Ladda ner presentationen
1
Medicinsk statistik Läkarprogrammet HT 2012

2
Medicinsk statistik Varför behöver Ni kunskap i medicinsk statistik? Självständigt arbete Kunna tolka resultat från andra studier Analysera data Presentera resultat

3
Medicinsk statistik Varför behöver Ni kunskap i medicinsk statistik? Självständigt arbete Kunna tolka resultat från andra studier Analysera data Presentera resultat

4
Medicinsk statistik Exempel på självständiga arbeten från ISEX-studenter 1.Studie bland mönstrade män i Skåne: Undersöka om det finns något samband mellan hur mycket man har sin mobiltelefon i byxfickan (antal timmar/dygn; 4) och spermiekvaliteten (andelen spermier med god rörlighet). 2.Studie i Tanzania: Etiologin till låg födelsevikt i området. Hur beräknar man konfidensintervallet till andelen med låg födelsevikt? 3.Djurstudie: Inducerade pankreatit (bukspottkörtelinflammation) i möss och jämförde MPO- aktiviteten (myeloperoxidas, ett neutrofilprotein) som ett mått på inflammation i pankreas. Fyra grupper med 5-8 djur/grupp, dvs ”litet” antal.
 i möss och jämförde MPO- aktiviteten (myeloperoxidas, ett neutrofilprotein) som ett mått på inflammation i pankreas. Fyra grupper med 5-8 djur/grupp, dvs litet antal..")
5
Medicinsk statistik HT-2012 Tre stycken statistikföreläsningar - Susanna Lövdahl (I+II) / Jonas Björk (III) Frågestund – ett tillfälle - Övningsuppgifter delas ut innan - ”Drop-in statistikhjälp”
 / Jonas Björk (III) Frågestund – ett tillfälle - Övningsuppgifter delas ut innan - Drop-in statistikhjälp")
6
Medicinsk statistik INNEHÅLL Deskriptiv/beskrivande statistik Medelvärdesjämförselser Icke-parametriska test Tolkning av p-värden/konfidensintervall Proportionstal Korrelation Linjär regression Dimensionsberäkning/Statistik styrka

