Ladda ner presentationen
Presentation laddar. Vänta.

1
Datastrukturer och algoritmer
Föreläsning 14

2
Innehåll Mer om sortering Sökning i strängar/mönstermatching
Heapsort O(N*log(N)) Facksortering/Bucketsort O(N+M) Radixsort O(b*N) Sökning i strängar/mönstermatching Naiv sökning (Brute force) Knuth Morris Pratt Booyer Moore’s Rabin Karp Kapitel
) Facksortering/Bucketsort O(N+M) Radixsort O(b*N) Sökning i strängar/mönstermatching. Naiv sökning (Brute force) Knuth Morris Pratt. Booyer Moore’s. Rabin Karp. Kapitel")
3
Heapsort Man gör n insättningar i en heap och sen n avläsningar genom att plocka bort roten. Varje insättning/avläsning kostar O(log k) där k är antalet element i heapen. k < n så vi kan säga O(log n). Alltså får vi totalt O(n*log n).
 där k är antalet element i heapen. k < n så vi kan säga O(log n). Alltså får vi totalt O(n*log n).")
4
Insättning i en Heap – O(log n)
Placera den nya noden på första lediga plats. Låt sedan noden vandra uppåt i heapen tills det hamnat rätt i sorteringsordningen eller blivit rot.

5
Borttagning ur en heap – O(log n)
Ersätt noden som ska tas bort med den ”sista” noden i heapen. Låt denna vandra ned tills den hamnat ”rätt” eller nått ”botten”.

6
Facksortering (Bucket sort)
Objekten måste gå att avbilda på heltalen inom ett intervall [Vmin…Vmax] O(N+M) där N är antalet element i listan och M är Vmax-Vmin Kan göras stabil Notera! På Wikipedia kallas denna algoritm ”Pigeonhole sort”
 där N är antalet element i listan och M är Vmax-Vmin. Kan göras stabil. Notera! På Wikipedia kallas denna algoritm Pigeonhole sort")
7
Facksortering (1,a) (1,e) (1,m) (3,k) (1,a) (2,h) (2,h) (2,o) (2,y)
(9,j) 1 (1,a) (1,e) (1,m) 2 (2,h) (2,o) (2,y) (3,i) N 3 (3,k) (3,i) (2,o) (3,i) (3,k) 4 (4,p) (8,s) M 5 (1,e) 6 (4,p) (7,q) 7 (7,q) (7,q) 8 (8,s) (4,p) (8,s) 5-6 första elementen sakta, sen snabbt... 9 (9,j) (9,w) (2,y) (9,j) (9,w) Stabil om man tar sifforna ur startlistan uppifrån och ned och bygger resultatet från vänster till höger. (9,w) (1,m)
 1. (1,a) (1,e) (1,m) 2. (2,h) (2,o) (2,y) (3,i) N. 3. (3,k) (3,i) (2,o) (3,i) (3,k) 4. (4,p) (8,s) M. 5. (1,e) 6. (4,p) (7,q) 7. (7,q) (7,q) 8. (8,s) (4,p) (8,s) 5-6 första elementen sakta, sen snabbt (9,j) (9,w) (2,y) (9,j) (9,w) Stabil om man tar sifforna ur startlistan uppifrån och ned och bygger resultatet från vänster till höger. (9,w) (1,m)")
8
Varianter Låt varje fack vara ett intervall av tal och sortera sen facken för sig. Denna variant kallas av Wikipedia för Bucket Sort, Sorteringen i varje fack kan vara en ny bucket sort eller en annan sorteringsalgoritm

9
Radix Sort Radix ≈ bas Antag att talen är representerade i basen M:
Tittar på strukturen hos nycklarna Antag att talen är representerade i basen M: M=2 binära talsystemet 9 = M=10 decimala talsystemet Sorterar genom att jämföra siffror/bitar i samma position 1 1

10
Straight (LSD) Radix Sort O(bN)
for i0 to b-1 do sortera fältet på ett stabilt sätt, med avseende på i:e biten Jämför från höger till vänster… Antag att vi kan sortera fältet stabilt på O(N) => O(bN) Hur gör vi det? Facksortering O(N+b) bN ger O(N) LSD = Least Significant Digit Facksortering O(N+b) b<<N ger O(N)
 => O(bN) Hur gör vi det Facksortering O(N+b) bN ger O(N) LSD = Least Significant Digit. Facksortering O(N+b) b<<N ger O(N)")
11
Straight (LSD) Radix Sort
2 1 1 1 1 2 6 3 4 5 7 5 1 7 3 4 6

