Ladda ner presentationen
1
SAMBAND

2
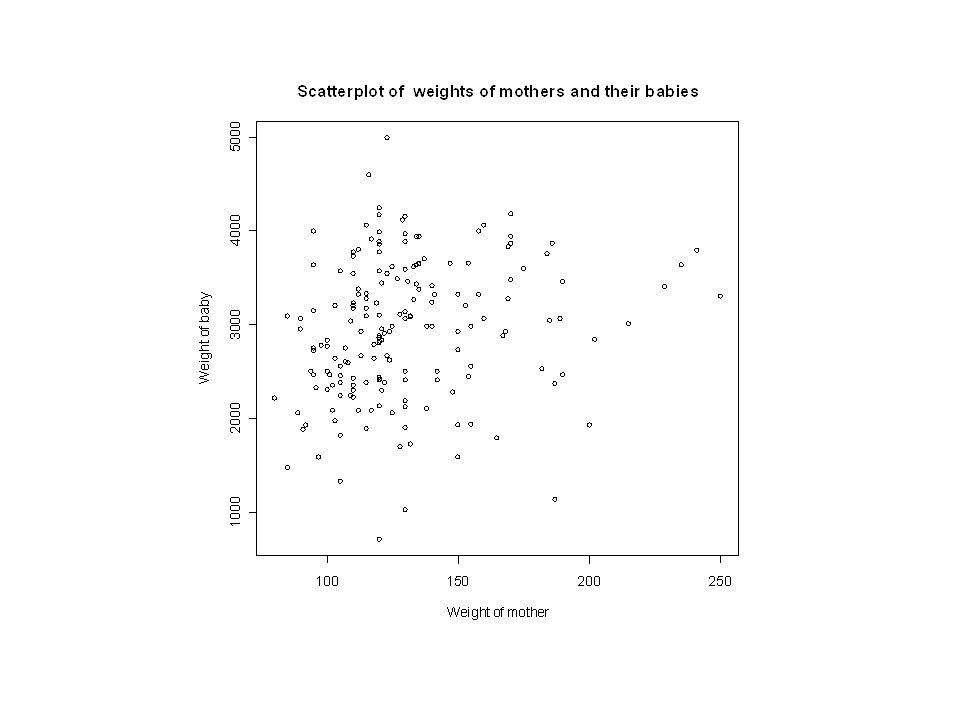
Vi vill undersöka om det finns ett samband mellan tentamensresultat och genomsnittligt antal timmar/dag man studerat. Person ABCDEFGHIJ Timmar/ Dag 4567535788 Resultat 20252235151422303739

3
Samband mellan timmar per vecka och tentamensresultat

4
Spridningsdiagram (Scatterplot) Ett spridningsdiagram är en grafisk beskrivning av samband mellan två variabler där varje punkt representerar en individ/enhet Lodrät axel (y-axeln) - beroende variabel Vågrät axel (x-axeln) - förklarande variabel
 Ett spridningsdiagram är en grafisk beskrivning av samband mellan två variabler där varje punkt representerar en individ/enhet Lodrät axel (y-axeln) - beroende variabel Vågrät axel (x-axeln) - förklarande variabel")
6
Korrelationskoefficienten Korrelationskoefficienten r är ett mått på linjärt samband mellan två kvantitativa variabler. Korrelationskoefficienten kan anta värden mellan –1 och +1. Observera att r är ett mått på linjärt samband. Även om r = 0 kan det finnas ett samband mellan x och y som ej är linjärt. Korrelationen mellan antal timmar per vecka och tentamensresultat i vårt exempel är 0,92.