7
Medicinsk statistik LÄSTIPS Jonas Björk ”Praktisk statistik för medicin och hälsa” 395 kr (Bokus)
")
8
Medicinsk statistik Kompendium Biostatistik och epidemiologi – Anna Axmon http://www.med.lu.se/labmedlund/amm/utbildning Bra artiklar Statistisk styrka: Colomb MO and Stevens A. Power analysis and sample size calculations. Current Anaesthesia & Critical Care ”2008;19:12-14. Signifikanstest: Sterne JAC and Smith GD. Sifting the evidence – what’s wrong with significance tests? BMJ 2001;322:226-31. Statistics Notes in the British Medical Journal (praktiskt inriktade statistikartiklar): http://www-users.york.ac.uk/~mb55/pubs/pbstnote.htm
:")
9
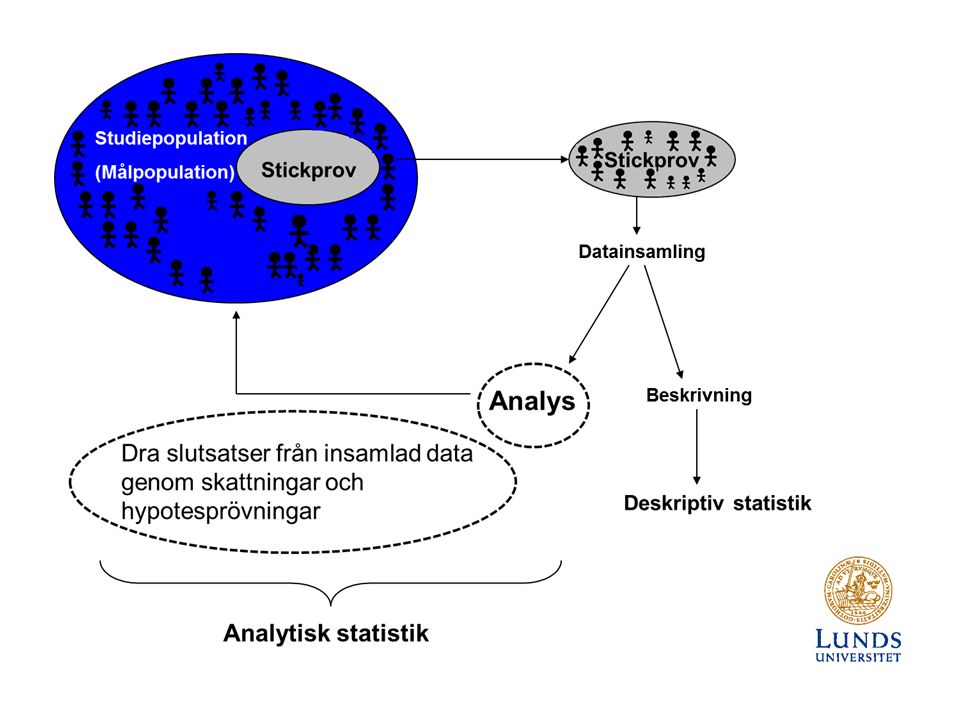
Studiepopulation (Målpopulation) Stickprov AnalysBeskrivning Deskriptiv statistik Datainsamling Dra slutsatser från insamlad data genom skattningar och hypotesprövningar Analytisk statistik
 Stickprov AnalysBeskrivning Deskriptiv statistik Datainsamling Dra slutsatser från insamlad data genom skattningar och hypotesprövningar Analytisk statistik")
10
Datatyper Kontinuerliga data – mäts på en skala Exempel: Vikt, längd, ålder, blodtryck etc. Diskreta data – Kontinuerliga data som bara kan anta vissa värden Exempel: Antal barn Värdena är ”sanna” 2-1 = 3-2 4 är dubbelt så mycket som 2

11
Datatyper Ordinaldata – klassdata/kategoriindelning med rangordning Exempel: 1 < 2 < 3 Ej säkert att 2-1 = 3-2 Ej säkert att 4 är dubbelt så mycket som 2 Ålderskategorier Självskattning Nominaldata – klassdata/kategoriindelning utan rangordning Exempel: Kön, bostadsort, civilstånd

12
Studiepopulation (Målpopulation) Stickprov Analys Beskrivning Deskriptiv statistik Datainsamling Dra slutsatser från insamlad data genom skattningar och hypotesprövningar Analytisk statistik
 Stickprov Analys Beskrivning Deskriptiv statistik Datainsamling Dra slutsatser från insamlad data genom skattningar och hypotesprövningar Analytisk statistik")
13
Deskriptiv statistik Beskrivning av materialet – utan att ge alla siffror Grafiskt Numeriskt Två viktiga frågor: Var ligger tyngdpunkten Hur stor är spridningen

14
Var ligger tyngdpunkten? Hur kan tyngdpunkten anges?

15
Tyngdpunkten kan anges genom Medelvärde - Summan av observationerna delat med antalet observationer Median - Det mittersta värdet när man sorterat observationerna i storleksordning (om udda antal) Exempel: 0, 4, 5, 6, 7, 10, 11, 12, 20 - Om jämnt antal observationer – medelvärdet av de två värdena i mitten Exempel: 6, 0, 4, 10, 12, 7, 11, 5 sortera 0, 4, 5, 6, 7, 10, 11, 12 0, 4, 5, 6, 7, 10, 11, 12 medelvärdet av 6 och 7 = 6.5. Typvärde - Det mest förekommande värdet

16
Tyngdpunkten brukar refereras till som CENTRALMÅTT eller LÄGESMÅTT Valet görs utifrån hur data ser ut Symmetriska kontinuerliga data Assymetriska kontinuerliga data Ordinaldata Nominaldata

17
Tyngdpunkten brukar refereras till som CENTRALMÅTT eller LÄGESMÅTT Valet görs utifrån hur data ser ut Symmetriska kontinuerliga data Assymetriska kontinuerliga data Ordinaldata Nominaldata

18
Symmetriska kontinuerliga data Medel = Median Exempel: Födelsevikt, längd I figuren: Medelvärde = 24 Median = 24 Använd medelvärdet!

