Ladda ner presentationen
1
Lite repetition och SAMBAND & INFERENS

2
population Population Stickprov, urval INFERENS = Dra slutsatser från data om hela populationen utifrån ett stickprov Data, observationer

3
Population och urvalsram Innan undersökningen inleds måste vi definiera vilka enheter/individer som skall undersökas = målpopulationen. Därefter måste en urvalsram eller rampopulation upprättas, d v s en lista över alla enheterna. När målpopulationen och rampopulationen skiljer sig åt uppkommer s k täckningsfel (övertäckning / undertäckning)
.")
4
Varför slumpmässiga urval? Fördelen med att göra slumpmässiga urval är att vi kan generalisera resultatet till att gälla hela populationen och inte bara den grupp av personer som vi har undersökt. –OSU (Obundet slumpmässigt urval) –Systematiskt urval –Stratifierat urval –Klusterurval (gruppurval )
 –Systematiskt urval –Stratifierat urval –Klusterurval (gruppurval ).")
5
Kvalitet och felkällor Täckningsfel Bortfallsfel Mätfel Bearbetningsfel Urvalsfel

6
Mätnivåer ”Som man frågar får man svar...” Nominalskala, kön, yrke, civilstånd… Ordinalskala, attitydskalor, betyg… (Intervallskala, temperatur, kalendertid… ) Kvotskala, inkomst, vikt, längd, ålder…
 Kvotskala, inkomst, vikt, längd, ålder…")
7
Presentation av data Tabeller, diagram Centralmått - typvärde - median - kvartiler - medelvärde Spridningsmått - variationsvidd - kvartilavstånd, kvartilav. - standardavvikelse

8
Nominalskala Lämpliga tabeller, diagram etc: Frekvenstabeller, stapeldiagram (och cirkeldiagram) Lämpliga lägesmått: Typvärde (det vanligaste värdet) Lämpliga spridningsmått: -
 Lämpliga lägesmått: Typvärde (det vanligaste värdet) Lämpliga spridningsmått: -")
9
Cirkeldiagram

10
Stapeldiagram

11
Grupperat stapeldiagram

12
GulGrönBlåRöd 26281630 GulGrönBlåRöd Man1217138 Kvinna1411322

13
Ordinalskala Lämpliga tabeller, diagram etc: Frekvenstabeller, stapeldiagram och cirkeldiagram Lämpliga lägesmått: Median (och typvärde) Lämpliga spridningsmått: Variationsbredd, kvartilavstånd, kvartilavvikelse
 Lämpliga spridningsmått: Variationsbredd, kvartilavstånd, kvartilavvikelse")
14
Kvotskala (och intervallskala) Lämpliga tabeller, diagram etc: Histogram, frekvenstabeller. Stapeldiagram (och cirkeldiagram) för klassindelat material Lämpliga lägesmått: Medelvärde och median Lämpliga spridningsmått: Standardavvikelse, kvartilavstånd, kvartilavvikelse, variationsvidd
 för klassindelat material Lämpliga lägesmått: Medelvärde och median Lämpliga spridningsmått: Standardavvikelse, kvartilavstånd, kvartilavvikelse, variationsvidd.")
15
Exempel: Descriptive Statistics: Resultat Variable N Mean StDev Minimum Q1 Median Q3 Maximum Range Resultat 10 25,90 8,95 14,00 18,75 23,50 35,50 39,00 25,00 10 personers tentamensresultat noterades till: 20, 25, 22, 35, 15, 14, 22, 30, 37, 39

16
population Population: Alla som skrev tentan (Antag att antalet är stort) Stickprov. Ur populationen valdes det slumpmässigt ut 10 personer INFERENS = Om man vet att medelvärdet i stickprovet är 25.9, hur bra är denna gissning av det sanna medelvärdet? De 10 personerna fick i medeltal 25.9 poäng på tentan Sanna medelvärdet (Okänt)
.")
17
Konfidensintervall Det är svårt att ”träffa mitt i prick” och därför används konfidensintervall, dvs. ett intervall som täcker det sanna värdet i populationen med en viss säkerhet. Oftast gör man intervall med 95% eller 99% säkerhet. I vårt exempel kan ett 95%-igt konfidensintervall beräknas till:

18
Man säger att den statistiska felmarginalen är på 6.4 poäng. Dvs, vi kan vara ganska säkra på att det sanna medel- värdet i populationen ligger mellan 19.5 och 32.3 poäng. Detta eftersom vi använt en metod som, i det långa loppet, ger oss rätt i 95 % av fallen.

