskt som vanlig regression.
 = 1,2% Analysis of Variance. Source DF SS MS F P. Regression 1 16,00 16,00 1,58 0,215. Residual Error ,27 10,12. Total ,28. Tidsserieregression fungerar statistiskt som vanlig regression.")
11
Regression Analysis The regression equation is Sold = 3,65 + 0,0285 time - 1,69 x1 - 0,47 x2 + 2,75 x3 + 1,22 x4 + 6,20 x5 + 2,42 x6 + 8,14 x7 + 6,36 x8 + 0,58 x9 + 2,55 x10 + 1,02 x11 Predictor Coef StDev T P Constant , , , ,000 time , , , ,063 x , , , ,109 x , , , ,651 x , , , ,011 x , , , ,241 x , , , ,000 x , , , ,024 x , , , ,000 x , , , ,000 x , , , ,575 x , , , ,018 x , , , ,326 S = 1, R-Sq = 87,0% R-Sq(adj) = 82,4% Analysis of Variance Source DF SS MS F P Regression , , , ,000 Residual Error , ,801 Total ,277
 = 82,4% Analysis of Variance. Source DF SS MS F P. Regression ,031 34,169 18,97 0,000. Residual Error 34 61,246 1,801. Total ,277.")
12
Tolkning av parametrar:
Predictor Coef StDev T P Constant , , , ,000 time , , , ,063 x , , , ,109 x , , , ,651 x , , , ,011 x , , , ,241 x , , , ,000 x , , , ,024 x , , , ,000 x , , , ,000 x , , , ,575 x , , , ,018 x , , , ,326 Tolkning av parametrar: Antal sålda hus ökar i genomsnitt med 0,0285 enheter per tidsenhet (månad) I januari säljs det färre hus (-1.69 hus) jämfört med december, i mars säljs det fler hus (+ 2.75).... (observera att december är basperioden, eftersom dummy- variabeln för december inte finns med – decembernivån är alltså inbakad i konstanten)
 I januari säljs det färre hus (-1.69 hus) jämfört med december, i mars säljs det fler hus (+ 2.75).... (observera att december är basperioden, eftersom dummy- variabeln för december inte finns med – decembernivån är alltså inbakad i konstanten)")
13
Inferens, som konfidensintervall, prognosintervall, t-test, F-test, partiellt F-test... kan göras på samma sätt som i vanlig regressionsanalys. Residualanalys bör göras för att kontrollera om villkoren för regression är uppfyllt: Oberoende residualer Normalfördelade residualer (för att kunna lita på testen) Residualer med konstant varians (inga strutmönster)
 Residualer med konstant varians (inga strutmönster)")
14
Antagandet om oberoende residualer är ofta inte uppfyllt när det gäller tidsseriedata. Det kan också vara svårt att kolla detta antagande visuellt.

15
Enklare att se om observationerna är sammanbundna
Enklare att se om observationerna är sammanbundna. Här ser man tydligt att en negativ residual vanligtvis följs av en positiv residual och tvärtom. Detta är ett tecken på autokorrelation.

16
Statistiskt test för att kontrollera om residualerna är oberoende: Durbin-Watson-test
Durbin-Watson-testet bedömer om autokorrelation (eller seriell korrelation) förekommer bland residualerna: Corr(et,et-1) Vi skiljer mellan positiv autokorrelation och negativ autokorrelation
 förekommer bland residualerna: Corr(et,et-1) Vi skiljer mellan positiv autokorrelation och negativ autokorrelation.")
17
Negativ autokorrelation
Positiv autokorrelation