12
Straight (LSD) Radix Sort
Varje bit sorteras på ett stabilt sätt. Då förändras inte den relativa ordningen mellan två nycklar med samma värde. Dvs algoritmen är stabil. Kräver extra minne O(n)
")
13
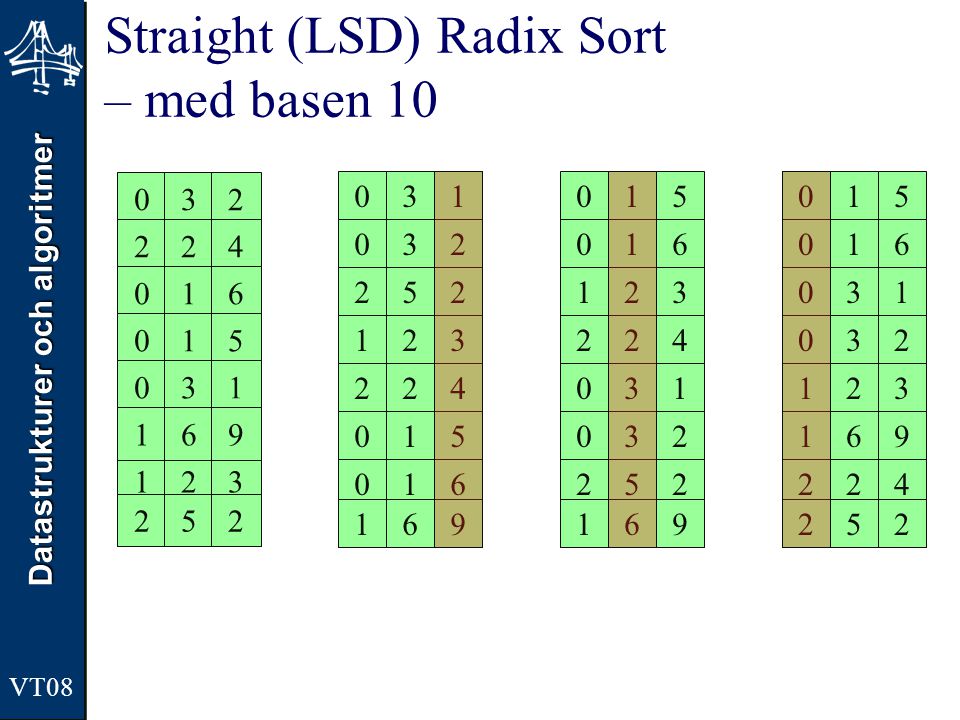
Straight (LSD) Radix Sort – med basen 10
3 2 4 1 6 5 9 3 1 2 5 6 4 9 1 2 5 3 6 4 9 1 3 2 6 5 4 9
14
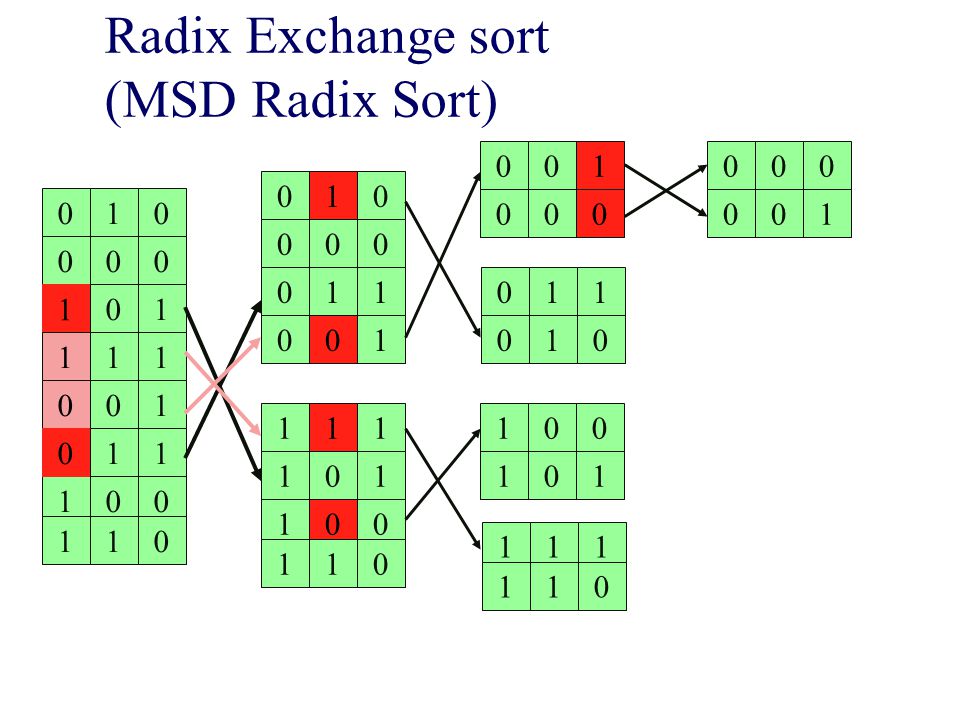
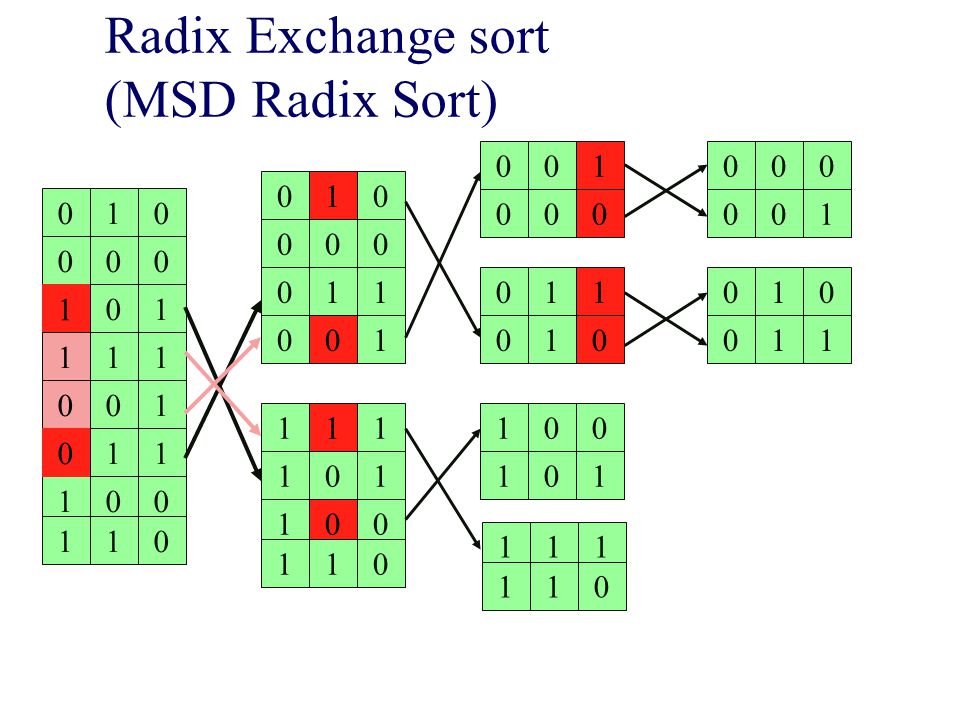
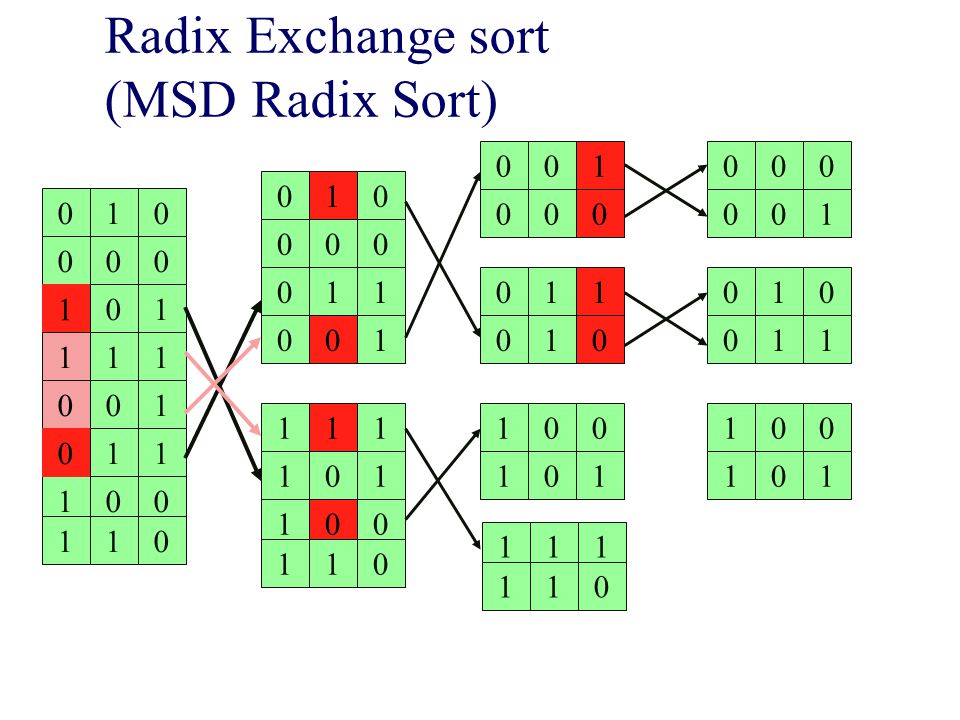
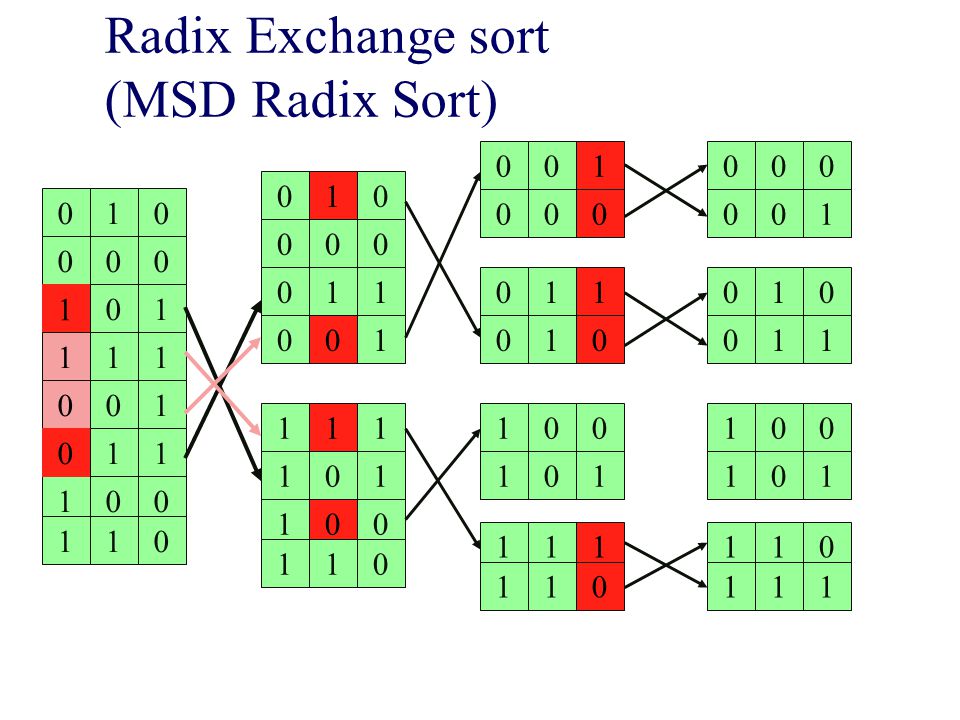
Radix Exchange sort (MSD Radix Sort)
Titta på bitarna från vänster till höger Sortera fältet på den vänstraste biten Dela fältet i två delar toppen & botten Rekursion Sortera toppen rekursivt, ignorera vänstraste biten Sortera botten rekursivt, ignorera vänstraste biten O(bN) där b är antalet bitar och N antalet tal MSD = Most Significant Digit
 där b är antalet bitar och N antalet tal. MSD = Most Significant Digit.")
15
Radix Exchange sort (MSD Radix Sort)
Toppen 1 1 Botten 1 1 1 1