7
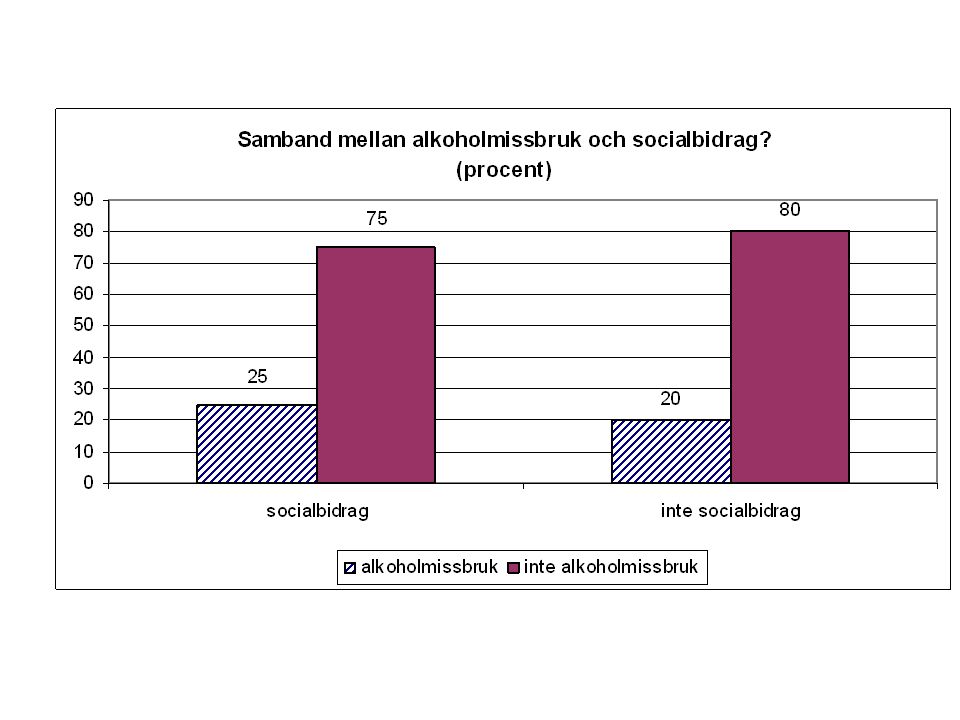
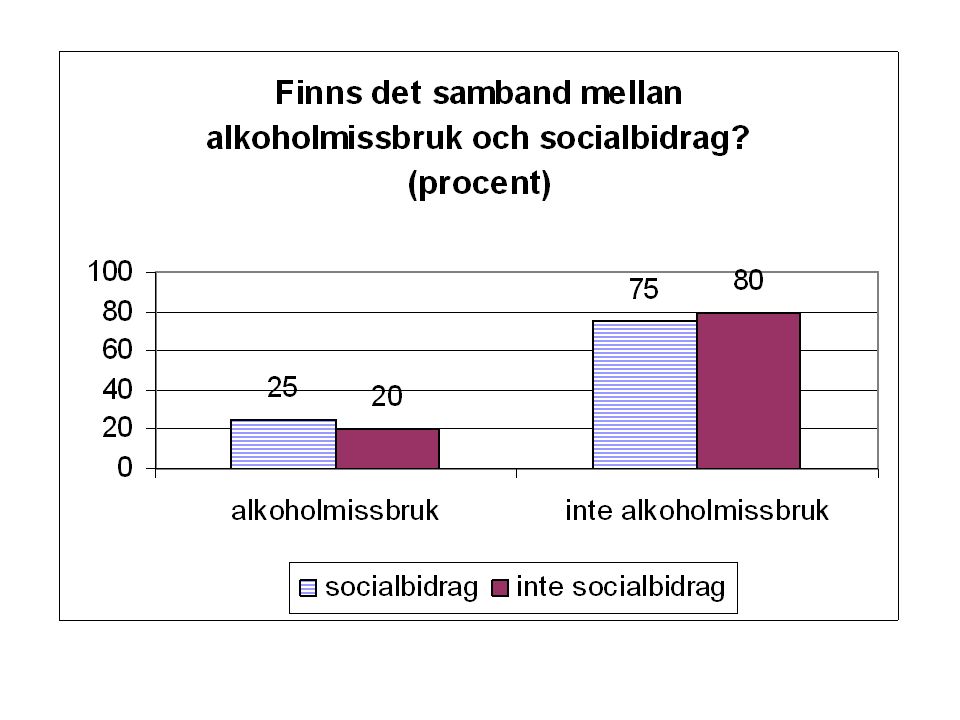
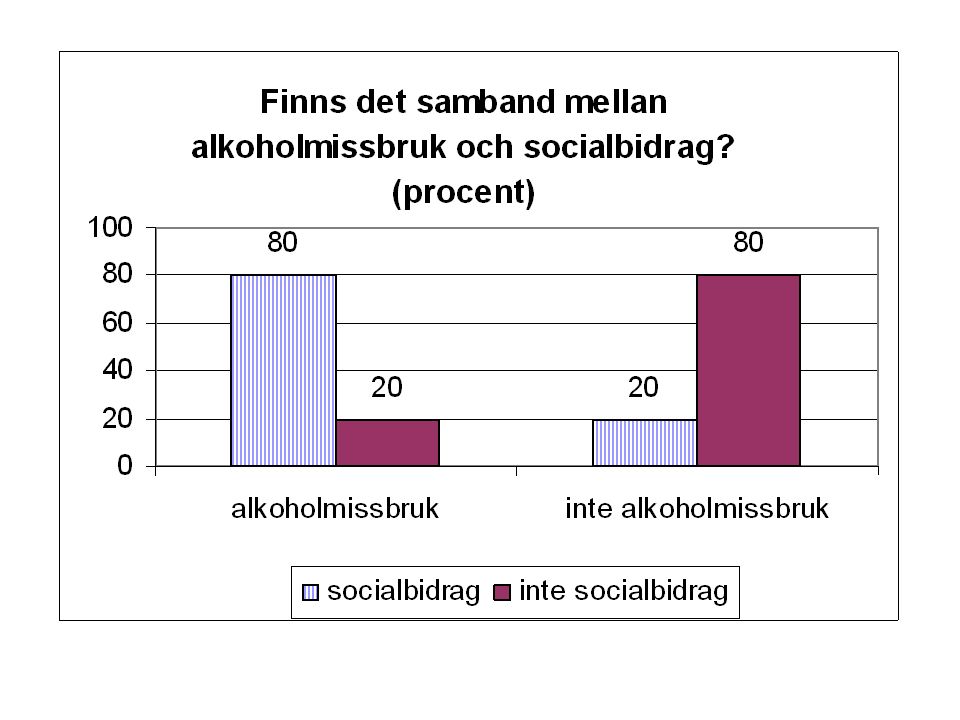
Exempel En studie har gjorts för att undersöka om det finns ett samband mellan socialbidrag och alkholmissbruk. 400 personer deltog i studien. Följande resultat erhölls: Socialbidrag JANEJ Alkohol missbruk JA5040 NEJ150160 Totalt200