18
Durbin-Watson-test testvariabeln: I vårt exempel: Durbin-Watson
statistic = 2.66

19
Vi kan testa nollhypotesen:
H0: Det finns ingen autokorrelation i residualerna Om d > dU,/2 eller (4 – d ) > dU,/2 Ingen signifikant autokorrelation, H0 kan ej förkastas Om d < dL,/ Signifikant positiv autokorrelation Om (4 – d ) < dL,/2 Signifikant negativ autokorrelation Om dL,/2 d dU,/2 och dL,/2 (4 – d ) dU,/2 Inget uttalande kan göras
 > dU,/2. Ingen signifikant autokorrelation, H0 kan ej förkastas. Om d < dL,/2 Signifikant positiv autokorrelation. Om (4 – d ) < dL,/2 Signifikant negativ autokorrelation. Om dL,/2 d dU,/2 och dL,/2 (4 – d ) dU,/2. Inget uttalande kan göras.")
20
Om det inte finns någon autokorrelation i residualerna så kommer d att ligga nära 2.
En approximativ kontroll kan göras genom att se om d är lägre än 1 eller högre än 3 Då finns autokorrelation i residualerna.

21
Vissa tidsserier har en så kallad exponentiell trend:
Modell: Modellen kallas i boken ’growth curve model’ och jag har gått igenom de här modellerna i förra föreläsningen (avsnittet om exponentiella modeller).
.")
22
Klassisk komponentuppdelning:
Multiplikativ modell: Additiv modell: där TRt=Trendkomponenten SNt=Säsongkomponenten CLt=Cykliska komponenten IRt=Slumpkomponenten

23
Trendkomponenten TR står för en (ofta) linjär funktion av tiden t
Säsongkomponenten SN består av ett värde per säsong, som uttrycker skillnaden mellan denna säsong och årsgenomsnittet (jämför säsongsdummies) Cykliska komponenten CL står för en oregelbunden funktion som avspeglar konjunktursvängningar, alltså i form av en cykel. Slumpkomponenten är resten av variationen som är helt oregelbunden och som inte kan förklaras.
 Cykliska komponenten CL står för en oregelbunden funktion som avspeglar konjunktursvängningar, alltså i form av en cykel. Slumpkomponenten är resten av variationen som är helt oregelbunden och som inte kan förklaras.")
24
Multiplikativ eller additiv modell?
Multiplikativ modell: Modellen används om säsongssvängningarna ökar med ökat nivå i serien. För ekonomiska data brukar denna modell ofta vara bäst. Additiv modell: Fungerar vid mer stabila tidsserier där säsongssvängningarna ej beror av nivån.

25
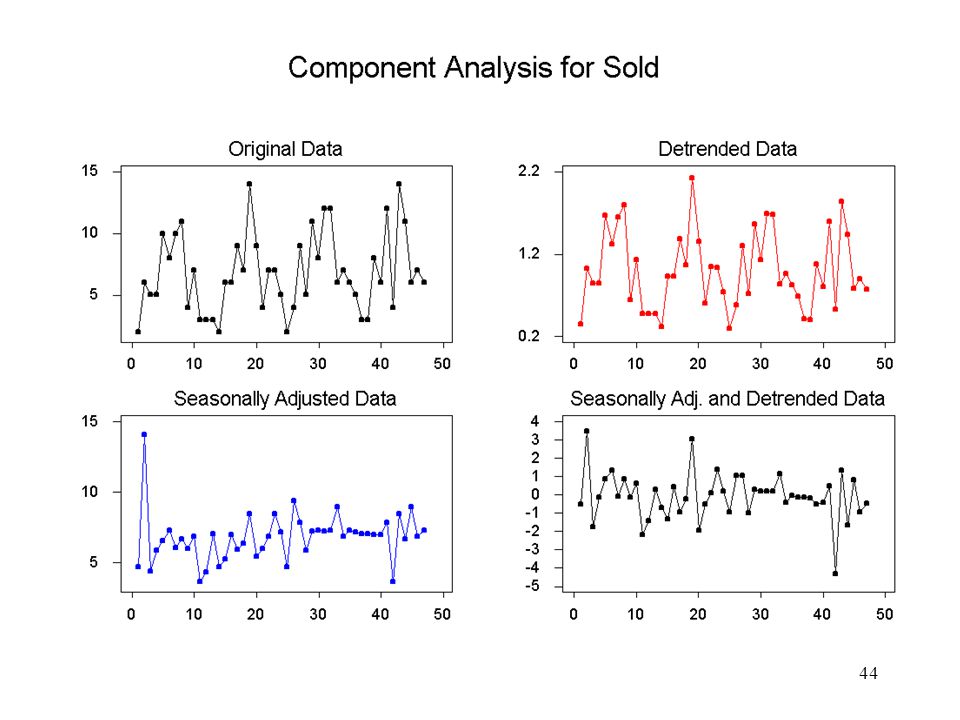
Skattning av komponenter, termer
Säsongrensning: Borttagandet av säsongsvariation yt - SNt i den additiva modellen yt / SNt i den multiplikativa modellen Säsongsvariation överskuggar ofta andra relevanta komponenter. Genom säsongrensningen kan man alltså enklare se trender och andra komponenter. ’Detrending’: Borttagandet av trenden yt - TRt yt / TRt