16
Radix Exchange sort (MSD Radix Sort)
Bygger på samma idé som inplace quicksort, för att dela upp i två delar (toppen och botten) repeat scan top-down to find a key starting with 1; scan bottom-up to find a key starting with 0; exchange keys; until scan indices cross Likheter qsort och radixsort Båda delar upp arrayen Båda är rekursiva sorterar delar rekursivt Skillnader Radixsort baserar sin uppdelning i två arrayer större elle mindre än 2b-1 Qsort använder ett pivoelement Tidscomplexitet Rsort O(bN) Qsort O(Nlog(N)) Qsort O(N*N)
 repeat. scan top-down to find a key starting with 1; scan bottom-up to find a key starting with 0; exchange keys; until scan indices cross. Likheter qsort och radixsort. Båda delar upp arrayen. Båda är rekursiva sorterar delar rekursivt. Skillnader. Radixsort baserar sin uppdelning i två arrayer större elle mindre än 2b-1. Qsort använder ett pivoelement. Tidscomplexitet. Rsort O(bN) Qsort O(Nlog(N)) Qsort O(N*N)")
17
Radix Exchange sort (MSD Radix Sort)
1 1 1 1 1 1 1 1 1 1 1 1

18
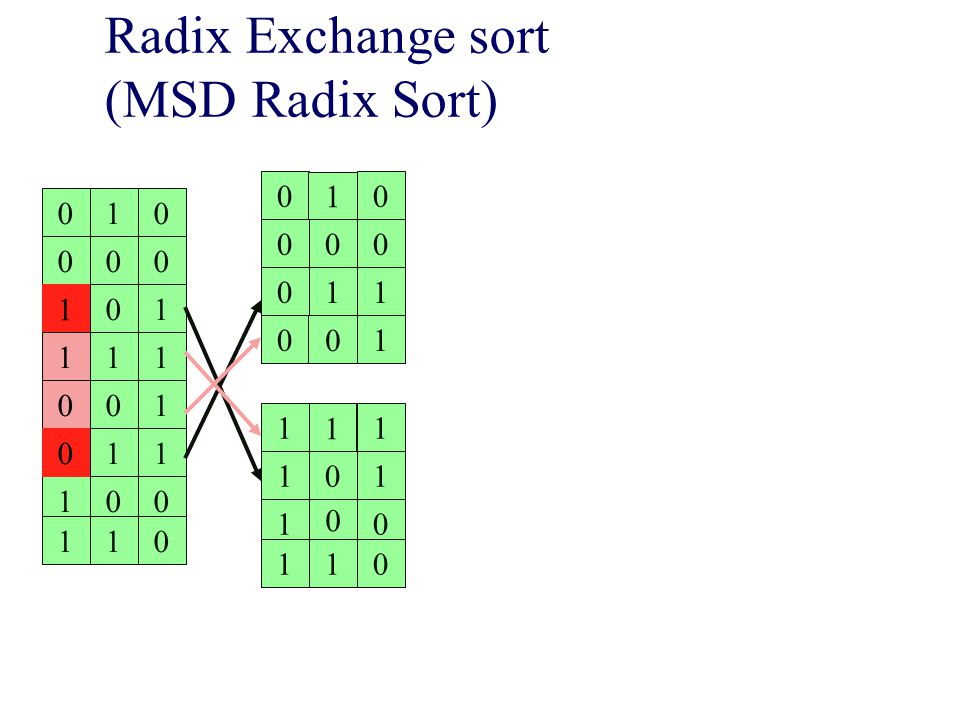
Radix Exchange sort (MSD Radix Sort)
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
19
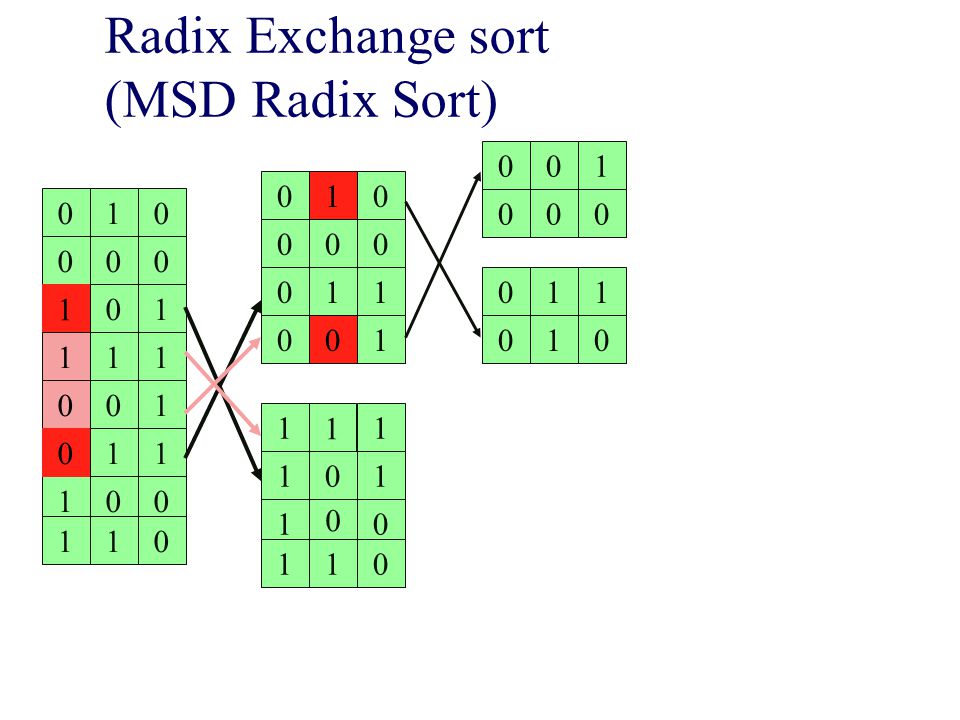
Radix Exchange sort (MSD Radix Sort)
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
20
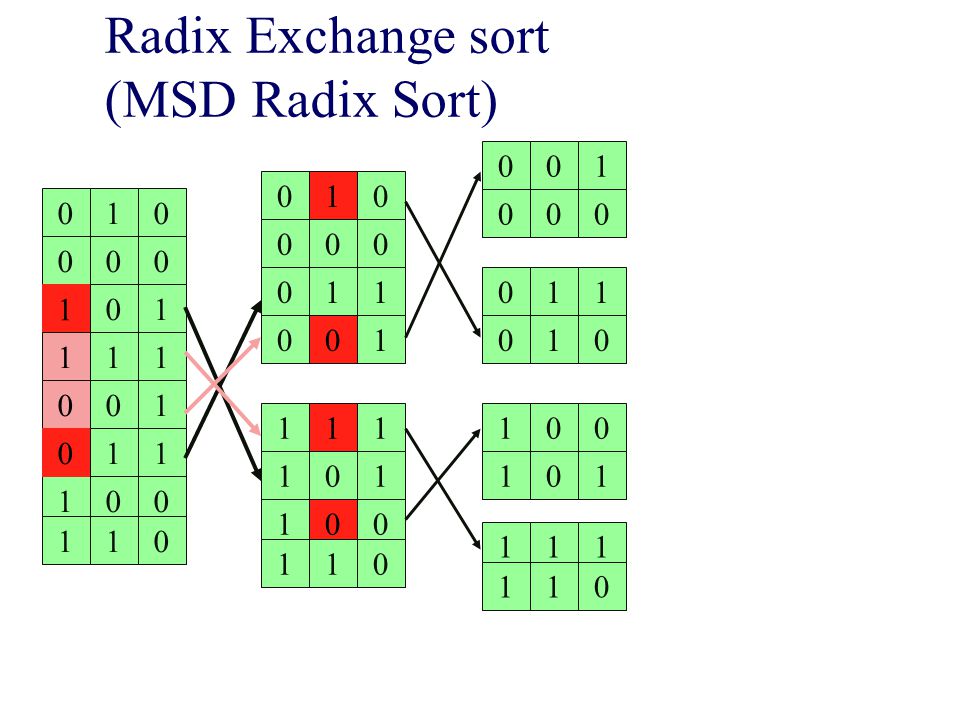
