Ladda ner presentationen
Presentation laddar. Vänta.

1
Simulering av MIPS32 4K med TLB och CACHE Andrei Krougliak Simon Olsson Luleå tekniska universitet 2005

2
Syncsim och MIPS Syncsim – ett simuleringsverktig för synkrona kretsar MIPS modell för Syncsim Pipelined MIPS modell för Syncsim Pipelined MIPS modell för Syncsim med TLB, cache, och RAM

3
TLB TLB = Translation Lookaside Buffer Varför behöver man TLB? Hur fungerar TLB? Hur implementerar man TLB?

4
TLB: Varför behöver man den? TLB ger ett virtuellt adressutrymme för varje process i ett system där flera process exekveras samtidigt (multitask system) Det blir enklare att skriva program (programmerare behöver inte ta hänsyn till andra processer som körs) TLB ger minnesskydd (en användarprocess får inte tillgång till minnesadress som används av en annan process eller av operativsystemet)
 Det blir enklare att skriva program (programmerare behöver inte ta hänsyn till andra processer som körs) TLB ger minnesskydd (en användarprocess får inte tillgång till minnesadress som används av en annan process eller av operativsystemet).")
5
TLB: Några definitioner En sida är ett sammanhängande block av minne, men två sidor i följd (t.ex. sidorna 3 och 4) kan ligga skilda åt i det fysiska minnet. Virtuell adress (VA) används i källkoden och i processorn VA = VPN + page offset Fysisk adress (PA) används i det fysiska minnet (t.ex. DRAM) PA = PFN + page offset TLB översätter VPN till PFN medan page offset lämnas oförändrat (den adresserar en enskild byte inom sidan).
 kan ligga skilda åt i det fysiska minnet. Virtuell adress (VA) används i källkoden och i processorn VA = VPN + page offset Fysisk adress (PA) används i det fysiska minnet (t.ex. DRAM) PA = PFN + page offset TLB översätter VPN till PFN medan page offset lämnas oförändrat (den adresserar en enskild byte inom sidan)..")
6
TLB: Hur fungerar den? Resultat av översättning beror på vilken process som körs, t.ex. när process P1 körs: VA=0x1234 5008 TLB PA=0x0011 1008 när process P2 körs: VA=0x1234 5008 TLB PA=0x0044 0008 här används 12-bitars page offset som motsvarar en sidstorlek på 4KB.

7
TLB: Hur fungerar den? Alla översättningar av VPN till PFN för en enskild process lagras i en sidtabell i kernelminnet. TLB innehåller bara de senast använda rader från processens sidtabell. Operativsystemet skapar en ny sidtabell när en process startas. Det är operativsystemets ansvar att: Allokera nya sidor i minnet; Flytta sidor till hårddisken när det fysiska minnet är fullt (page swapping); Ta bort sidor från minnet efter att processen som använde dem har avslutats; Uppdatera TLB.
; Ta bort sidor från minnet efter att processen som använde dem har avslutats; Uppdatera TLB..")
8
TLB: Hur fungerar den? Eftersom storleken av en TLB är begränsad innehåller den bara de senaste använda rader från en process sidtabell. Men detta påverkar inte prestandan dramatisk eftersom samma sidor adresseras av programmet flera gånger (temporal locality och spatial locality).
..")
9
TLB: TLB instruktioner Eftersom TLB ska fyllas på från processens sidtabell av operativsystemet behöver vi särskilda instruktioner i ISA. Man brukar inte tillåta användarprocesser att köra instruktionerna. MIPS Priviliged Architecture definierar bl.a. TLBR, TLBP, TLBWI, TLBWR.

10
TLB: TLB och context switch För att operativsystemet ska kunna byta den aktiva processen (utföra en context switch) behöver man: antingen tömma TLB vid varje processbyte, eller spara ett process ID med varje översättning som lagras i TLB.
 behöver man: antingen tömma TLB vid varje processbyte, eller spara ett process ID med varje översättning som lagras i TLB.")
11
TLB: TLB och page swapping För att operativsystemet ska kunna flytta sidor till hårddisken (swap pages) behöver man på något sätt markera det i sidtabellen och i TLB. Det kan göras med hjälp av en Valid bit i TLB och i sidtabellen.