26
Skattning av komponenter, steg-för-steg
Säsongrensning: Serien rensas från säsongkomponenten genom beräkning av centrerade och viktade glidande medelvärden (centered moving averages, CMA): där L=Antal säsonger i serien (L=2 för halvårsdata, 4 för kvartalsdata och 12 för månadsdata)
: där L=Antal säsonger i serien (L=2 för halvårsdata, 4 för kvartalsdata och 12 för månadsdata)")
27
Exempel (sales data från tidigare)
tid månad antal CMA * * * * * * 13 1 3 14 2 2 15 3 6

28
Trend och cyklisk komponent skattas grovt av CMAt.
En första skattning av säsongkomponenterna erhålls genom att beräkna yt/CMAt i en multiplikativ modell yt – CMAt i en additiv modell och sen beräkna medelvärden för alla värden som avser samma säsong. (t.ex. alla januari-värden av yt/CMAt, etc.) Totalt L medelvärden.
 Totalt L medelvärden.")
29
Medelvärdena måste dessutom justeras så att de
vid multiplikativ modell får medelvärde 1, (dvs summan av alla justerade säsongmedelvärden ska bli L) vid additiv modell får medelvärde 0, (dvs summan av alla justerade säsongmedelvärden ska bli 0.) De justerade värdena kallas för säsongskomponenter sn1,...,snL
 vid additiv modell får medelvärde 0, (dvs summan av alla justerade säsongmedelvärden ska bli 0.) De justerade värdena kallas för säsongskomponenter sn1,...,snL.")
30
Exempel, forts