8
Finns det samband mellan alkoholmissbruk och socialbidrag? Socialbidrag JANEJ Alkohol missbruk JA50/200= (25%) 40/200= (20%) NEJ 150 (75%) 180 (80%) Totalt200
 40/200= (20%) NEJ 150 (75%) 180 (80%) Totalt200.")
12
Test av samband mellan två kvalitativa variabler Vi kan använda ett Chitvå-test när vi vill ta reda på om två variabler är oberoende av varandra. Vi vill testa: Hypotes: Andelen personer med alkoholmissbruk är lika om man har socialbidrag eller inte.

13
Test av hypoteser Ofta när man gör undersökningar så vill ha svar på olika frågor (hypoteser). Är andelen personer med alkoholmissbruk lika om man har socialbidrag eller inte? Är alla kaffesorter lika populära? Finns det någon skillnad mellan män och kvinnor när det gäller val av yrke? Har män högre lön än kvinnor?

14
HYPOTES-DEDUKTIVA METODEN HypotesUtsaga Observation Tankevärld Verklighet 1 3 2 1 Försöker förutsäga vad som kommer att hända om hypotesen stämmer 2 ” Dialog med verkligheten” Deduktion - logiskt giltigt argument (Prediktiv inferens) Induktion (Induktiv inferens)
 Induktion (Induktiv inferens)")
15
Logiskt giltiga slutsatser (exempel) Giltig Inte Giltig Hypotes: Det regnar. Utsaga: Om det regnar blir det blött på marken. Observation: Det är inte blött på marken. Slutsats: Det regnar inte. Hypotes: Det regnar. Utsaga: Om det regnar blir det blött på marken. Observation: Det är blött på marken. Slutsats: Det regnar. Ej giltig slutsats. Det kan vara blött på marken p g a andra orsaker.