19
Tyngdpunkten brukar refereras till som CENTRALMÅTT eller LÄGESMÅTT Valet görs utifrån hur data ser ut Symmetriska kontinuerliga data Assymetriska kontinuerliga data Ordinaldata Nominaldata

20
Assymetriska kontinuerliga data Data förskjutet åt höger eller åt vänster Medelvärdet < Medianen Medelvärdet > Medianen I figuren: Medelvärdet = 8 Medianen = 5 Använd medianen!

21
Tyngdpunkten brukar refereras till som CENTRALMÅTT eller LÄGESMÅTT Valet görs utifrån hur data ser ut Symmetriska kontinuerliga data Assymetriska kontinuerliga data Ordinaldata Nominaldata

22
Ordinaldata I figuren: Median = F Använd median!

23
Varför inte alltid använda medelvärdet? Exempel I en enkätundersökning fanns följande fråga: Hur ofta tränar du? Aldrig 1-4 gånger i månaden 5-8 gånger i månaden Mer än 8 gånger i månaden 0 poäng 1 poäng 3 poäng 5 poäng Medelvärdet blir beroende av hur man kodar variabeln!

24
Tyngdpunkten brukar refereras till som CENTRALMÅTT eller LÄGESMÅTT Valet görs utifrån hur data ser ut Symmetriska kontinuerliga data Assymetriska kontinuerliga data Ordinaldata Nominaldata

25
Ange exempelvis andelar. Här är lägesmått inte meningsfulla. I figuren: Malmö = 24% Göteborg = 50% Stockholm = 26%

26
Sammanfattning Lägesmått Symmetriska data Medelvärde Asymmetriska data Median OrdinaldataMedian Nominaldata

27
Vilka lägesmått är lämpliga i dessa studier? Studie i Tanzania: Etiologin till låg födelsevikt i området. Hur ofta ungdomar dricker alkohol: Aldrig 1p Sällan 2p Ofta 3p Undersöka hur många män respektive kvinnor som jobbar på Lunds universitet.

28
Sammanfattning LägesmåttSpridning?? Symmetriska data Medelvärde Asymmetriska data Median OrdinaldataMedian Nominaldata---

29
Spridning Liten spridning Stor spridning

30
Spridningsmått Beskriver hur pass koncentrerade data är kring centralvärdet Olika mått används för symmetriska och assymetriska data –Symmetri – spridningsmått baseras på medelvärde –Assymetri – spridningsmått baseras INTE på medelvärde