31
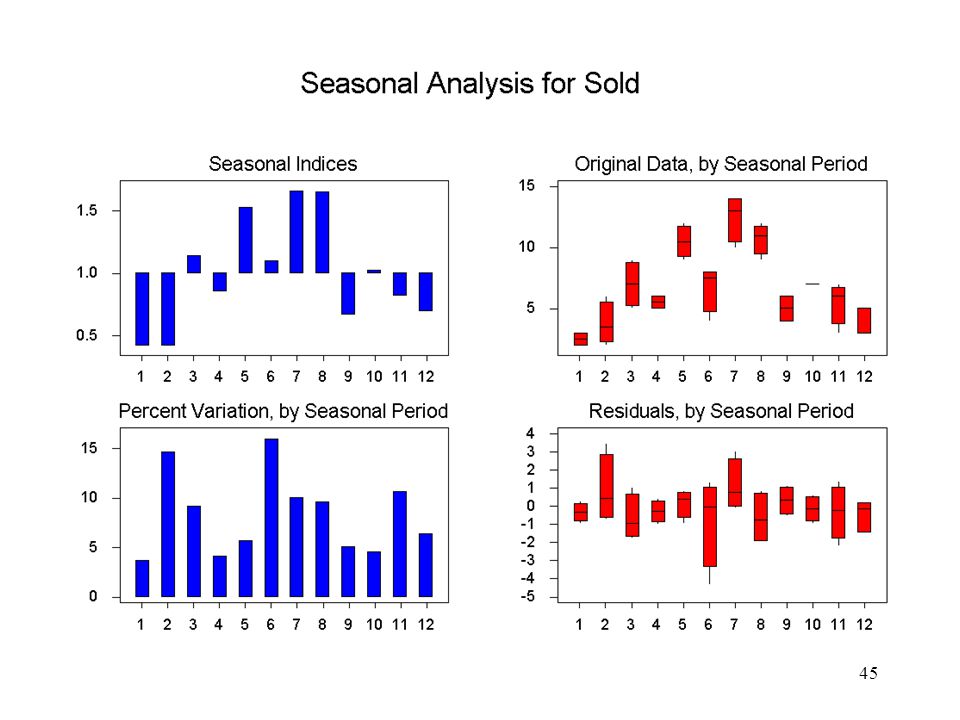
Medelvärden av grova säsongskomponenter:
Juli: ( )/3 Aug: ( )/3 Sep: ( )/3 Okt: ( )/3 Nov: ( )/3 Dec: ( )/3 Jan: ( )/3 Feb: ( )/3 Mar: ( )/3 Apr: ( )/3 Maj: ( )/2 Obs! Bara två värden här! Juni: ( )/2 …och här!
/3 Aug: ( )/3 Sep: ( )/3 Okt: ( )/3 Nov: ( )/3 Dec: ( )/3 Jan: ( )/3 Feb: ( )/3 Mar: ( )/3 Apr: ( )/3 Maj: ( )/2 Obs! Bara två värden här! Juni: ( )/2 …och här!")
32
Summan av de beräknade medelvärdena:
) Summan skall bli L=12 För att få den till 12 multipliceras samtliga medelvärden med 12/
 Summan skall bli L=12. För att få den till 12 multipliceras samtliga medelvärden med. 12/ ")
33
Slutligt skattade säsongkomponenter:
Jan: sn1 = · 0.403 Feb: sn2 = · 0.440 Mar: sn3 = · 1.126 Apr: sn4 = · 0.843 Maj: sn5 = · 1.483 Juni: sn6 = · 1.097 Juli: sn7 = · 1.809 Aug: sn8 = · 1.617 Sep: sn9 = · 0.702 Okt: sn10 = · 1.056 Nov: sn11 = · 0.782 Dec: sn12 = · 0.641

34
Tidsserien säsongrensas genom
vid multiplikativ modell vid additiv modell där är något av värdena beroende på vilken av säsongerna som t motsvarar.

35
Exempel, forts

36
De säsongrensade värdena används för att skatta trendkomponenten
De säsongrensade värdena används för att skatta trendkomponenten. Skatta en linjär (eller kvadratisk) trend TRt med hjälp av regressionsanalys
 trend TRt med hjälp av regressionsanalys.")
37
3. Cyklisk och oregelbunden komponent:
Om cyklisk komponent ej finns med: Residualerna från regressionsanalysen utgör skattning av termen IRt i den klassiska modellen. Om cyklisk komponent finns med: Skatta cyklisk och oregelbunden komponent som en komponent (CLIRt)
")
38
Den cykliska komponenten skattas nu genom ett centrerat oviktat glidande medelvärde:
och den oregelbundna komponenten skattas slutligen som

39
Vilka glidande medelvärden ska användas?
2m+1 väljs i regel till något av värdena 3, 5, 7, 9, 11, 13 Hur m skall väljas bestäms genom att titta på den slutliga skattningen av IRt m väljs så att autokorrelationen och variansen för dessa värden blir så låg som möjligt. 2m+1 kallas antal punkter i det glidande medelvärdet