19
Samband Forts. Exempel Fråga: Finns det någon variabel som skulle kunna förklara variationen i tentamensresultat? Man skulle t.ex. kunna undersöka om det finns ett samband mellan tentamens-resultat och genomsnittligt antal timmar per dag som man studerat.

20
Person ABCDEFGHIJ Timmar/ Dag 4567535788 Resultat 20252235151422303739

21
Spridningsdiagram (Scatterplot) Ett spridningsdiagram är en grafisk beskrivning av samband mellan två variabler där varje punkt representerar en individ/enhet Lodrät axel (y-axeln) - beroende variabel Vågrät axel (x-axeln) - förklarande variabel Detta samband går att sammanfatta i ett mått, och det är korrelationskoefficienten
 Ett spridningsdiagram är en grafisk beskrivning av samband mellan två variabler där varje punkt representerar en individ/enhet Lodrät axel (y-axeln) - beroende variabel Vågrät axel (x-axeln) - förklarande variabel Detta samband går att sammanfatta i ett mått, och det är korrelationskoefficienten")
22
Korrelationskoefficienten Korrelationskoefficienten r är ett mått på det linjära samband mellan två kvot/intervall- variabler. Korrelationskoefficienten kan anta värden mellan –1 och +1. Observera att r är ett mått på linjärt samband. Även om r = 0 kan det finnas ett samband. Korrelationen mellan antal timmar per vecka och tentamensresultat i vårt exempel är 0,92.

23
Test av samband mellan två variabler mätta på nominal eller ordinal mätnivå När man vill ta reda på om två variabler, mätta på nominal / ordinal mätnivå, är beroende av varandra så kan man använda sig av ett Chitvå- test ( χ 2 -test ).
.")
24
Exempel: En studie har gjorts för att undersöka om det finns ett samband mellan var man är född (norr alt. söder om Sundsvall) och om man föredrar pizza eller hamburgare. 65 personer deltog i studien. Följande resultat erhölls: HamburgarePizza Född Norr om S1526 Söder om S321
 och om man föredrar pizza eller hamburgare. 65 personer deltog i studien. Följande resultat erhölls: HamburgarePizza Född Norr om S1526 Söder om S321.")
25
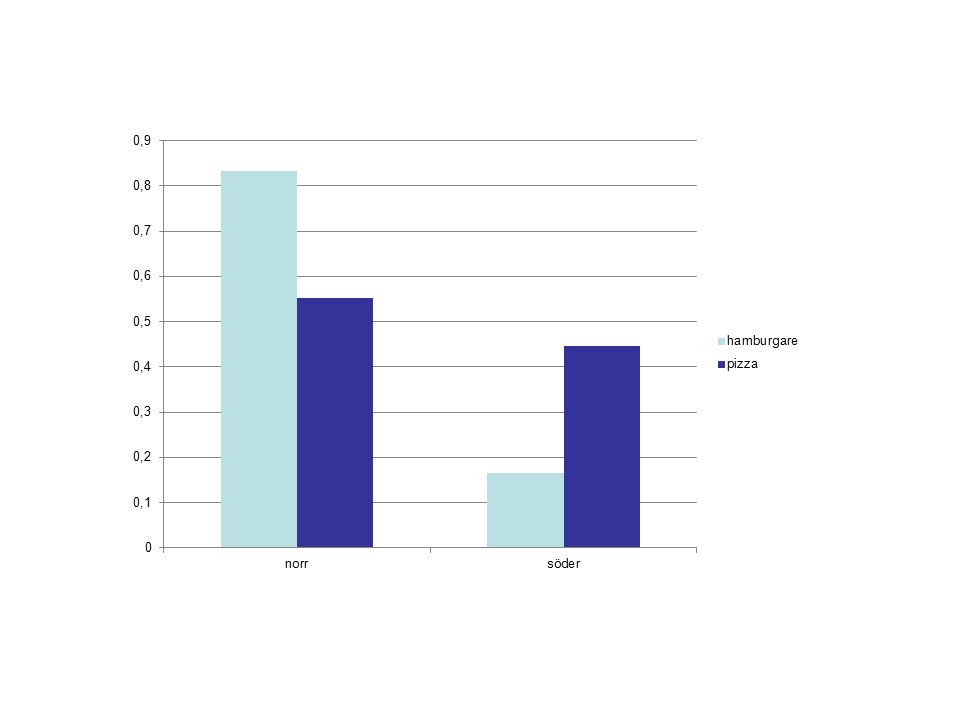
Samband mellan född norr el söder om Sundsvall och om man föredrar pizza eller hamburgare