31
Spridningsmått Om vi kollar på den genomsnittliga avvikelsen från medelvärdet: Men den genomsnittliga avvikelsen från medelvärdet blir 0. x(x-x) 150 152 161 177 155 160 162 158 -9.375 -7.375 1.625 17.625 -4.375 0.625 2.625 -1.375 0
")
32
Spridningsmått Genom att kvadrera varje term så slipper vi problemet med att det blir 0. För att få bättre skattning så använder man n-1 i nämnaren Detta kallas för VARIANSEN! Men variansen är nu uttryckt i cm vilket inte är så praktiskt när medellängden är uttryckt i cm. 150 152 161 177 155 160 162 158 -9.375 -7.375 1.625 17.625 -4.375 0.625 2.625 -1.375 x (x-x) 2 87.89 54.39 2.64 310.64 19.14 0.39 6.89 1.89 0483.87 2 = 60.48
 =")
33
Spridningsmått Genom att ta roten ur variansen så får man standardavvikelsen (standard deviation = SD) som har samma enhet som det man mäter
 som har samma enhet som det man mäter")
34
Percentiler Beskriver hur stor andel av observationerna som ligger under värdet 10% ligger under 10:e percentilen 20% ligger under 20:e percentilen etc Om man har många observationer så kan man använda formeln q·(n+1)/100 för att få fram den q:te percentilen Kvartiler Delar upp data i fyra lika stora delar; Q1 = (n+1)/4, Q2 = 2(n+1)/4 (Median), Q3 = 3(n+1)/4 Undre kvartilen – 25:e percentilen Medianen – 50:e percentilen Övre kvartilen – 75:e percentilen Interkvartilintervall = kvartilavstånd = skillnad mellan övre och undre kvartilen Symmetri
/100 för att få fram den q:te percentilen Kvartiler Delar upp data i fyra lika stora delar; Q1 = (n+1)/4, Q2 = 2(n+1)/4 (Median), Q3 = 3(n+1)/4 Undre kvartilen – 25:e percentilen Medianen – 50:e percentilen Övre kvartilen – 75:e percentilen Interkvartilintervall = kvartilavstånd = skillnad mellan övre och undre kvartilen Symmetri")
35
Variationsvidd (range) Avståndet mellan det högsta och lägsta värdet kallas variationsvidd Kan användas för både symmetriska och asymmetriska data
 Avståndet mellan det högsta och lägsta värdet kallas variationsvidd Kan användas för både symmetriska och asymmetriska data")
36
LägesmåttSpridning Symmetriska data Medelvärd e Varians/sta ndardavvikel se Asymmetrisk a data MedianPercentiler OrdinaldataMedianPercentiler Nominaldata--- Sammanfattning

37
Hur vet vi om det är symmetriskt? Grafiskt se om värdena ser symmetriska ut Medianen och medelvärdet skall vara lika Avståndet mellan median och symmetriska percentiler skall vara lika stora, t.ex. jämföra avståndet av övre kvartilen med medianen och undre kvartiel med medianen. Dessa avstånd skall vara lika. Max Min Övre kvartil Median Undre kvartil

38
Hur vet vi om det är symmetriskt?

39
Normalfördelningen Symmetrisk fördelning runt sitt medelvärde Referensintervall Medelvärdet ± 1 SD täcker 68% av data Medelvärdet ± 2 SD täcker 95% av data Medelvärdet ± 3 SD täcker 99.7% av data X=medelvärde S=SD=standardavvikelse

40
Stickprov jämfört med studiepopulation Populationen vill man kunna dra slutsatser om Är de individer som man inte kan mäta plus stickprovet POPULATION

41
Stickprov jämfört med studiepopulation Stickprov hjälper oss att uppskatta och dra slutsatser om en population där stickprovet blev taget POPULATION Stickprov Stickprovet är de individer som man mäter på Man kan ta reda på ”allt” om stickprovet

42
Studiepopulation (Målpopulation) Stickprov Analys Beskrivning Deskriptiv statistik Datainsamling Dra slutsatser från insamlad data genom skattningar och hypotesprövningar Analytisk statistik
 Stickprov Analys Beskrivning Deskriptiv statistik Datainsamling Dra slutsatser från insamlad data genom skattningar och hypotesprövningar Analytisk statistik")
43
Skattningar – standardfel (medelfel) Varje skattning har en osäkerhet Osäkerheten kan mätas med standardfelet (standard error, SE eller standard error of the mean, SEM) s= standardavvikelsen n=antal observationer Ju större n ju mindre blir SE
 Varje skattning har en osäkerhet Osäkerheten kan mätas med standardfelet (standard error, SE eller standard error of the mean, SEM) s= standardavvikelsen n=antal observationer Ju större n ju mindre blir SE")
44
Standardfel - exempel Medellängden hos individer i två populationer Stor spridning Resenärer på flyg till Mallorca Medelvärde=150cm; standardavvikelse=25 Liten spridning Barn i årskurs 5 Medelvärde=150cm; standardavvikelse=10