12
TLB: TLB och read-only sidor Man kan använda TLB för att skydda vissa sidor från skrivning av processen som äger dem... (förutom allmän virtuellt minnes skydd som garanterar att andra processer inte får åtkomst till processens minne)...genom att ha en särskild ”write enable” bit för varje sida i sidtabell och i TLB.
...genom att ha en särskild write enable bit för varje sida i sidtabell och i TLB..")
13
TLB: Optimeringar TLB kan implementeras så att den stödjer variabel sidstorlek. Man kan ha separata TLB för dataminne och för instruktionsminne så att de kan användas parallellt.

14
MIPS 4K processorkärna Processorkärnan består av: Execution Core; System Co-Processor; Memory Management Unit med TLB; (L1) Data cache; (L1) Instruction cache; Bus Interface Unit.
 Data cache; (L1) Instruction cache; Bus Interface Unit.")
15
MIPS 4K: Adressering 32-bitars virtuell adress som översättas av MMU till en 32- bitars fysisk adress (en del av kernelminnet är omappat). Parallell översättning av instruktionsadress och dataadress. D-TLB med 3 rader, I-TLB med 3 rader, JointTLB med 16 dubbla rader som stödjer variabel sidstorlek på 4/16/256 KB eller 1/4/16 MB. En rad i D-TLB eller I-TLB innehåller: 1 Global bit (G) 8 bitar Address Space Identifier (ASID) 20 bitar VPN[31:12] 20 bitar PFN[31:12] 3 Cacheability bitar (C[2:0]) 1 Write-enable bit (D) 1 Valid bit (V)
 8 bitar Address Space Identifier (ASID) 20 bitar VPN[31:12] 20 bitar PFN[31:12] 3 Cacheability bitar (C[2:0]) 1 Write-enable bit (D) 1 Valid bit (V).")
16
MIPS 4K Adress Utrymme Kernel, sida 0 Kernel, sida 1 Kernel, sida 2 Fysiskt minne Kernel sida 0 Kernel sida 1 Kernel sida 2 Process 1, sida 0 Process 1, sida 1 Process 2, sida 0 0x8000 0000 0xFFFF FFFF 0x0000 0000 0x7FFF FFFF 0x0000 0000 0x7FFF FFFF Process 1, sida 2 Process 2, sida 1 Process 2, sida 2 Process 1, sida 0 Process 2, sida 2 Process 1, sida 1 Process 2, sida 0 Process 2, sida 1 Virtuellt minne Process 2, sida 3 Kernel, sida 3 Kernel sida 3 Process 2, sida 3 Process 1, sida 3 Process 1, sida 2 0x0000 0000 0xFFFF FFFF

