Ladda ner presentationen
Presentation laddar. Vänta.

1
Maria Holmqvist 23 februari 2011
Korpuslingvistik Maria Holmqvist 23 februari 2011

2
Vad är en korpus? Från corpus (latin): kropp
“text som är föremål för språkvetenskapligt studium” (Svensk Ordbok) “A body of texts, utterances, or other specimens considered more or less representative of language and usually stored electronically...” (The Oxford Companion to the English Language) Korpuslingvistik är språkliga studier av korpusdata. 2
 A body of texts, utterances, or other specimens considered more or less representative of language and usually stored electronically... (The Oxford Companion to the English Language) Korpuslingvistik är språkliga studier av korpusdata. 2.")
3
Rationalism vs. Empirism
Lingvistiska studier Rationalism språkets uppbyggnad, grammatisk/icke-grammatiskt lingvistisk kompetens introspektion som metod vad som är teoretiskt möjligt Empirism Språkanvändning Hur används språket i text och tal? I vilka genrer? Av vilka författare/talare? … 3

4
Rationalism vs. Empirism
Competence Performance “time flies like an arrow” “öh, va- vaddå ... va, varför sa han... närdå?”

5
Kritik mot den tidiga korpuslingvistiken
Tidsödande Osystematiskt Inkonsekvent

6
Pendeln svänger ... Kritik mot introspektion som metod:
icke observerbart (och därför inte verifierbart) artificiellt (“lingvistmeningar”) icke kvantitativt, dvs. ingen hänsyn tas till “hur vanligt” och “i vilken genre” vissa konstruktioner används. Datorutveckling och tillgång till maskinläsbar text.
 artificiellt ( lingvistmeningar ) icke kvantitativt, dvs. ingen hänsyn tas till hur vanligt och i vilken genre vissa konstruktioner används. Datorutveckling och tillgång till maskinläsbar text.")
7
Typer av textkorpusar Balanserade Genre-specifika En- och flerspråkiga
Andraspråkskorpusar (för studier av språkinlärning) Historiska (diakroniska) korpusar Översättningskorpusar och jämförbara korpusar “Ren” text och lingvistiskt uppmärkt text.
 Historiska (diakroniska) korpusar. Översättningskorpusar och jämförbara korpusar. Ren text och lingvistiskt uppmärkt text.")
8
Korpusexempel LOB-korpusen (70-tal) SUC-korpusen (90-tal)
<p n=1549> <s n=1550> <w lem='kulturlager' n=1551>Kulturlager</w> <w lem='kalla' n=1552>kallas</w> <w lem='som' msd='CCS' n=1553>som</w> <w lem='bekant' msd='AQPNSNIS' n=1554>bekant</w> <w lem='även' msd='RG0S' n=1555>även</w> ...</s></p>

9
Linköpings översättningskorpus

10
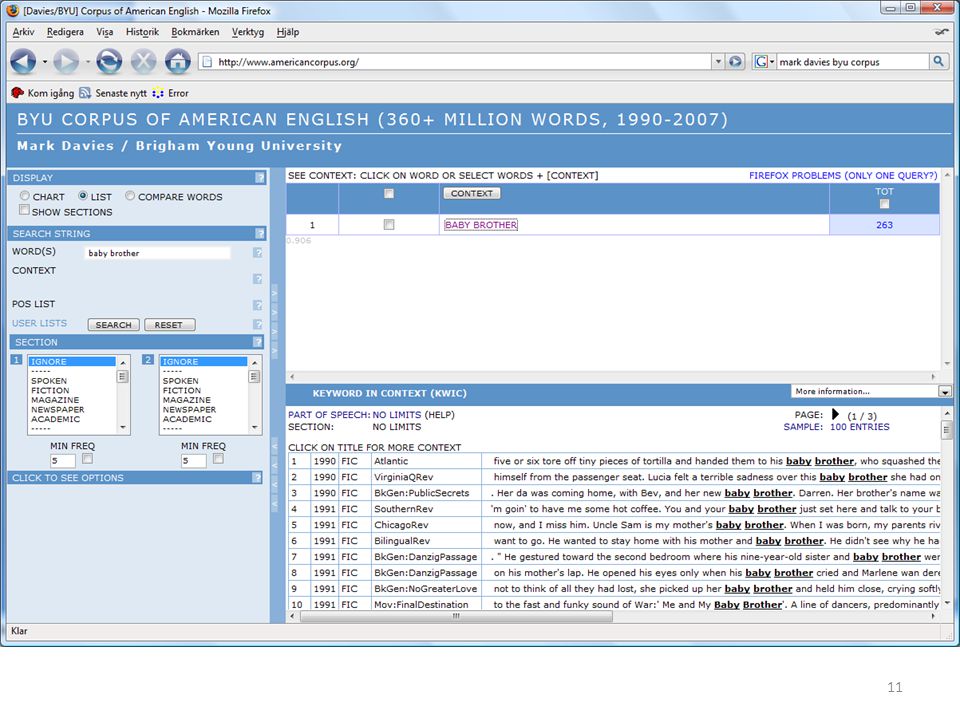
Korpusar och webbgränssnitt http://view.byu.edu/