45
100 observationer Medel = 150,4 s = 28,9 SE = 2,9 100 observationer Medel = 149,2 s = 8,6 SE = 0,9 MallorcaresenärerElever i årskurs 5 10 observationer Medel = 141,2 s = 32,4 SE = 10,2 10 observationer Medel = 149,2 s = 8,2 SE = 2,6 Medel=150, s=25 Medel=150, s=10 Standardfel - exempel

46
Sammanfattning Punktskattningar - Stickprovet används för att skatta värden i studiepopulationen - Medelvärdet och standardavvikelse är exempel på punktskattningar. Osäkerhet - Standardfel är ett mått på osäkerheten i punktskattningen - Ju mindre SE, desto säkrare punktskattning

47
Konfidensintervall SE kan användas för att beräkna ett konfidensintervall (KI) Med en viss säkerhet täcker konfidensintervallet det sanna värdet Konfidensintervallets bredd beror av –Storleken på SE (och därmed antalet individer i stickprovet samt spridningen) –Konfidensgraden – hur säker man vill vara
 Med en viss säkerhet täcker konfidensintervallet det sanna värdet Konfidensintervallets bredd beror av –Storleken på SE (och därmed antalet individer i stickprovet samt spridningen) –Konfidensgraden – hur säker man vill vara")
48
”Sanna” medelvärdet Om vi tar 100 stycken stickprov och beräknar KI för varje stickprov så kommer vissa att inkludera det ”sanna” värdet och vissa inte Antalet KI som täcker det sanna värdet beror på konfidensgraden Exempel 95% konfidensgrad 95 av 100 KI täcker det sanna medelvärdet Motsvarande gäller för andra konfidensgrader ex 90% eller 99%

49
Beräkning av konfidensintervall Generell formel för konfidensintervall Skattning ± konstant*SE Konfidensgrad på 90% ger en konstant = 1.64 Konfidensgrad på 95% ger en konstant = 1.96 Konfidensgrad på 99% ger en konstant = 2.58

50
Konfidensintervall Exempel Resenärer till Mallorca Tar ut ett stickprov på 100 individer Beräknar ett 95% KI x 1.96*SE = 150.4 ± 1.96*2.9 = [144.7;156.1] I studiepopulationen ligger medellängden med 95% sannolikhet mellan 144.7 och 156.1 cm. Det ”sanna” medelvärdet ligger med 95% säkerhet i intervallet medelvärdet ± 2*SE ±
![Konfidensintervall Exempel Resenärer till Mallorca Tar ut ett stickprov på 100 individer Beräknar ett 95% KI x 1.96*SE = ± 1.96*2.9 = [144.7;156.1] I studiepopulationen ligger medellängden med 95% sannolikhet mellan och cm.](http://images.slideplayer.se/40/11158135/slides/slide_50.jpg "Det sanna medelvärdet ligger med 95% säkerhet i intervallet medelvärdet ± 2*SE ±.")
51
Referensintervall Ett referensintervall säger något om spridningen i studiepopulationen Istället för att använda SE används standardavvikelsen, s.

52
Referensintervall Exempel Stickprov om 100 individer till Mallorcapopulationen Beräkning av 95% referensintervall = 150,4 ± 1.96*28.9 = [93.8; 207.0] 95% av studiepopulationen bör vara mellan 94 och 207 cm Intervallet ”medelvärde ± 2* standardavvikelser ” täcker 95% av data i studiepopulationen
![Referensintervall Exempel Stickprov om 100 individer till Mallorcapopulationen Beräkning av 95% referensintervall = 150,4 ± 1.96*28.9 = [93.8; 207.0] 95% av studiepopulationen bör vara mellan 94 och 207 cm Intervallet medelvärde ± 2* standardavvikelser täcker 95% av data i studiepopulationen](http://images.slideplayer.se/40/11158135/slides/slide_52.jpg "Referensintervall Exempel Stickprov om 100 individer till Mallorcapopulationen Beräkning av 95% referensintervall = 150,4 ± 1.96*28.9 = [93.8; 207.0] 95% av studiepopulationen bör vara mellan 94 och 207 cm Intervallet medelvärde ± 2* standardavvikelser täcker 95% av data i studiepopulationen")
53
Sammanfattning Konfidensintervall och referensintervall är beräknade baserat på data från stickprovet men drar slutsatser om studiepopulationen! KONFIDENSINTERVALL: Medelvärdet i studiepopulationen ligger med 95% säkerhet inom gränserna REFERENSINTERVALL: 95% av studiepopulationen har ett värde inom gränserna

