Ladda ner presentationen
1
Sambandsmodeller, 10 p = 15 hp
Välkomna till kursen Sambandsmodeller, 10 p = 15 hp Kursansvarig är Olle Eriksson Första läsperioden har Lotta Hallberg Regressionsanalys Den andra läsperioden har Olle Eriksson Variansanalys

2
Examination En skriftlig tentamen 7.5hp
16 inlämningsuppgifter (tillfällen) 7.5hp Kurslitteratur Applied Linear Statistical Models av Kutner,Nachtsheim, Neter, Li ISBN: McGraw-Hill
 7.5hp. Kurslitteratur. Applied Linear Statistical Models av. Kutner,Nachtsheim, Neter, Li. ISBN: McGraw-Hill.")
4
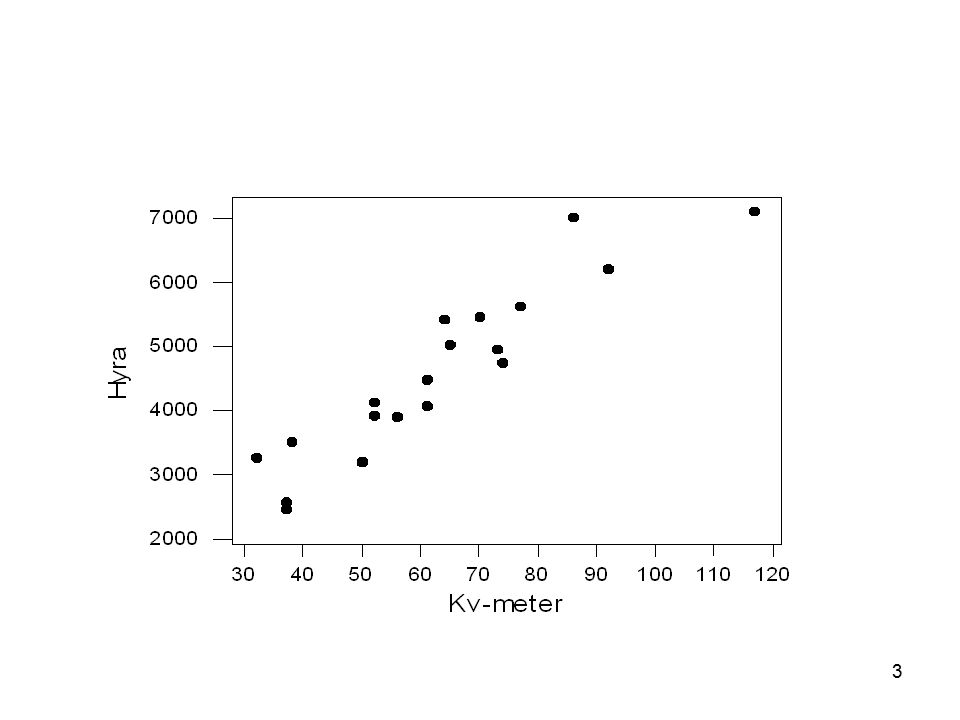
Enkel linjär regression: hyran kan förklaras av lägenhetsstorlek

5
Kvadratisk regression

6
Varför behövs regressionsanalys?
Värdet på responsvariabeln (t.ex. hyra) varierar med värdet på den förklarande variabeln (t.ex storlek på lägenheten): Vi kan använda informationen om lägenhetsstorleken för att göra en bättre skattning/prediktion av den förväntade hyran eller av hyran för en speciell lägenhet
 varierar med värdet på den förklarande variabeln (t.ex storlek på lägenheten): Vi kan använda informationen om lägenhetsstorleken för att göra en bättre skattning/prediktion. av den förväntade hyran eller. av hyran för en speciell lägenhet.")
7
Hur mycket betalar man (i genomsnitt) i hyra om man har en lägenhet på 50 kvadratmeter?
ca SEK

8
Varför behövs regressionsanalys?
Värdet på responsvariabeln (t.ex. hyra) varierar med värdet på den förklarande variabeln (t.ex. storlek på lägenheten): Vi kan använda informationen om lägenhetsstorleken för att göra en bättre skattning/prediktion av den förväntade hyran eller av hyran för en speciell lägenhet Vi kan beskriva datamaterialet och beskriva och dra slutsatser om samband mellan variabler. Därmed kan vi (i vissa fall) öka förståelsen av hur världen omkring oss ser ut.
 varierar med värdet på den förklarande variabeln (t.ex. storlek på lägenheten): Vi kan använda informationen om lägenhetsstorleken för att göra en bättre skattning/prediktion. av den förväntade hyran eller. av hyran för en speciell lägenhet. Vi kan beskriva datamaterialet och beskriva och dra slutsatser om samband mellan variabler. Därmed kan vi (i vissa fall) öka förståelsen av hur världen omkring oss ser ut.")
9
För varje ytterligare kvadratmeter i lägenhetsyta får man betala ca 60 kronor i månaden mer.
10 kvadratmeter mer = 605 SEK