16
Logiskt giltiga slutsatser (exempel) Giltig Inte Giltig Hypotes: Alla människor har 10 fingrar. Utsaga: Alla människor som jag träffar har 10 fingrar. Observation: Jag träffar en person som pga en olycka bara har 9 fingrar. Slutsats: Inte alla människor har 10 fingrar. Hypotes: Alla människor har 10 fingrar. Utsaga: Alla människor som jag träffar har 10 fingrar. Observation: Jag träffar 240 personer som alla har 10 fingrar. Slutsats: Alla människor har 10 fingrar. Ej giltig slutsats. Trots att jag inte (hittills) har träffat någon med fler eller färre fingrar betyder inte det att sådana personer inte existerar.
 har träffat någon med fler eller färre fingrar betyder inte det att sådana personer inte existerar..")
17
Motsägelsebevis Inom statistisk prövning söker vi inte direkta motsägelser i form av ”omöjliga händelser” för att förkasta hypoteser (t ex en torr mark är en omöjlig händelse vid regn, d v s om marken är torr förkastas hypotesen ”Det regnar.”) utan motsägelser i form av ”osannolika händelser”.
 utan motsägelser i form av osannolika händelser .")
18
Osannolik händelse Antag att vi misstänker att andelen personer med alkoholmissbruk är olika för de med socialbidrag och de som inte har socialbidrag och att vi vill testa denna hypotes. Nollhypotes: Andelen personer med alkoholmissbruk är lika om man har socialbidrag eller inte (inget samband) Utsaga: Om andelen personer med alkoholmissbruk är lika om man har socialbidrag eller inte så finns ingen eller endast en liten skillnad i en urvalsundersökning i andelen alkoholmissbrukare i de två grupperna. Om hypotesen är sann så är det en osannolik händelse att i en urvalsundersökning att observera en stor skillnad i andelen alkoholmissbrukare i de två grupperna.
 Utsaga: Om andelen personer med alkoholmissbruk är lika om man har socialbidrag eller inte så finns ingen eller endast en liten skillnad i en urvalsundersökning i andelen alkoholmissbrukare i de två grupperna. Om hypotesen är sann så är det en osannolik händelse att i en urvalsundersökning att observera en stor skillnad i andelen alkoholmissbrukare i de två grupperna..")
19
Exempel Vid en marknadsundersökning av fyra kaffesorter deltog 100 personer. Var och en fick provsmaka de fyra märkena i ett blindtest och säga vilken av sorterna de tycket var godast. Resultatet av testet blev följande: Sort:EllipsGexusLuberLöflia Antal pers26281630

20
Tyder försöksresultatet på att någon eller några sorter är populärare än andra, eller är alla likvärdiga? I statistiska termer kan vi formulera problemet så här: Nollhypotes: Alla kaffesorter är lika populära Mothypotes: Alla kaffesorter är inte lika populära

21
Om nollhypotesen är sann borde vi förvänta oss följande utfall av försöket: Kan vi uttala oss om huruvida nollhypotesen är sann eller ej? Sort:EllipsGexusLuberLöflia Antal pers

22
Ett sätt att mäta hur mycket den observerade tabellen avviker från den förväntade tabellen är genom att titta på skillnaderna:

23
Problem dock att avvikelsen mellan 10 och 20 är relativt större än mellan 10000 och 10010. Hur ska vi ta hänsyn till det? Dela med förväntade värdet och bilda en teststatistika :

24
Om vår nollhypotes är sann borde vara nära 0. Fråga:Är 4.64 så långt i från 0 att vi kan förkasta vår hypotes? Är detta en osannolik händelse?