54
Förutsättningar för konfidens – och referensintervall Stickprovet måste vara representativt för studiepopulationen Kontinuerlig data måste vara normalfördelade Stickprovet är normalfördelat Studiepopulationen är normalfördelad Stickprovet stort

55
Hur gör vi med data som inte är kontinuerliga/normalfördelade?

56
Exempel Ett nytt läkemedel ska testas. Hur många kände sig bättre av det nya läkemedlet?

57
Konfidensintervall för en andel Antag att q = punktskattningen q är andelen i stickprovet, q ligger mellan 0-1 Konfidensintervall för andelar beräknas n=antalet individer i stickprovet c=konstant (samma som i tidigare beräkningar) Förutsättning: q*(1-q)*n > 5
 Förutsättning: q*(1-q)*n > 5")
58
Konfidensintervall för en andel Exempel: Ett nytt läkemedel ska testas. Hur många kände sig bättre av det nya läkemedlet? En studie med 100 individer, n=100 q=andel som kände sig bättre av det nya läkemedlet. A=70% Konfidensgrad=95% c=1.96

59
Exempel fortsättning 95% KI: Med 95% säkerhet ligger den ”sanna” andelen som föredrar det nya läkemedlet mellan 61% och 79%

60
Hypotesprövning Ett stickprov väljs för att dra slutsatser om en studiepopulation Det går inte att bevisa något om en studiepopulation Däremot kan man avfärda en teori som är mer eller mindre troligt Detta gör man genom hypotesprövningar

62
Hypotesprövning Man sätter upp en nollhypotes (H0) H0 vill man kunna förkasta/avfärda ex. ingen effekt Om H0 förkastas så finns en alternativhypotes kvar (H1) H0: Ingen effekt H1: Effekt
 H0: Ingen effekt H1: Effekt.")
63
Att uttrycka hypoteser Hypoteser går att uttrycka på många olika sätt Bäst att uttrycka hypoteser så numerisk som möjligt Ex. H 0 : Medelvärdet för behandlade = Medelvärdet för kontroller H 1 : Medelvärdet för behandlade Medelvärdet för kontroller

64
Exempel Vi vill undersöka om det finns lika många kvinnor som män som läser medicinsk statistik på Lunds universitet. Vilka hypoteser testas i denna studie? Hur ser H0 respektive H1 ut?

65
H0: Andelen kvinnor = andelen män H1: Andelen kvinnor andelen män H0: Andelen kvinnor - andelen män = 0 H1: Andelen kvinnor - andelen män 0 H0: Andelen kvinnor = 50% H1: Andelen kvinnor 50%