17
Instruction Fetch Om vi har en I-TLB träff samt en I-Cache träff ska en ny instruktion hämtas varje klockcykel PC EntryHi G = Hit ASIDVPNPFNCDV VPN [31:12] ASID [7:0] Page offset [11:0] PFN [31:12] IPA MMU Clk to CPU Exception to CPU Clk C, D, V IVA [31:0] I-TLB
![Instruction Fetch Om vi har en I-TLB träff samt en I-Cache träff ska en ny instruktion hämtas varje klockcykel PC EntryHi G = Hit ASIDVPNPFNCDV VPN [31:12] ASID [7:0] Page offset [11:0] PFN [31:12] IPA MMU Clk to CPU Exception to CPU Clk C, D, V IVA [31:0] I-TLB](http://images.slideplayer.se/7/1957772/slides/slide_17.jpg "Instruction Fetch Om vi har en I-TLB träff samt en I-Cache träff ska en ny instruktion hämtas varje klockcykel PC EntryHi G = Hit ASIDVPNPFNCDV VPN [31:12] ASID [7:0] Page offset [11:0] PFN [31:12] IPA MMU Clk to CPU Exception to CPU Clk C, D, V IVA [31:0] I-TLB")
18
Instruction Fetch Om vi har en I-TLB träff samt en I-Cache träff ska en ny instruktion hämtas varje klockcykel PC EntryHi G = Hit ASIDVPNPFNCDV 01 01 01 VPN [31:12] ASID [7:0] Page offset [11:0] PFN [31:12] IPA MMU Clk to CPU Exception to CPU Clk C, D, V IVA [31:0] ASID [7:0] I-TLB
![Instruction Fetch Om vi har en I-TLB träff samt en I-Cache träff ska en ny instruktion hämtas varje klockcykel PC EntryHi G = Hit ASIDVPNPFNCDV VPN [31:12] ASID [7:0] Page offset [11:0] PFN [31:12] IPA MMU Clk to CPU Exception to CPU Clk C, D, V IVA [31:0] ASID [7:0] I-TLB](http://images.slideplayer.se/7/1957772/slides/slide_18.jpg "Instruction Fetch Om vi har en I-TLB träff samt en I-Cache träff ska en ny instruktion hämtas varje klockcykel PC EntryHi G = Hit ASIDVPNPFNCDV VPN [31:12] ASID [7:0] Page offset [11:0] PFN [31:12] IPA MMU Clk to CPU Exception to CPU Clk C, D, V IVA [31:0] ASID [7:0] I-TLB")
19
Instruction Fetch Om vi har en I-TLB träff samt en I-Cache träff ska en ny instruktion hämtas varje klockcykel PC EntryHi G = Hit ASIDVPNPFNCDV 01 01 01 VPN [31:12] ASID [7:0] Page offset [11:0] PFN [31:12] IPA MMU Clk to CPU Exception to CPU Clk C, D, V IVA [31:0] ASID [7:0] I-TLB
![Instruction Fetch Om vi har en I-TLB träff samt en I-Cache träff ska en ny instruktion hämtas varje klockcykel PC EntryHi G = Hit ASIDVPNPFNCDV VPN [31:12] ASID [7:0] Page offset [11:0] PFN [31:12] IPA MMU Clk to CPU Exception to CPU Clk C, D, V IVA [31:0] ASID [7:0] I-TLB](http://images.slideplayer.se/7/1957772/slides/slide_19.jpg "Instruction Fetch Om vi har en I-TLB träff samt en I-Cache träff ska en ny instruktion hämtas varje klockcykel PC EntryHi G = Hit ASIDVPNPFNCDV VPN [31:12] ASID [7:0] Page offset [11:0] PFN [31:12] IPA MMU Clk to CPU Exception to CPU Clk C, D, V IVA [31:0] ASID [7:0] I-TLB")
20
Instruction Fetch + Data Load/Store Om vi har I-TLB och D-TLB träff samt I-Cache och D-Cache träff ska en ny instruktion hämtas varje klockcykel samt att en dataminnes operation kan utföras varje klockcykel IVA DVA DTLBITLB ASID MMU I-PFN Hit = D-PFN Hit =