Radix Exchange sort (MSD Radix Sort)
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
21
Radix Exchange sort (MSD Radix Sort)
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
22
Radix Exchange sort (MSD Radix Sort)
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
23
Radix Exchange sort (MSD Radix Sort)
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
24
Radix Exchange sort (MSD Radix Sort)
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
25
Sammanfattande tabell baserad på tabellen på sidan http://en.wikipedia.org/wiki/Sorting_algorithm
Namn Bäst Medel Sämst Minne Stabil Typ Insertion sort O(n) O(n + d) O(n2) O(1) X Insättning Selection sort Urval Bubble sort — Utbyte Merge sort O(n log n) Samsortering In-place merge sort Quicksort O(log n) Heapsort Bucket sort (Pigeon hole sort) O(n+m) O(k) Nyckel LSD Radix sort O(n·k/s) MSD Radix sort O(n·(k/s)·2s) O((k/s)·2s)
 O(n + d) O(n2) O(1) X. Insättning. Selection sort. Urval. Bubble sort. — Utbyte. Merge sort. O(n log n) Samsortering. In-place merge sort. Quicksort. O(log n) Heapsort. Bucket sort (Pigeon hole sort) O(n+m) O(k) Nyckel. LSD Radix sort. O(n·k/s) MSD Radix sort. O(n·(k/s)·2s) O((k/s)·2s)")
26
Strängsökning… Att hitta en delsträng i en sträng Ett antal algoritmer
Naiv Knuth Morris Pratt Booyer Moore Rabin-Karp