27
HamburgarePizza Norr om S83%55% Söder om S17%45% Det ser ut som om personer som är födda norr om sundsvall är mer förtjust i hamburgare än de som är födda söder om sundsvall. Fråga: Är det slumpen som är orsaken till detta samband eller är det så att sambandet är statistiskt säkerställt.

28
Test av hypoteser Ofta när man gör undersökningar så vill ha svar på olika frågor (hypoteser). Finns det någon skillnad mellan män och kvinnor när det gäller frukostvanor? Har män högre lön än kvinnor? Föredrar personer som är födda norr om sundsvall hamburgare i större utsträckning än de som är födda söder om sundsvall? etc.

29
Hypotetisk-Deduktiv metod Metoden innebär: 1.Att formulera en hypotes. 2.Att härleda konsekvenser som logiskt måste följa av hypotesen. 3.Att undersöka om dessa konsekvenser stämmer överens med verkligheten.

30
LOGISKT GILTIGA SLUTSATSER (EXEMPEL) Giltig Inte Giltig Hypotes: Alla svanar är vita. Utsaga: Om vi ser en svan så måste den vara vit. Observation: Svanen är svart. Slutsats: Förkasta hypotesen. Alla svanar är inte vita. Hypotes: Alla svanar är vita. Utsaga: Om vi ser en svan så måste den vara vit. Observation: Svanen är vit. Slutsats: Hypotesen är sann. Alla svanar är vita. Ej giltig slutsats. Det kan finnas andra färger!

31
Motsägelsebevis Inom statistisk prövning söker vi inte direkta motsägelser i form av ”omöjliga händelser” för att förkasta hypoteser, utan motsägelser i form av ”osannolika händelser”. Exempel: Hypotes: Andelen hamburge-fantaster är lika oavsett om man är född söder eller norr om sundsvall. Fråga: Är det osannolikt stor skillnad mellan andelen hamburge-fantaster norr om sundsvall kontra sönder om sundsvall om hypotesen skulle vara sann?

32
Osannolik händelse Exempelvis så kan man välja att definiera en ”osannolik händelse” som en händelse som bara inträffar 5 gånger av 100 om hypotesen är sann. I statistiska termer kallas det att för att man har valt signifikansnivån (α)till 0,05 ( Vanliga signifikansnivåer är 0.05, 0.01, 0.10)
till 0,05 ( Vanliga signifikansnivåer är 0.05, 0.01, 0.10).")
33
Teststatistika Inom statistisk hypotesprövning uttrycker vi utsagorna i form av värdet på en s k teststatistika. Värdet på teststatistikan räknar man ut med hjälp av sitt stickprov. Det varierar alltså från stickprov till stickprov. Utifrån vår hypotes och sannolikhetsteorin kan vi säga vad värdet på teststatistikan troligtvis kommer att bli då hypotesen är sann. Sedan tar vi ett stickprov och räknar ut värdet på teststatistikan. Får vi ett osannolikt värde förkastar vi hypotesen.