12
Google Ngram viewer http://ngrams.googlelabs.com/
Söker efter ord och fraser i inskannade böcker i Google Books projektet N-gram Sekvens av N ord ”We need better child care” 1-gram (unigram) we, need, better, child, care 2-gram (bigram) we need need better better child child care 3-gram (trigram) we need better need better child better child care
 we, need, better, child, care. 2-gram (bigram) we need need better better child child care. 3-gram (trigram) we need better need better child better child care.")
13
Google Ngram viewer Exempel 1950-2000

14
Några sätt att undersöka sin korpus
Frekvens (jämförelse av olika texttyper, t.ex. de 50 mest frekventa orden) Fraseologi (konkordanser, jämföra användning av ord som effective och efficient i dess kontexter Kollokationer (ord som förekommer tillsammans mer än slumpen?): shed- light, shed-tears, shed-blood... 14
 Fraseologi (konkordanser, jämföra användning av ord som effective och efficient i dess kontexter. Kollokationer (ord som förekommer tillsammans mer än slumpen ): shed- light, shed-tears, shed-blood")
15
Två angreppssätt Kvantitativ analys Kvalitatitiv Räkna
Beräkna sannolikheter att X… Rangordna Identifiera ”oväntade” mönster Testa om något är signifikant eller inte Bygga statistiska modeller för översättning Kvalitatitiv Analysera och skapa definitioner Tolka data, t.ex. genom att studera konkordansresultat …

16
Frekvens (från British National Corpus)
the Det 61847 of Prep 29391 and Conj 26817 a Det 21626 in Prep 18214 to Inf 16284 it Pron 10875 is Verb 9982 to Prep 9343 was Verb 9236 I Pron 8875 for Prep 8412 that Conj 7308 you Pron 6954 he Pron 6810 be Verb 6644 with Prep 6575 on Prep 6475 by Prep 5096 at Prep 4790 have Verb 4735 are Verb 4707 not Neg 4626 this DetP 4623 's Gen 4599 but Conj 4577 had Verb 4452 they Pron 4332 his Det 4285 from Prep 4134 she Pron 3801 that DetP 3792 which DetP 3719 or Conj 3707 we Pron 3578 's Verb 3490 an Det 3430 ~n't Neg 3328 were Verb 3227 as Conj 3006 do Verb 2802 been Verb 2686 their Det 2608 has Verb 2593 would VMod 2551 there Ex 2532 what DetP 2493 will VMod 2470 all DetP 2436 if Conj 2369 can VMod 2354 her Det 2183 said Verb 2087 who Pron 2055 one Num 1962 so Adv 1893 up Adv 1795 as Prep 1774

17
Vanligaste engelska substantiven
time 1833 year 1639 people 1256 way 1108 man 1003 day 940 thing 776 child 710 Mr 673 government 670 work 653 life 645 woman 631 system 619 case 613 part 612 group 607 number 606 world 600 house 598 area 585 company 579 problem 565 service 549 place 534 hand 532 party 529 school 529 other 1336 good 1276 new 1154 old 648 great 635 high 574 small 518 different 484 large 471 local 445 social 422 important 392 long 392 young 379 national 376 british 357 right 354 early 353 possible 342 big 338 little 306 political 306 able 304 late 302

18
Vanligaste svenska säger där också eller sin under efter ut ska vid mot då här bara mycket upp över vara alla kommer vad än andra finns får in sedan du få ha hur och i att det som en på är för av med den till inte har de han om ett jag var men sig så vi hon från man kan när hade nu skulle år