27
Naiv Strängsökning Brute force Kan hitta första delsträngen eller alla
Jämför ett tecken i taget tills två olika eller hittad delsträng Vid två olika flytta fram ett tecken i huvudsträngen och börja om från början i mönstret Kan hitta första delsträngen eller alla

28
Exempel Jag vet inte vart min cykel finns vet

29
Tidskomplexitet – Bästa fallet
Om mönstret finns AAAAAAAAAAAAAAAA AAAAA O(M) där M är längden på mönstret Om mönstret inte finns OAAAA O(N) där N är längden på strängen
 där M är längden på mönstret. Om mönstret inte finns. OAAAA. O(N) där N är längden på strängen.")
30
Tidskomplexitet – Värsta fallet
Om mönstret finns AAAAAAAAAAAAAAAB AAAAB O(M*N) där M är längden på mönstret och N längden på strängen Om mönstret inte finns O(M*N)
 där M är längden på mönstret och N längden på strängen. Om mönstret inte finns. O(M*N)")
31
Vad kan vi göra bättre? Utnyttja kunskap om sökmönstret för att:
Undvika att behöva börja om från början i mönstret Hoppa längre steg

32
Knuth-Morris-Pratt Utnyttjar en felfunktion f som
berättar hur mycket av mycket av den senaste jämförelsen man kan återanvända om man felar är definierad som det längsta prefixet i P[0,...,j] som också är suffix av P[1,...,j] där P är vårt mönster. visar hur mycket av början av strängen matchar upp till omedelbart före felet Man ser alltså ifall det finns upprepningar i det mönster man söker och utnyttjar det.