25
Osannolik händelse Exempelvis så kan man välja att definiera en ”osannolik händelse” som en händelse som bara inträffar 5 gånger av 100 om hypotesen är sann. I statistiska termer kallas det att för att man har valt signifikansnivån till 0,05 ( Vanliga signifikansnivåer är 0.05, 0.01, 0.10)
.")
26
Statistikprogrammen (Excel, SPSS, Minitab…) beräknar ett s k P-värde för testet. P-värdet uttrycker sannolikheten att observera vårt värde eller ett extremare förutsatt att hypotesen är sann. Vi förkastar hypotesen om P-värdet är mindre än 0.05 (om signifikansnivå är 0,05).
..")
27
I vårt exempel så tolkar man p-värdet så här: P-värde = Sannolikheten att = 4.64 eller ännu större än 4.64 (om nollhypotesen är sann) = 0.200 Det är alltså 20% chans att få det resultat som vi fått om alla kaffesorter är lika populära. Det är inte så osannolikt…

28
När vi testade hypotesen: Alla kaffesorterna är lika populära. så erhöll vi ett p-värde på 0.20 vilket är större än 0.05. Detta gör att vi inte kan förkasta hypotesen. OBS! Vi har inte bevisat att den är sann!

29
Teststatistika Inom statistisk hypotesprövning uttrycker vi utsagorna i form av värdet på en s k teststatistika. Värdet på teststatistikan räknar man ut med hjälp av sitt stickprov. Det varierar alltså från stickprov till stickprov.

30
Utifrån vår hypotes och sannolikhetsteorin kan vi säga vad värdet på teststatistikan troligtvis kommer att bli då hypotesen är sann. Sedan drar vi ett stickprov och räknar ut värdet på teststatistikan. Får vi ett osannolikt värde förkastar vi hypotesen. I exemplet ovan var teststatistika.

31
31 P-VÄRDET Ett p-värde är sannolikheten att, om nollhypotesen är sann, få ett minst lika ”extremt” värde på teststatistikan som det vi faktiskt fått. Om p-värdet är litet har jag antingen sett något som är osannolikt eller också är hypotesen falsk. Om p-värdet tillräckligt litet (< 0.05 eller <0.01) förkastas nollhypotesen.
 förkastas nollhypotesen..")
32
Vi vill testa: Nollhypotes: Andelen personer med alkoholmissbruk är lika för de som har socialbidrag och de som inte har socialbidrag. (inget samband) Mothypotes: Andelen personer med alkoholmissbruk är olika för de med socialbidrag och de som inte har socialbidrag.
 Mothypotes: Andelen personer med alkoholmissbruk är olika för de med socialbidrag och de som inte har socialbidrag..")
33
Socialbidrag JANEJ Alkohol missbruk JA5040 NEJ150160 Totalt200

34
FörväntadSocialbidrag tabellJANEJ Alkohol missbruk JA90*200/400 =45 90*200/400 =45 NEJ 310*200/400 =155 310*200/400 =155 Vi räknar ut de förväntade värdena om nollhypotesen är sann och gör ett Chi-två test:

35
Vi jämför den observerade tabellen med den förväntade. Om tabellerna skiljer sig mycket från varandra så förkastar vi nollhypotesen. Då tror vi att det finns något samband.

36
Om nollhypotesen är sann borde vara nära 0. Är 1.43 så långt ifrån 0 att vi kan förkasta nollhypotesen? Vi jämför vårt erhållna p-värde med signifikansnivån vi har satt upp. Observerat p-värde: 0,23 Slutsats?

37
Antag att vårt data hade sett ut så här med 385 personer: Observerad tabell: Förväntad tabell: Socialbidrag JANEJ Alkohol missbruk JA5025 NEJ 150160 Tot200185 Socialbidrag JANEJ Alkohol missbruk JA39.036.0 NEJ 161.0149.0

39
Om nollhypotesen är sann borde vara nära 0. Är 8.08 så långt ifrån 0 att vi kan förkasta nollhypotesen? Vi jämför vårt erhållna p-värde med signifikansnivån vi har satt upp. Observerat p-värde: 0,004 Slutsats?

40
Eftersom p-värdet = 0,004 < 0.05 så kan vi förkasta hypotesen. Dvs det är statistiskt säkerställt att det är skillnad mellan andelen alkoholmissbrukare för de med socialbidrag och de som inte har socialbidrag. Eller det finns en signifikant skillnad mellan andelen alkohol-missbrukare för de med socialbidrag och de som inte har socialbidrag..