10
Y kallas responsvariabel
x är förklarande variabel Vi vill undersöka om x förklarar y, inte tvärtom

11
Enkel linjär regression:
Till datamaterialet kan vi anpassa en rät linje: som är en skattning av det verkliga sambandet (det som vi skulle kunna observera om vi visste hyran och ytan på alla lägenheter som finns): E (Y ) = μy|x = 0 + 1· x eller Y = μy|x + e = 0 + 1· x + e
: E (Y ) = μy|x = 0 + 1· x. eller Y = μy|x + e = 0 + 1· x + e.")
12
E (Y ) = μy|x = 0 + 1· x eller Y = μy|x + e = 0 + 1· x + e μy|x... det förväntade värdet på y om värdet på den förklarande variabeln är givet. 0... interceptet (intercept). Det förväntade värdet på Y om x=0. 1... lutningen (slope). Anger förändringen i Y om x ökar med en enhet. e ... felterm (error term). Den del av variationen i datamaterialet som inte går att beskriva med regressionslinjen.
. Det förväntade värdet på Y om x=0. 1... lutningen (slope). Anger förändringen i Y om x ökar med en enhet. e ... felterm (error term). Den del av variationen i datamaterialet som inte går att beskriva med regressionslinjen.")
13
Hur anpassar man en rät linje till ett datamaterial
Hur anpassar man en rät linje till ett datamaterial? Man väljer linjen som har det minsta avståndet till alla observationer.

14
Detta görs genom ‘Minsta-kvadrat-metoden’: Summan av alla kvadrerade avstånd ska bli så liten som möjligt.

15
Skattning av parametrarna med Minsta kvadratmetoden
Y- 0 - 1· x = e Välj så att minimeras. Härledning på tavlan

16
Minsta-kvadrat-skattningen för enkel linjär regression

17
Det går enklare att beräkna b0 och b1 om vi skriver om formlerna för SSxx och SSxy:

18
Σ 1294 93469 6271637 88196 Kv-meter Hyra xi*yi xi*xi
*4490= Σ 3721 2500 1024 5476 4900 2704 4096 4225 1444 1369 13689 7396 5329 5929 3136 8464

19
Då får vi:

20
Alltså: Skattningen av regressionslinjen är
För varje ytterligare kvadratmeter i lägenhetsyta kommer man i genomsnitt betala kronor mer i hyra. För en lägenhet med 0 kvadratmeter kommer man att betala kronor i hyra (??!?)
")
21
Statistisk slutledning (Inference) i regressionsmodellen
Signifikanstest för parametrarna b0 och b1. t.ex. ökar hyran verkligen med storleken på lägenheten, eller skulle man kunna sätta b1=0? Konfidensintervall för parametrarna b0 och b1. Konfidensintervall för väntevärdet av y (givet x). Prediktionsintervall för en individuell prognos av y (givet x). För att kunna göra signifikanstest och för att kunna beräkna konfidensintervall måste vi göra vissa antaganden.
. Prediktionsintervall för en individuell prognos av y (givet x). För att kunna göra signifikanstest och för att kunna beräkna konfidensintervall måste vi göra vissa antaganden.")
22
Antagande i regressionsmodellen
Y = 0 + 1· x + e Feltermen e har väntevärde 0 och varians s2. (Variansen är konstant över hela datamaterialet) Feltermen e är normalfördelad. Feltermen e är statistisk oberoende. Varje värde för e är oberoende av alla andra värden av e. Hur man undersöker om feltermen verkligen uppfyller de här kraven kommer vi att se senare (residualanalys). Feltermens varians s2 måste skattas.
 Feltermen e är normalfördelad. Feltermen e är statistisk oberoende. Varje värde för e är oberoende av alla andra värden av e. Hur man undersöker om feltermen verkligen uppfyller de här kraven kommer vi att se senare (residualanalys). Feltermens varians s2 måste skattas.")
23
Hur bestämmer man , skattningen för , variansen av feltermen?
I ett vanligt stickprov bestäms s som stickprovsvariansen: I regressionssammanhang gör vi på ett liknande sätt, men vi måste ta hänsyn till den del av variationen i datamaterialet som kan förklaras av x. ‘Residual’ = e