33
Felfunktion exempel Om jämförelsen felar på position 4, så vet vi att a,b i position 2,3 är identiska med position 0,1 Kom i håg: f(j) är definierad som det längsta prefixet i P[0,...,j] som också är suffix av P[1,...,j] j 1 2 3 4 5 P[j] A B C f(j) Längsta prefixet av ABA som också är suffix av BA är A dvs längd 1 ABA Längsta prefixet av ABA som också är suffix av BA är A dvs längd 1 Längsta prefixet av ABAB som också är suffix av BAB är AB dvs längd 2 Längsta prefixet av ABABA som också är suffix av BABA är ABA dvs längd 3
 är definierad som det längsta prefixet i P[0,...,j] som också är suffix av P[1,...,j] j P[j] A. B. C. f(j) Längsta prefixet av ABA som också är suffix av BA är A dvs längd 1. ABA. Längsta prefixet av ABA som också är suffix av BA är A dvs längd 1. Längsta prefixet av ABAB som också är suffix av BAB är AB dvs längd 2. Längsta prefixet av ABABA som också är suffix av BABA är ABA dvs längd 3.")
34
KMP-algoritmen Input: String T (text) with n characters and P (pattern) with m characters. Output: Starting index of the first substring of T matching P, or an indication that P is not a substring of T. f := KMPfailureFunction(P) //Konstruera felfunktionen i := 0 j := 0 while i < n do if P[j] = T[i] then if j = m-1 then return i-m+1 // En matchning i := i+1 j := j+1 else if j > 0 then // ingen match, vi har gått j index direkt efter // matchande prefix i P j := f(j-1) else return ingen matchning av delsträngen P i S
 //Konstruera felfunktionen. i := 0. j := 0. while i < n do. if P[j] = T[i] then. if j = m-1 then. return i-m+1 // En matchning. i := i+1. j := j+1. else if j > 0 then. // ingen match, vi har gått j index direkt efter. // matchande prefix i P. j := f(j-1) else. return ingen matchning av delsträngen P i S.")
35
KMPfailureFunction(P)
j := 0 while i <= m-1 do if P[j] = P[i] then // We have matched j+1 characters f(i) := j+1 i := i+1 j := j+1 else if j > 0 then //j index efter pref som match. j := f(j-1) else //ingen matchning f(i) := 0
 := j+1. i := i+1. j := j+1. else if j > 0 then. //j index efter pref som match. j := f(j-1) else //ingen matchning. f(i) := 0.")
36
KMP exempel i a b a c a a b a c c a b a c a b a a a a a a a b c j a b
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 a b a c a a b a c c a b a c a b a a a a a a i = 5, j = 5 j = f(j-1) = f(4) = 1 a b c i = 5, j = 1 j = f(j-1) = f(0) = 0 j a b c a b c i = 9, j = 0 i = 10 i = 9, j = 4 j = f(j-1) = f(3) = 0 a b c a b c i = 15, j = 5, returnera i-m+1 = = 10 j 1 2 3 4 5 P[j] a b c f(j) Totalt 19 tecken jämförelser
 = f(4) = 1. a. b. c i = 5, j = 1 j = f(j-1) = f(0) = 0. j. a. b. c. a. b. c. i = 9, j = 0 i = 10. i = 9, j = 4 j = f(j-1) = f(3) = 0. a. b. c. a. b. c. i = 15, j = 5, returnera i-m+1 = = 10. j P[j] a. b. c. f(j) Totalt 19 tecken jämförelser.")
37
KMP-Algoritmen Låt k = i - j
För varje varv i while-loopen händer ett av följande: T[i] = P[j], öka i och j med 1, k oförändrad. T[i] < > P[j] och j > 0, i är oförändrad men k ökar med minst 1 eftersom den ändras från i - j to i - f(j-1) T[i] < > P[j] och j = 0, öka i med 1 och minska k med 1 (ty j oförändrad). Alltså för varje varv i loopen ökar antingen i eller k med minst 1. Max antal varv blir 2n Detta antar att f redan är beräknad (som är O(m)). Total komplexitet: O(n + m)
 T[i] < > P[j] och j = 0, öka i med 1 och minska k med 1 (ty j oförändrad). Alltså för varje varv i loopen ökar antingen i eller k med minst 1. Max antal varv blir 2n. Detta antar att f redan är beräknad (som är O(m)). Total komplexitet: O(n + m)")
38
Boyer-Moores algoritm
Liknar KMP Idéer: Gör matchningen baklänges, med start i mönstrets sista element. Om man stöter på ett tecken i strängen som inte finns i mönstret så flytta hela mönstret förbi detta tecken. Flytta fram mönstret så långt som möjligt varje gång. Om det finns upprepningar av element i mönstret så får man bara flytta fram till den högraste förekomsten. Förskjutningstabell talar om hur långt man får flytta.