19
Zipf’s lag Frekvensen av ett visst ord är omvänt proportionell mot dess ranking. Ordfrekvensen i en korpus Ett fåtal ord har mycket höga frekvenser Ett större antal ord förekommer ganska ofta Majoriteten av alla ord förekommer mycket sällan Lingvisten George Kingsley Zipf ( ) upptäckte sambandet för ordfrekvenser i engelska språket On a large corpus of English text, the 135 most frequently occurring words accounted for half of the text
 upptäckte sambandet för ordfrekvenser i engelska språket. On a large corpus of English text, the 135 most frequently occurring words accounted for half of the text.")
20
Zipf’s lag Många naturliga fenomen följer Zipf’s lag Ordfrekvenser
Antalet invånare i städer Utlånade böcker Inkomster “80/20” regeln 80% av alla tillgångar är koncentrerade till 20% av befolkningen

21
Olika typer av frekvens
Absolut frekvens = antal gånger ett visst tecken/ord förekommer. Relativ frekvens = antal gånger ett visst tecken/ord förekommer med hänsyn taget till storlek på korpusen. Ord Absolut frekvens Korpusstorlek Relativ frekvens pojke 165 165/ =0,000825 300 300/ =0,003 flicka 96 96/ =0,00048 156 156/ =0,00156

22
Jämföra frekvenser Frekvensskillnader kan återspegla skillnader i olika språkvarieteter, t.ex. vad gäller genre kön social tillhörighet historisk förändring … Kräver test för att se om skillnaden är signifikant.

23
Signifikanstest Hypotes: användningen av hjälpverben ska och skall har ändrats mellan sextio- och nittiotalet i svenska nyhetsmedier. Hypotestest: skaffa frekvensdata från Språkbanken och testa om den observerade skillnaden är signifikant. Signifikanstest: chi-square test 2 = (Oij – Eij)2 / Eij i,j
2 / Eij. i,j.")
24
Signifikanstest ska skall N Observerade värden/frekvenser (Oij)
(Data från Språkbanken) ska skall N Press 65 336 2006 991,000 Press 98 18141 7495 9,239,000 Totals 18477 9501
 ska. skall. N. Press ,000. Press ,239,000. Totals")
25
Signifikanstest 2 = (336-1830)2/1830 + (2006-940)2/940 +
2 = ( )2/1830 + ( )2/940 + ( )2/ ( )2/8561 > (dvs, väldigt högt Detta värde jämförs med ett värde i en 2-tabell. Mindre än en procents risk att detta inte är signifikant.
2/ ( )2/940 + ( )2/ ( )2/8561. > 1000 (dvs, väldigt högt. Detta värde jämförs med ett värde i en 2-tabell. Mindre än en procents risk att detta inte är signifikant.")
26
Identifiera oväntade ”händelser”
Huvudidé Om två händelser är oberoende, så är sannolikheten att de samförekommer given av produkten av deras sannolikheter: p(A&B) = p(A) x p(B) Med en korpus använder vi formeln ovan och relativa frekvenser och testar för oberoende.
 = p(A) x p(B) Med en korpus använder vi formeln ovan och relativa frekvenser och testar för oberoende.")
27
Exempel 1 (Church & Hanks, 1989*)
Leta efter händelser (dvs. ord) som samförekommer signifikant oftare med strong och powerful i en tidningstextkorpus. Ord som samförekommer med strong (i signifikansordning): support, enough, safety, sales, opposition, showing, sense, defense, gains, criticism, … Ord som samförekommer med powerful: computers, computer, symbol, machines, Germany, nation, chip, force, friends, neighbor, … *K. Church and P. Hanks: Word asociation norms, mutual information and lexicography. Proceedings of the 27th Annual Meeting of the ACL, Vancouver, Canada, 1989.
 som samförekommer signifikant oftare med strong och powerful i en tidningstextkorpus. Ord som samförekommer med strong (i signifikansordning): support, enough, safety, sales, opposition, showing, sense, defense, gains, criticism, … Ord som samförekommer med powerful: computers, computer, symbol, machines, Germany, nation, chip, force, friends, neighbor, … *K. Church and P. Hanks: Word asociation norms, mutual information and lexicography. Proceedings of the 27th Annual Meeting of the ACL, Vancouver, Canada,")
28
Example 2 (T. Holm: Översättningskorpusar och ordlänkningsprogram som resurs för tvåspråkigt ordboksarbete, LIU-KOGVET-D-0055-SE 2001) Lexikon: ancient I: a forn, forntida; [ur-] gammal Översättaren:

29
Korpusverktyg konkordansverktyg (sökning och resultat presenterade i kontext) frekvensverktyg (data om frekvenser för ord, fraser, meningar, osv.) verktyg för frasextrahering menings- och ordlänkning (s.k. alignment) märkningsverktyg (ordklassmärkning, grundformer och morfologisk information) m.m.
 märkningsverktyg (ordklassmärkning, grundformer och morfologisk information) m.m.")
30
Konkordans (SAOB)
")
31
DAVE (NLPLAB) Meningslänkning
 Meningslänkning")
32
I*Link (interaktiv ordlänkning)
")
33
I*Trix (automatisk ordlänkning)
")
34
Några exempel på automatiskt framtagna ordpar som saknades i Sveriges största engelsk-svenska ordbok
... clever - listig desk - disk evidently - av allt att döma many - åtskilliga occasionally - ibland performance - uppvisning probably - antagligen supply - förse terrible - gräslig hence - sålunda

35
Internet som textkorpus data is/are

36
apelsinen/apelsinet 16500 (apelsinen) 26400 (en apelsin)
4270 (ett apelsin)
")
37
Översättningsminnen (ett slags tvåspråkig korpus)
Hjälper översättare genom att komma ihåg hur en mening/stycke översattes förra gången används vid översättning av manualer tar fram även “nästan lika” förslag kan försämras om för många liknande översatta segment läggs in blir ofta mycket specifika: SAAB har sitt översättningsminne, Ericsson har ett annat.

38
Olika språks ord täcker begrepp olika
semantiska fält mellan olika språk överlappar semantiska speglingar fås automatiskt paw animal paw etape patte animal leg journey leg bird foot leg foot human leg chair leg pied jambe

39
Studier av språkbruk och dialekter
olika gruppers användning av språket korpusar över talat språk kan analyseras uppdelad enligt olika kriteria: i olika dialektområden vad talaren tillhör för social klass i vilket sammanhang samtalet finns formellt/informellt om bara kvinnor/män deltar om barn är närvarande

40
Hur språk förändras över tiden
analys av korpusar med texter hämtade från samma språk men olika tidsepoker ger underlag för sociolingvistiska studier av hur konventioner för t.ex. samtal ändras

41
Hur översättare arbetar
studier av vilka principer mänskliga översättare arbetar efter kan ge bättre förståelse för hur två språks grammatik hänger ihop

42
Lite om Fodina och korpuslingvistik
Fodina Language Technology AB Startade 2004 Dokumentbaserad språkteknologi 8 anställda 5 kogvetare Hjälper företag, organisationer och myndigheter att få en effektivare hantering av skrivande, översättning och språklig kvalitetskontroll.

43
Typiska saker som Fodina gör
Termextraktion ur befintlig dokumentation Manualer Patent Flerspråkig dokumentation Hur översätts termerna? Är översättningen konsekvent? Kvalitetskontrollera Termdatabaser Originaltexter Översättningar Används konsekvent terminologi för olika begrepp Bygga upp processer för företag kring dokumentation och översättning

44
PRV/EPO:s maskinöversättningssystem
Regelbaserat MT-system Uppgift: konstruera EN-SE och SE-EN termbank med termextraktion Indata: parallella dokument uppdelade på 630 subklasser Språklig och ämnesmässig validering Termer med frekvens 5 eller högre Utdata: termpar (strukturerade i en hierarkisk termdatas och i två riktningar)
")
45
Termextraktion Normalisering av texten Meningslänkning
Grammatisk analys Statistisk analys Termextraktion (ordlänkning) Export till SQL (term)databas
 Export till SQL (term)databas.")
46
Ordlänkning Röstning (moduler och resurser röstar på ”kandidater”)
Hanterar alla ord (termer och icke-termer, enkla ord flerordskonstruktioner)
")
47
Termfiltrering Ordklassberoende (inga prepositioner, artiklar, konjunktioner…) Allmänspråksfilter
 Allmänspråksfilter")
48
Sammanfattning Korpusar är samlingar av texter
Om möjligt balanserade och representativa Maskinläsbara Ibland annoterade, men inte alltid Innehållet i korpusar är empiriska forskningsobjekt för Språkforskare Språkteknologer Kan studeras kvantitativt och kvalitativt Korpusverktyg

Liknande presentationer










: •effektstudier •uses and gratifications •litterär kritik •kulturstudier.>")



>")