21
D-TLB Miss + JointTLB Hit DVA EntryHi DVA [31:0] DTLB Hit = JTLB Hit … DTLB entry Write enable GASIDVPN2CMASKPFN 1 C, D,V 1 PFN 0 C, D,V 0... = ASID [7:0] D-PFN D-TLB J-TLB GASIDVPNPFNCDV 01 01 01
![D-TLB Miss + JointTLB Hit DVA EntryHi DVA [31:0] DTLB Hit = JTLB Hit … DTLB entry Write enable GASIDVPN2CMASKPFN 1 C, D,V 1 PFN 0 C, D,V 0...](http://images.slideplayer.se/7/1957772/slides/slide_21.jpg "= ASID [7:0] D-PFN D-TLB J-TLB GASIDVPNPFNCDV")
22
D-TLB Miss + JointTLB Hit DVA EntryHi DVA [31:0] DTLB Hit = JTLB Hit … DTLB entry Write enable GASIDVPN2CMASKPFN 1 C, D,V 1 PFN 0 C, D,V 0... GASIDVPNPFNCDV 01 01 01 = ASID [7:0] D-PFN D-TLB J-TLB
![D-TLB Miss + JointTLB Hit DVA EntryHi DVA [31:0] DTLB Hit = JTLB Hit … DTLB entry Write enable GASIDVPN2CMASKPFN 1 C, D,V 1 PFN 0 C, D,V 0...](http://images.slideplayer.se/7/1957772/slides/slide_22.jpg "GASIDVPNPFNCDV = ASID [7:0] D-PFN D-TLB J-TLB.")
23
D-TLB Miss + JointTLB Hit DVA EntryHi DVA [31:0] DTLB Hit = JTLB Hit … DTLB entry Write enable GASIDVPN2CMASKPFN 1 C, D,V 1 PFN 0 C, D,V 0 0...1... GASIDVPNPFNCDV 01 01 01 = 000000 ASID [7:0] D-PFN D-TLB J-TLB
![D-TLB Miss + JointTLB Hit DVA EntryHi DVA [31:0] DTLB Hit = JTLB Hit … DTLB entry Write enable GASIDVPN2CMASKPFN 1 C, D,V 1 PFN 0 C, D,V](http://images.slideplayer.se/7/1957772/slides/slide_23.jpg "GASIDVPNPFNCDV = ASID [7:0] D-PFN D-TLB J-TLB.")
24
D-TLB Miss + JointTLB Hit DVA EntryHi DVA [31:0] DTLB Hit = JTLB Hit … DTLB entry Write enable GASIDVPN2CMASKPFN 1 C, D,V 1 PFN 0 C, D,V 0 0...1... GASIDVPNPFNCDV 01 01 01 = 000000 ASID [7:0] 0 0 00...1 D-PFN D-TLB J-TLB
![D-TLB Miss + JointTLB Hit DVA EntryHi DVA [31:0] DTLB Hit = JTLB Hit … DTLB entry Write enable GASIDVPN2CMASKPFN 1 C, D,V 1 PFN 0 C, D,V](http://images.slideplayer.se/7/1957772/slides/slide_24.jpg "GASIDVPNPFNCDV = ASID [7:0] D-PFN D-TLB J-TLB.")
25
D-TLB Miss + JointTLB Hit DVA EntryHi DVA [31:0] DTLB Hit = JTLB Hit … DTLB entry Write enable GASIDVPN2CMASKPFN 1 C, D,V 1 PFN 0 C, D,V 0 0...1... GASIDVPNPFNCDV 01 01 0... 1 = 000000 ASID [7:0] 0 0 0 00...1 DTLB skrivs i nästa klockcykeln, processorn stannar (stalls) för 1 klockcykel D-PFN D-TLB J-TLB
![D-TLB Miss + JointTLB Hit DVA EntryHi DVA [31:0] DTLB Hit = JTLB Hit … DTLB entry Write enable GASIDVPN2CMASKPFN 1 C, D,V 1 PFN 0 C, D,V](http://images.slideplayer.se/7/1957772/slides/slide_25.jpg "GASIDVPNPFNCDV = ASID [7:0] DTLB skrivs i nästa klockcykeln, processorn stannar (stalls) för 1 klockcykel D-PFN D-TLB J-TLB.")
26
D-TLB Miss + JointTLB Hit EntryHi DTLB Hit = JTLB Hit … DTLB entry Write enable GASIDVPNPFNCDV 01 01 0... 1 = D-PFN ASID [7:0] 0 0 D-TLB J-TLB DVA DVA [31:0] GASIDVPN2CMASKPFN 1 C, D,V 1 PFN 0 C, D,V 0 0...1... 000000

27
D-TLB Miss + JointTLB Hit EntryHi DTLB Hit = JTLB Hit … DTLB entry Write enable GASIDVPN2CMASKPFN 1 C, D,V 1 PFN 0 C, D,V 0... GASIDVPNPFNCDV 01 01 01 = ASID [7:0] 10 D-PFN 16 KB page 14 bitars page offset 10 D-TLB J-TLB DVA DVA [31:0]

28
D-TLB Miss + JointTLB Hit EntryHi DTLB Hit = JTLB Hit … DTLB entry Write enable GASIDVPN2CMASKPFN 1 C, D,V 1 PFN 0 C, D,V 0 0...1... GASIDVPNPFNCDV 01 01 01 = 000001 ASID [7:0] D-PFN 10 D-TLB J-TLB DVA DVA [31:0]

29
D-TLB Miss + JointTLB Hit EntryHi DTLB Hit = JTLB Hit … DTLB entry Write enable GASIDVPN2CMASKPFN 1 C, D,V 1 PFN 0 C, D,V 0 0...1... GASIDVPNPFNCDV 01 01 01 = 000001 ASID [7:0] 01...1 D-PFN 10 1 1 D-TLB J-TLB DVA DVA [31:0]