39
Boyer-Moore algoritmen
Input: String T (text) with n characters and P (pattern) with m characters. Output: Starting index of the first substring of T matching P, or an indication that P is not a substring of T. i := m - 1 j := m - 1 repeat if P[j] = T[i] then if j = 0 then return i /* A match */ else i := i - 1 j := j - 1 i := i + m - j - 1 i := i + max{j - last(T[i]), match(i)} j := m -1 until i > n -1 return indication of no substring found
 with n characters and P (pattern) with m characters. Output: Starting index of the first substring of T matching P, or an indication that P is not a substring of T. i := m - 1. j := m - 1. repeat. if P[j] = T[i] then. if j = 0 then. return i /* A match */ else. i := i - 1. j := j - 1. i := i + m - j - 1. i := i + max{j - last(T[i]), match(i)} j := m -1. until i > n -1. return indication of no substring found.")
40
Två hjälpmedel i algoritmen
Last(ch) – ger sista förekomsten av ch i mönstret P om ch finns i P och -1 annars Match(j) – en förskjutningstabell som utifrån tre fall beräknar hur långt fram du kan flytta mönstret som mest. Algoritmens styrka är att den kan hoppa över stora delar text Fungerar mindre bra om Texten består av få bokstäver (tex enbart 0, 1) Mönstret är väldigt kort
 – ger sista förekomsten av ch i mönstret P om ch finns i P och -1 annars. Match(j) – en förskjutningstabell som utifrån tre fall beräknar hur långt fram du kan flytta mönstret som mest. Algoritmens styrka är att den kan hoppa över stora delar text. Fungerar mindre bra om. Texten består av få bokstäver (tex enbart 0, 1) Mönstret är väldigt kort.")
41
Boyer-Moore exempel a b a c a a b a c c a b a c a b a a a a a a a b c
a b c Totalt 15 tecken jämförelser a b c a b c a b c j 1 2 3 4 5 P[j] a b c match(j) 6 ch a b c ? last(ch) 4 5 3 -1
 6. ch. a. b. c. last(ch)")
42
Rabin-Karp Beräkna ett hashvärde för mönstret och för varje delsträng av texten som man ska jämföra med Om hashvärdena är skilda, beräkna hashvärdet för det nästa M tecknen i texten Om hashvärdena är lika, utför en brute-force jämförelse mellan P och delsträngen Med andra ord: Endast en jämförelse per deltext Brute-force endast när hash-värderna matchar.

43
Rabin-Karp exempel Hashvärdet för AAAAA = 37
Hashvärdet för AAAAH = 100 AAAAAAAAAAAAAAHA AAAAH 100 <> 37 100 = 100 1 jämförelse 1 + 5 jämförelser

44
Rabin-Karp hashfunktionen
Får inte kosta för mycket.... Betrakta M som ett M-siffrigt tal i basen b, där b är antalet bokstäver i alfabetet Textsekvensen t[i..i+M-1] avbildas på talet x(i) = t[i]bM-1+ t[i+1]bM t[i+M-1] Billigt att beräkna x(i+1) från x(i) x(i+1) = t[i+1]bM-1+ t[i+2]bM t[i+M] x(i+1) = x(i)b skifta ett vänster, - t[i]bM ta bort den vänstraste termen + t[i+M] lägg till den nya högertermen Behöver inte räkna om hela talet utan gör bara en justering för det nya tecknet
 = t[i]bM-1+ t[i+1]bM t[i+M-1] Billigt att beräkna x(i+1) från x(i) x(i+1) = t[i+1]bM-1+ t[i+2]bM t[i+M] x(i+1) = x(i)b skifta ett vänster, - t[i]bM ta bort den vänstraste termen + t[i+M] lägg till den nya högertermen. Behöver inte räkna om hela talet utan gör bara en justering för det nya tecknet.")
45
Hash-värdet fortsättning
Om M är stort blir blir (b*M) enormt därför så hashar man med mod ett stort primtal h(i) = ((t[i]bM-1mod q) + (t[i+1]bM-2mod q)+...+ (t[i+M-1] mod q)) mod q h(i+1) = (h(i)b mod q - (t[i]bMmod q) + (t[i+M] mod q) mod q
 enormt därför så hashar man med mod ett stort primtal. h(i) = ((t[i]bM-1mod q) + (t[i+1]bM-2mod q)+...+ (t[i+M-1] mod q)) mod q. h(i+1) = (h(i)b mod q - (t[i]bMmod q) + (t[i+M] mod q) mod q.")
46
Algoritm hash_M <- Beräkna hashvärdet för M
hash_S <- Beräkna hashvärdet för den första delsträngen do if (hash_M = hash_S) then Bruteforce jämförelse av M och S hash_S + 1 tecken beräknas while end of text or match
 then. Bruteforce jämförelse av M och S. hash_S + 1 tecken beräknas. while end of text or match.")
47
Komplexitet Om det är tillräckligt stort primtal q för hashfunktionen så kommer hashvärdet från två mönster vara distinkta I detta fall så tar sökningen O(N) där N är antalet tecken i strängen Men det finns alltid fall som ger i närheten av värsta fallet O(N*M) om primtalet är för litet
 där N är antalet tecken i strängen. Men det finns alltid fall som ger i närheten av värsta fallet O(N*M) om primtalet är för litet.")
Liknande presentationer




![void hittaMax(int tal[], int antal, int *pmax) { int i; ??=tal[0]; for(i=1;i??) ??=tal[i]; } int main() { int v[]={1,2,3,4,2}; int.](/7/1967128/big_thumb.jpg "void hittaMax(int tal[], int antal, int *pmax) { int i; ??=tal[0]; for(i=1;i??) ??=tal[i]; } int main() { int v[]={1,2,3,4,2}; int.>")








>")

 och ordo>")