40
Minitab kan användas för komponentuppdelning med
StatTime seriesDecomposition Multiplikativ modell är dock något annorlunda: yt = TRt·SNt+IRt Val av modelltyp Möjlighet att välja komponenter, men dock begränsat

41
Säsongrensade data

42
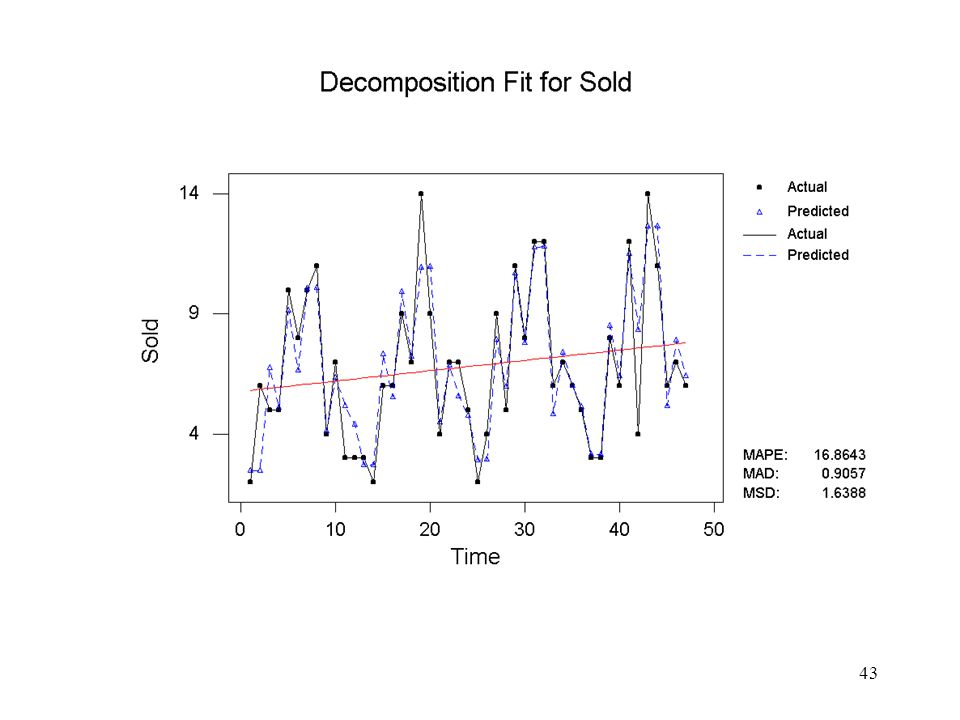
Time Series Decomposition
Data Sold Length ,0000 NMissing 0 Trend Line Equation Yt = 5, ,30E-02*t Seasonal Indices Period Index ,425997 ,425278 ,14238 ,856404 ,52471 ,10138 ,65646 ,65053 ,670985 ,02048 ,825072 ,700325 Dessa blir något annorlunda jämfört med handräkningen tidigare p g a att modellen är annorlunda Accuracy of Model MAPE: ,8643 MAD: ,9057 MSD: ,6388