30
D-TLB Miss + JointTLB Hit EntryHi DTLB Hit = JTLB Hit … DTLB entry Write enable GASIDVPN2CMASKPFN 1 C, D,V 1 PFN 0 C, D,V 0 0...1... GASIDVPNPFNCDV 01 01 0... 1 = ASID [7:0] 0 DTLB skrivs i nästa klockcykeln, processorn stannar (stall) för 1 cykel D-PFN 1...1 10 1 1 000001 1 10 D-TLB J-TLB DVA DVA [31:0]
 för 1 cykel D-PFN D-TLB J-TLB DVA DVA [31:0].")
31
D-TLB Miss + JointTLB Hit EntryHi DTLB Hit = JTLB Hit … DTLB entry Write enable GASIDVPNPFNCDV 01 01 0... 1 = D-PFN ASID [7:0] 10 1 1 D-TLB J-TLB DVA DVA [31:0] GASIDVPN2CMASKPFN 1 C, D,V 1 PFN 0 C, D,V 0 0...1... 000001

32
Cache - Behov för minneshierarkin Skillnaden i prestanda mellan CPU och minne Idag är långa minnesåtkomsttider en flaskhals för datorprestanda

33
Cache - Minneshierarkin Nivå 1 cache SRAM Nivå 2 cache SRAM Minne DRAM HD pagefile (inte en del av filsystemet) Snabbare, mindre, dyrareLångsammare, större, billigare
 Snabbare, mindre, dyrareLångsammare, större, billigare")
34
Cache - Minneshierarkin Nivå 1 cache SRAM Nivå 2 cache SRAM Minne DRAM HD pagefile (inte en del av filsystemet) Snabbare, mindre, dyrareLångsammare, större, billigare Behandlas separat: Icke-cacheable minne Minnesmappad I/O enheter DMA Swapping (OS)
 Snabbare, mindre, dyrareLångsammare, större, billigare Behandlas separat: Icke-cacheable minne Minnesmappad I/O enheter DMA Swapping (OS)")
35
Cache - Minneshierarkin Nivå 1 cache SRAM Nivå 2 cache SRAM Minne DRAM HD pagefile (inte en del av filsystemet) Snabbare, mindre, dyrareLångsammare, större, billigare Swapping (OS) Idag koncentrerar vi oss här
 Snabbare, mindre, dyrareLångsammare, större, billigare Swapping (OS) Idag koncentrerar vi oss här")
36
Cache uppbyggnad En cache rad i en fullt associativ cache består av en cache tag = en adress på ett block (n ord) + data = n ord i följd. Om vi laddar en hel rad efter varje minnesåtkomst som inte kan betjänas av cachen så blir sannolikhet stor att efterföljande minnesåtkomster kommer att betjänas av cachen utan att stanna (stall) processorn (tack vare temporal locality och spatial locality)
 processorn (tack vare temporal locality och spatial locality).")
37
Cache uppbyggnad Det här är en k-wsa cache. Om k=1 har vi en direkt mappad cache. Alla adresser med samma cache index mappas till samma ”set”, men antalet av rader inom en ”set” är begränsad. Vi behöver en smart ersättningsstrategi inom en ”set”, t.ex. en variant av LRU. Vissa cachar tillåter även att ”låsa” en rad.

38
Cache uppbyggnad I vilka fall ska vi börja ladda en cache rad från minnet? Hur mycket data ska vi ha i en cache rad? Vilken ersättningsstrategi använder vi? Hur garanterar vi minneskonsistens (dvs. att innehållet av minnet och cachen matchar)?
 .")
39
Cache: Write-allocate vs no write-allocate I vilka fall ska vi börja ladda en cache rad från minnet? För en write-allocate cache: Efter varje minnesåtkomst, ”load” samt ”store”, som inte kan betjänas av cachen. Bra för ”sw addr1 data” följd av ”lw addr1 reg”. För en no write-allocate cache: Efter varje ”load” operation som inte kan betjänas av cachen, men inte efter en ”store” operation. Bra för en isolerad ”sw addr1 data”. Make common case fast!