41
Hypotesprövning: Steg för steg Ange nollhypotes Ange mothypotes (det vi vill visa) Ange signifikansnivå α: 0.05, 0.01, 0.001 (Hur säkra vill vi vara?) Utför testet och beräkna p-värdet. Dra slutsats genom att jämföra p-värde och signifikansnivån (α). - Förkasta nollhypotesen (p-värdet < α ) - Förkasta ej nollhypotesen (p-värdet ≥ α )
. - Förkasta nollhypotesen (p-värdet < α ) - Förkasta ej nollhypotesen (p-värdet ≥ α ).")
42
Finns det samband mellan lön och kön? Kön Lön MänKvinnor 10 000-19 999 4060 20 000-29 999 2515 30 000-39 999 155 Totalt80

43
Tabellen indikerar lönediskriminering, men tabellen tar ej hänsyn till den bakomliggande variabeln utbildning. Gör en trevägsindelad tabell för variablerna! Kön Lön Utbildning

44
Finns det samband mellan lön och kön? HögutbildadLågutbildad Lön MänKvinnorMänKvinnor 10 000-19 999 10(22%)2(20%)30(86%)58(83%) 20 000-29 999 20(44%)5(50%)5(14%)10(14%) 30 000-39 999 15(33%)3(30%)0(0%)2(3%) Totalt 45(100%)10(100%)35(100%)80(100%)
2(20%)30(86%)58(83%) (44%)5(50%)5(14%)10(14%) (33%)3(30%)0(0%)2(3%) Totalt 45(100%)10(100%)35(100%)80(100%).")
45
Fler män är högutbildade därför bättre löner. Vi har bland högutbildade samma fördelning Vi har bland lågutbildade samma fördelning


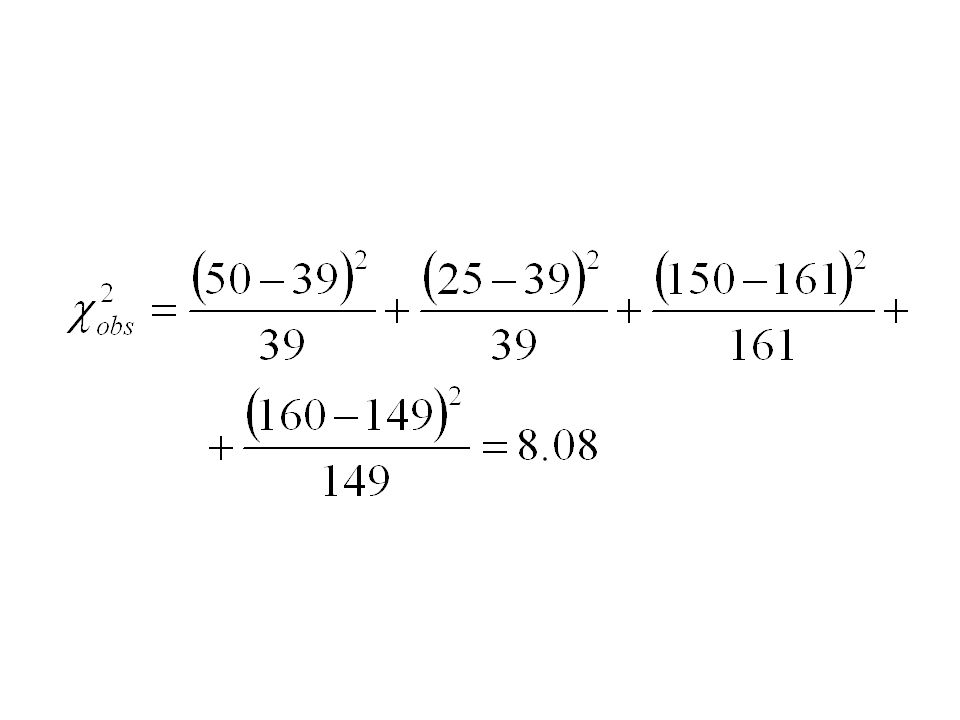



satser förutsätter giltiga eller åtminstone trovärdiga slutledningar.>")













 är i.>")