66
Hypotesprövning med p-värde Studie- population Stickprov Sannolikhet? (p = probability) Studiepopulation där H 0 är sann! Stickprov där H 0 inte verkar stämma!
 Studiepopulation där H 0 är sann. Stickprov där H 0 inte verkar stämma!.")
67
Hypotesprövning med p-värde P-värdet är sannolikheten att man får det resultat man fick (eller ännu mer extremt) om H0 är sann Mer extremt menar man ett värde som ligger längre ifrån nollhypotesen än det värde som man har fått fram P-värdet är en sannolikhet som ligger mellan 0% och 100% Exempel: Undersökning av om det finns lika många kvinnor som män som läser medicinsk statistik vid Lunds universitet. H0: Andelen kvinnor = 50% H1: Andelen kvinnor 50% Vi har hittat att 55% som läser medicinsk statistik vid Lunds universitet är kvinnor. P-värdet kommer att ge oss sannolikheten att vi hittar ett stickprov med 61% kvinnor eller mer givet att H0 är sann (dvs. om vi hade undersökt hela studiepopulationen så skulle det bara finnas 50% kvinnor.)
.")
68
Hypotesprövning med p-värde Om p-värdet är tillräckligt litet så förkastas H0 Tillräckligt liten är en gräns som man sätter upp innan analysen utförs, signifikansnivån T.ex. 1%, 5% eller 10% Signifikansnivån + konfidensgraden = 1 Beräkning av p-värdet kan göras även om data inte är normalfördelat, men på olika sätt

69
Hypotesprövning med p-värde H0: Andelen kvinnor = 50% H1: Andelen kvinnor 50% P-värdet = 0.02 Signifikansnivå = 0.05 H0 kan förkastas eftersom 0.02 < 0.05

70
Hypotesprövning med KI Hypotesprövning kan även göras med KI Om H0 ligger inom KI:s gränser kan H0 vara det sanna värdet Vi kan inte förkasta H0 Om H0 ligger utanför KI:s gränser Förkasta H0 eftersom det då är låg sannolikhet att H0 är det sanna värdet Test med 95% KI = test med 5% signifikansgräns Hypotesprövning med p-värde och konfidensintervall ger alltid samma resultat!

71
T-fördelningen Konstanten c=1.96 i formeln Medelvärdet ± c*SE kommer från den standardiserade normalfördelningen vid konfidensgraden 95% För små stickprov blir KI för snäva, går inte upp till den önskade konfidensgraden Hur löser vi det?

72
T-fördelningen Vi löser det genom att använda t-fördelningen med n-1 frihetsgrader för att bestämma konstanten c - Ex. om vi har n=10 så blir antalet frihetsgrader 10-1=9 I en tabell kan man ta reda på att c=2.26

73
T-fördelningen En fördelning som mycket påminner om normalfördelningen men som för små stickprov gör att vi bättre uppnår den önskade konfidensgraden Vad är små stickprov?

74
Tumregel - stickprovsstorlek Antal oberoende observationerTumregel n<20 Beräkna bara konfidensintervall om det sedan tidigare är känt att den variabel som studeras är normalfördelad. Använd t-fördelningen med n-1 frihetsgrader för att bestämma konstanten c n: 20-50Beräkna konfidensintervall om mätvariabeln är någorlunda normalfördelad. Använd t-fördelningen med n-1 frihetsgrader för att bestämma konstanten c n>50Konfidensintervall kan beräknas oavsett hur variabeln som undersöks är fördelad i studiepopulationen. Den standardiserade normalfördelningen ger fortfarande något för låga värden på c; skillnaden jämfört med korrekta värdet hämtat från t-fördelningen är dock försumbart

75
Parametriska och icke parametriska test t-testet är ett s.k. PARAMETRISKT TEST Namnet ”parametriskt” kommer från att det bygger på användandet av specifika parametrar, - normalfördelningens parametrar. Normalfördelningens parametrar är det som definierar fördelningen - medelvärdet och variansen.

76
Parametriska och icke parametriska test Test som inte bygger på parametrar kallas ICKE-PARAMETRISKA TEST eller FÖRDELNINGSFRIA TEST Dessa använder observationernas ranger i i stället för värdena Kommer mer om detta i nästa föreläsning!

77
Parametriska och icke parametriska test Parametriskt Icke-parametriskt Utförs på Värden Ranger Kräver Ja Nej Normalfördelning Skattar effekt Ja Nej med KI P-värde Ja Ja

78
Lästips - Beskrivande statistik Kapitel 3 - Normalfördelningen/Referensintervall Kapitel 5 - Hypoteser/p-värden/konfidensintervall Kapitel 6, 7, 9.1-9.2, 12.1














>")