40
Cache: Storlek på en cache rad Hur mycket data ska vi ladda till en cache rad? Längre rader längre laddningstid längre processor stallning, men antalet cache miss minskar Kortare rader kortare laddningstid, men antalet cache miss ökar Optimeringar: ”Early restart”: man startar om processorn så fort det efterfrågade ordet kommer och fortsätter laddar cache raden i bakgrunden ”Critical word first”: man börja ladda med ordet som efterfrågades även om det ligger i mitten av ett block (behöver stöd av DRAM eller nivå 2 cache)
.")
41
Cache: Ersättningsstrategi Vilken ersättningsstrategi använder vi? Slumpmässig ersättning; LRU; LRU, men operativsystemet kan låsa kritiska rader så att de aldrig ersättas (behöver en särskild instruktion i ISA).
..")
42
Cache: Cache och minneskonsistens ”Store” operation kan skriva: Både till cachen och till minnet (write-through cache) ”write stall” om vi inte använder någon buffer; ”write stall” om vi har flera ”store” operationer i följd och buffern överflödas. Bara till cachen (write-back cache). Hela cache raden måste då skrivas till minnet om den har valts för ersättning Inget ”write stall”; Oförväntad, stor fördröjning när hela raden skrivas till minnet. Make common case fast!
. Hela cache raden måste då skrivas till minnet om den har valts för ersättning Inget write stall ; Oförväntad, stor fördröjning när hela raden skrivas till minnet. Make common case fast!.")
43
MIPS 4K D-Cache och I-Cache Separata datacache och instruktionscache upp till 16 KB varje. Cache rad på 16 byte (4 ord). No write-allocate, write-through (med 2 16-byte buffrar i Bus Interface Unit), ”critical word first” och ”early restart”. Virtuell cache index + fysisk cache tag som tillåter att uppslagning sker parallellt i cachen och i TLB.
. No write-allocate, write-through (med 2 16-byte buffrar i Bus Interface Unit), critical word first och early restart . Virtuell cache index + fysisk cache tag som tillåter att uppslagning sker parallellt i cachen och i TLB..")
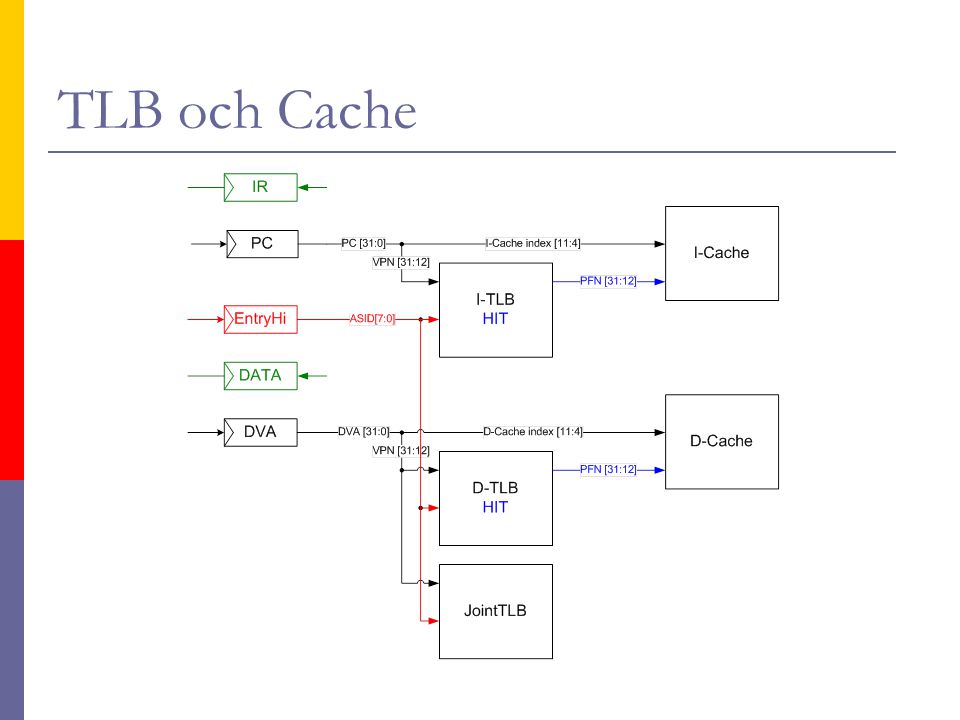
44
TLB och Cache

47
Cache: Data Load + Data Cache Hit

48
Cache: Data Load + Data Cache Miss

50
Simulering av MIPS32 4K med TLB och CACHE Andrei Krougliak Simon Olsson 2005

Liknande presentationer




 – en instruktion i taget opererar på ett värde i taget ● Single Instruction, Multiple Data (SIMD)>")
 –lagringsklass( auto, extern, register, static ) •lagringsklassens.>")


>")
>")


>")

1 IS1200 Datorteknik Föreläsning 10 1. Processorkonstruktion 2. DMA, Direct Memory.>")





.>")