46
Skattade trend- och säsongkomponenter har lagrats i kolumnerna TREN1 resp. SEAS1
Beräkning av kan göras genom att dividera originaldata med produkten av dessa två CLIR1=Sold/(TREN1· SEAS1) Den cykliska komponenten skall nu skattas genom beräkning av glidande medelvärden på CLIR1
 Den cykliska komponenten skall nu skattas genom beräkning av glidande medelvärden på CLIR1.")
47
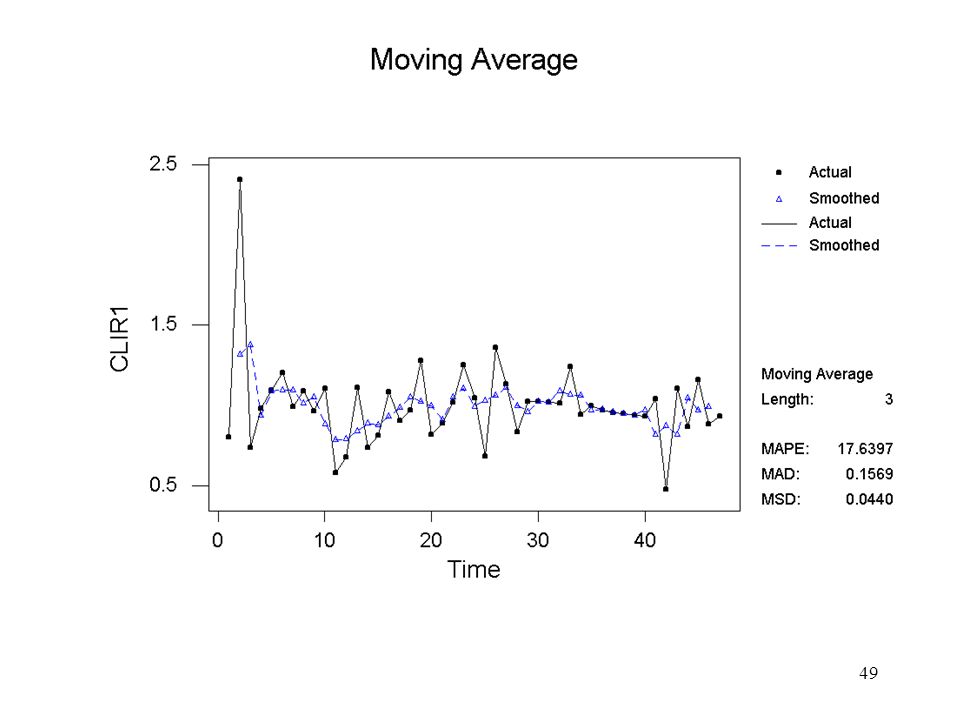
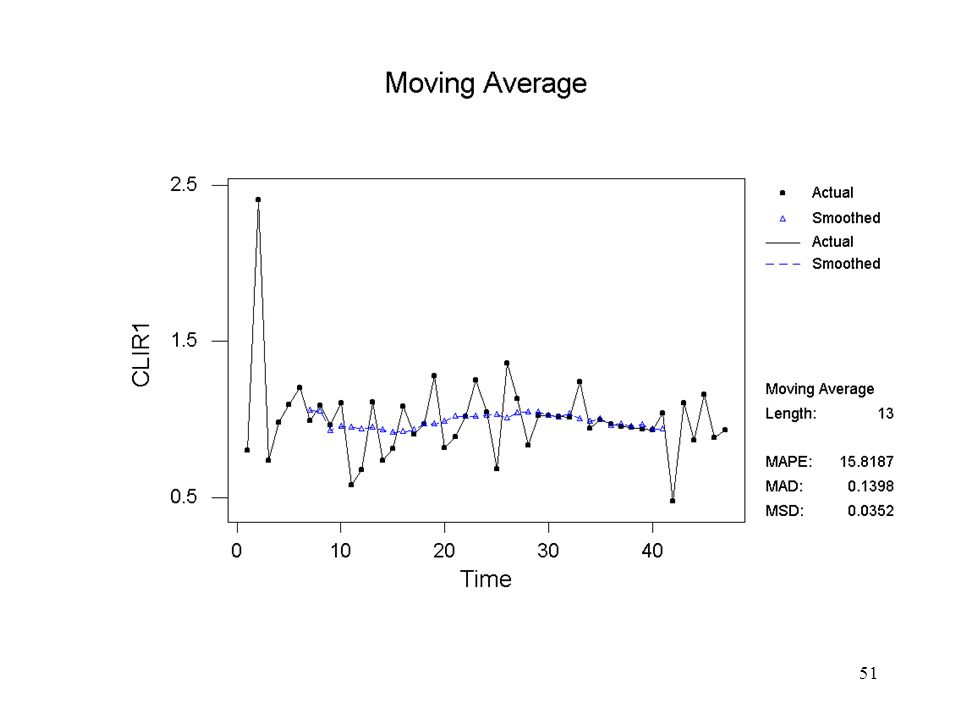
StatTime SeriesMoving Average…
Antal punkter i det glidande medelvärdet