24
Residualerna Kv-meter Hyra b0+b1*xi yi-(b0+b1xi)
*61= Residualerna

25
Skattning av se betecknas ofta bara med s.

26
Signifikanstest för parametrarna b0 och b1
Nollhypotesen: H0: b1=0 Mothypotesen: H1: b1≠0 t-test: Skattning Nollhypotes Standardavvikelse för skattningen av b1 (standard error) t-fördelad med n-2 frihetsgrader
 t-fördelad med n-2 frihetsgrader.")
27
Hur beräknar man , skattningen för ?
i vårt fall:

28
Signifikanstest för b1 :
Jämför med t-fördelningen med 19 frihetsgrader. → högt signifikant RITA PÅ TAVLAN Slutsats: Lutningen i regressionsmodellen är signifikant skild från noll. Ytan på en lägenhet har betydelse för hur hög hyran är. Ju större lägenhet desto högre hyra (positivt samband). Signifikanstest för interceptet se sidan 48 i boken.
. Signifikanstest för interceptet se sidan 48 i boken.")
29
Konfidensintervall för lutningen b1:
Med hjälp av skattningarna vi har tagit fram, kan vi även beräkna ett konfidensintervall för b1. Med 95% säkerhet ligger b1 i intervallet –

30
Ett datorprogram, som MINITAB eller SAS kan beräkna en regressionsanalys åt oss.
Där får vi ut t.ex.: Regressionlinjen Parameterskattningar b0 och b1 Signifikanstest för b0 och b1 Skattningen s (spridningen i residualerna)
")
31
Regression Analysis: Hyra versus Kv-meter
The regression equation is Hyra = Kv-meter Predictor Coef SE Coef T P Constant Kv-meter S = R-Sq = 85.5% R-Sq(adj) = 84.8% Analysis of Variance Source DF SS MS F P Regression Residual Error Total Regressionslinjen t-tester och deras p-värden Parameterskattningar och deras standardavvikelser Residualspridningen Konfidensintervall för parametrarna b0 och b1 måste man dock beräkna själv.
 = 84.8% Analysis of Variance. Source DF SS MS F P. Regression Residual Error Total Regressionslinjen. t-tester och deras p-värden. Parameterskattningar och deras standardavvikelser. Residualspridningen. Konfidensintervall för parametrarna b0 och b1 måste man dock beräkna själv.")
32
Punktskattningar och punktprognoser
För ett givet värde på x (säg xh) kan man skatta det genomsnittliga värdet på Y dvs E[Y] (Vad är hyran för en lägenhet på 60 kvadratmeter i genomsnitt?) prediktera värdet på Y för en ny observation (Hur mycket kommer just den här lägenheten på 60 kvadratmeter att kosta i hyra?) Både punktskattningen och punktprognosen beräknas som
 kan man. skatta det genomsnittliga värdet på Y dvs E[Y] (Vad är hyran för en lägenhet på 60 kvadratmeter i genomsnitt ) prediktera värdet på Y för en ny observation. (Hur mycket kommer just den här lägenheten på 60 kvadratmeter att kosta i hyra ) Både punktskattningen och punktprognosen beräknas som.")
33
Punktskattningar och punktprognoser är naturligtvis osäkra
Punktskattningar och punktprognoser är naturligtvis osäkra. Därför ska man helst ange dem tillsammans med ett intervall: Punktskattningen med ett konfidensintervall och punktprognosen med ett prediktionsintervall där

34
För ett xh som ligger nära får vi ett litet värde på och därför även ett smalare konfidens- eller predikitonsintervall.

35
Vad är hyran för en lägenhet på 60 kvadratmeter i genomsnitt?

36
Vad är hyran för en lägenhet på 60 kvadratmeter i genomsnitt?
Med 95% säkerhet kommer hyran att ligga mellan 4112 och kronor i månaden.

37
Hur mycket kommer jag att betala om jag hyr just den här lägenheten på 60 kvadratmeter?
Med 95% säkerhet kommer hyran för just den här typen av lägenhet ligga mellan och kronor i månaden.

38
Även punktskattningar och punktprognoser kan beräknas med hjälp av MINITAB
The regression equation is Hyra = Kv-meter Predictor Coef SE Coef T P Constant Kv-meter S = R-Sq = 85.5% R-Sq(adj) = 84.8% .... Predicted Values for New Observations New Obs Fit SE Fit % CI % PI ( , ) ( , ) Values of Predictors for New Observations New Obs Kv-meter
 = 84.8% .... Predicted Values for New Observations. New Obs Fit SE Fit 95.0% CI 95.0% PI ( 4112, 4594) ( 3227, 5479) Values of Predictors for New Observations. New Obs Kv-meter")
















>")

>")