34
34 p-värdet P-värdet talar om hur sannolikt det är att hypotesen är sann, eller mer korrekt: Ett p-värde är sannolikheten att, om nollhypotesen är sann, få ett minst lika ”extremt” värde på teststatistikan som det vi faktiskt fått. Om p-värdet är litet har jag antingen sett något som är osannolikt eller också är nollhypotesen falsk. Om p- värdet tillräckligt litet (< 0.05 eller <0.01) förkastas nollhypotesen.
 förkastas nollhypotesen..")
35
Hypotesprövning: Steg för steg Ange nollhypotes Ange mothypotes (det vi vill visa) Ange signifikansnivå α: 0.05, 0.01, 0.001 (Hur säkra vill vi vara?) Utför testet (beräkna teststatistikan) och beräkna p-värdet. Dra slutsats genom att jämföra p-värde och signifikansnivån (α). - Förkasta nollhypotesen (p-värdet < α ) - Förkasta ej nollhypotesen (p-värdet ≥ α )
. - Förkasta nollhypotesen (p-värdet < α ) - Förkasta ej nollhypotesen (p-värdet ≥ α ).")
36
χ 2 -test testar om det finns ett samband mellan nominal- och/eller ordinal-skalevariabler Exempel 1: En studie har gjorts för att undersöka om det finns ett samband mellan var man är född (norr/söder om sundsvall) och om man föredrar hamburgare eller pizza frukostvanor. 65 personer deltog i studien. HamburgarePizza Norr om S1526 Söder om S321

38
Nollhypotes: Det finns inget samband mellan var man är född och man fördrar hamburgare eller pizza. Mothypotes: Det finns ett samband mellan var man är född och om man föredrar hamburgare eller pizza.

39
Observerad tabell: HamburgarePizza Norr om S1526 Söder om S321

40
Om hypotesen är sann så borde vi förvänta oss följande tabell, förväntad tabell: Teststatistika: HamburgarePizza Norr om S41 Söder om S24 184765

41
Det förväntade värdet räknas ut med hjälp av följande formel:

42
Om nollhypotesen är sann borde χ obs 2 vara nära 0. Är 4.28 så långt ifrån 0 att vi kan förkasta nollhypotesen? Vi jämför vårt erhållna p-värde med signifikansnivån vi har satt upp. Här väljer vi signifikansnivån α= 0,05. Observerat p-värde: 0.036 (Excel ger oss detta värde) Slutsats?
 Slutsats .")
43
I vårt exempel så tolkar man p-värdet så här: p-värde = Sannolikheten att χ obs 2 =4.28 eller ännu större än 4.28 (om nollhypotesen är sann) = 0.036 Tolkning: Om det inte finns något samband mellan kön och frukostvanor så är det 3.6% chans att få det resultat som vi fått. Det är inte så sannolikt…

44
Eftersom p-värdet = 0,036 är mindre än 0.05(=α) så kan vi förkasta hypotesen. Dvs det är statistiskt säkerställt att det är skillnad mellan andelen som äter frukost bland kvinnor och män. Eller det finns en signifikant skillnad mellan andelen som äter frukost bland kvinnor och män.

45
Exempel 2: Är morgon-människor överrepresnterade bland de som föredrar träning framför vila? Dvs finns det något samband mellan om man är morgon/kvälls- människa och om man föredrar träning/vila?

46
kvällmorgon Träning3113 Vila202 Observerad tabell:

47
KvällMorgon Träning44 Vila22 511566 Förväntad tabell: χ obs 2 =

48
Vi observerar χ obs 2 = 3.49 Är 3.49 så långt ifrån 0 att vi kan förkasta nollhypotesen? Observerat p-värde: 0.062 Slutsats:Vi kan inte förkasta nollhypotesen. OBS! Vi har därmed inte bevisat att den är sann!

49
Två typer av fel -Typ I fel: Förkasta nollhypotesen när den är sann. -Typ II fel: Att inte förkasta nollhypotesen när den är falsk.

50
Hitintills har vi tittat på en korstabell där varje variabel bara har två värden. Man kan använda Chi2 test även där variablerna kan ha flera värden. T.ex: a)Hur skulle ni formulera nollhypotesen och mothypotesen i det här exemplet? b)P-värdet blev 0.87. Vad drar ni för slutsats? Kön ÖgonKv.ManTot. Blå29736 Brun628 Annat15520 Totalt50 1464
Hur skulle ni formulera nollhypotesen och mothypotesen i det här exemplet. b)P-värdet blev Vad drar ni för slutsats. Kön ÖgonKv.ManTot. Blå29736 Brun628 Annat15520 Totalt")
51
SLUT! Lycka till med era egna analyser!












>")