48
Sparar de glidande medelvärdena, dvs den skattade cykliska komponenten i en ny kolumn, som får namnet AVER1

50
Den oregelbundna komponenten (IR) skattas slutligen genom att dividera CLIR1 med AVER1
De resulterade värdena studeras sedan med avseende på spridning, s och seriell korrelation, Corr ( irt , irt-1) 2m+1 s Corr(irt,irt-1) 3 0.219 -0.686 5 0.197 -0.292 7 0.173 -0.343 9 0.171 -0.345 11 0.181 -0.276 13 0.165 -0.200
 2m+1. s. Corr(irt,irt-1)")
52
Seriella korrelationer kan enkelt beräknas med
StatTime seriesLag och sedan StatBasic statisticsCorrelation eller manuellt i Session window: MTB > lag ’RESI4’ c50 MTB > corr ’RESI4’ c50

53
Analys med additiv modell:

54
Time Series Decomposition
Data Sold Length ,0000 NMissing 0 Trend Line Equation Yt = 5, ,30E-02*t Seasonal Indices Period Index ,09028 ,13194 ,909722 ,09028 ,70139 ,618056 ,70139 ,70139 ,96528 ,118056 ,29861 ,17361 Accuracy of Model MAPE: ,4122 MAD: ,9025 MSD: ,6902

55
Vad står måtten MAPE, MAD och MSD för?
Alla tre är mått på hur bra anpassningen är och kan användas för att jämföra olika modeller. Den modell som har lägst MAPE, MAD och MSD har bäst anpassning. Oftast visar alla 3 måtten åt samma håll. Men i vissa fall kan man vara tvungen att välja en av dem. Vid val mellan t ex additiv modell och multiplikativ modell kan det hända att något av måtten är högre för den ena modellen medan ett annat mått är lägre. Det gäller alltså att tolka måtten med visst förnuft.

56
MSD kan också jämföras med MSE i den multipla regressionen:
Formlerna är väldigt lika. Notera dock att vi dividerar med n och inte med n-k-1. Orsaken är att vi här inte har någon regressionsmodell med parametrar som måste skattas väntevärdesriktigt. Storleksmässigt kan dock MSD jämföras med MSE från tidsserieregressionen och är skillnaden markant kan vi också se vilken av modellerna som ger bäst anpassning. Mean Square Deviation Mean Square Error

57
Mean Absolute Deviation
Skillnaden mellan MAD och MSD är att MAD använder absolutavvikelser istället för kvadratiska avvikelser. MAD är mindre känslig för avvikande värden och blir mer användbar när vi har något enstaka värde som uppträder konstigt. Ytterligare en fördel med MAD är att dess värde är i samma skala som yt - observationerna själva, vilket gör det lättare att tolka.

58
Mean Absolute Percentage Error
Måttet använder också absoluta avvikelser, men mäter dem relativt nivån hos y. Vi får alltså relativa (procentuella) avvikelser. Måttet är praktiskt för multiplikativa modeller där den oregelbundna komponenten (IRt ) är ganska betydande, eftersom avvikelserna då blir stora när vi har stora värden på y.
 avvikelser. Måttet är praktiskt för multiplikativa modeller där den oregelbundna komponenten (IRt ) är ganska betydande, eftersom avvikelserna då blir stora när vi har stora värden på y.")
59
Multiplikativ Additiv

60
multiplikativ

61
multiplikativ additiv Trend Line Equation Trend Line Equation
Yt = E-02*t Seasonal Indices Period Index Trend Line Equation Yt = E-02*t Seasonal Indices Period Index multiplikativ additiv

Liknande presentationer











>")
>")






