Ladda ner presentationen
Presentation laddar. Vänta.

1
Epidemiologi och Biostatistik
Karin Leander Institutet för Miljömedicin (IMM) Enheten för Kardiovaskulär Epidemiologi Karolinska Institutet HT 2014
 Enheten för Kardiovaskulär Epidemiologi. Karolinska Institutet. HT")
2
Vad är Epidemiologi? Vad är Biostatistik? Beskrivning av
förekomst av sjukdomar och studier av orsaker till sjukdomar i en befolkning. Vad är Biostatistik? Vetenskapen som handlar om att samla in och analysera medicinska data under användande av statistiska metoder. Hur ofta förekommer sjukdomar i en befolkning och varför. Epidemeiologiska fynd används för att förebygga, kontrollera eller planera preventions åtgärder för olika sjukdomar.

3
Varför är Epidemiologi och Biostatistik viktigt ?
Bra läkare måste hålla sig uppdaterade. Uppdatering sker via vetenskapsartiklar. Vad ska man lita på? (vilka är bra / dåliga vetenskapsartiklar....för de dåliga finns!). Vill du forska? Vad du än forskar i - förr eller senare måste du planera eller designa dina studier! Bra forskning kräver en bra grund.
. Vill du forska Vad du än forskar i - förr eller senare måste du planera eller designa dina studier! Bra forskning kräver en bra grund.")
4
Syftet med VetU att inspirera och motivera till vetenskaplig nyfikenhet och förhållningssätt att ge grundläggande vetenskapliga kunskaper och färdigheter som en modern läkare har behov av i sin dagliga verksamhet att förbereda för ett fruktbart livslångt lärande som behövs för ett framgångsrikt yrkesliv Syfte svarar på varför...mykcet bredare Målet med denna VetU-del: Att kunna granska vetenskapliga artiklar ur en epidemiologisk och biostatistisk synvinkel: vilken design har använts, vilken analysmetod, vilka felkällor och vilka är dess konsekvenser.

5
Tre mått för beskrivning av förekomst av sjukdomar i en befolkning
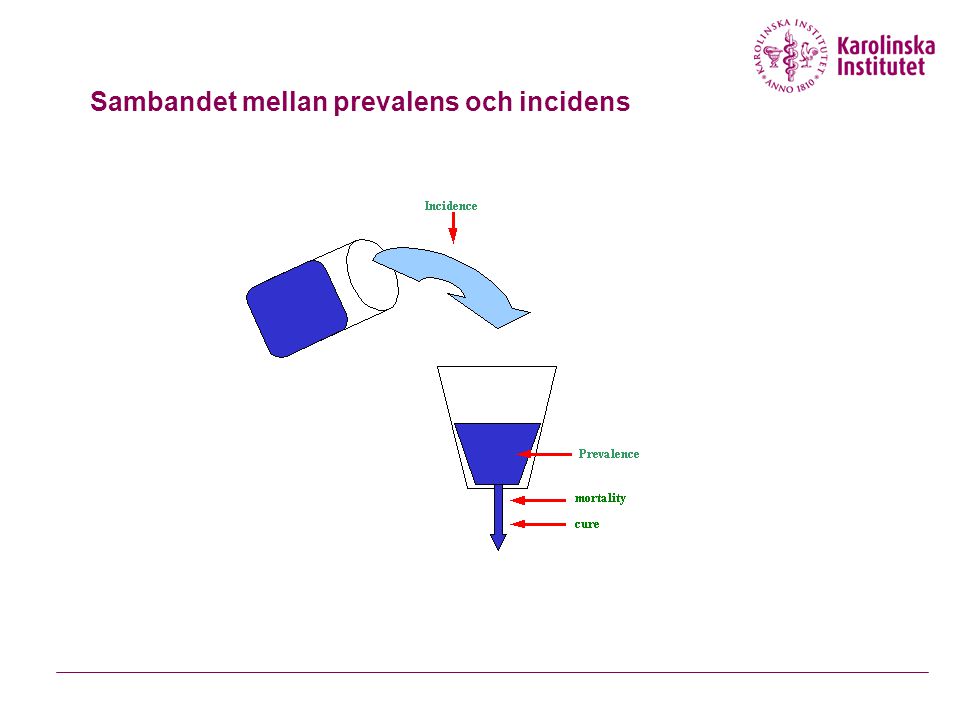
Prevalens: Andel individer i en population som har sjukdomen i fråga vid en specifik tidpunkt. (0-1) Enhet: % Incidens: Frekvens av nya fall i sjukdomen (0-∞) Enhet: tid-1 Kumulativ Incidens: (0-1) Andel individer i en population som följs över en given tidsperiod, och som var fria från sjukdomen i fråga vid uppföljningens start, som utvecklar sjukdomen under den givna tidsperioden (0-1) Enhet: %
 Enhet: % Incidens: Frekvens av nya fall i sjukdomen (0-∞) Enhet: tid-1. Kumulativ Incidens: (0-1) Andel individer i en population som följs över en given tidsperiod, och som var fria från sjukdomen i fråga vid uppföljningens start, som utvecklar sjukdomen under den givna tidsperioden. (0-1) Enhet: %")
6
Sambandet mellan prevalens och incidens
7
Studiedesign och dess inverkan på konklusion av studien
Cohort (prospektiv, retrospektiv) Case-control RCT (Randomised Clinical Trial) Case-control You select cases (tex all breast cancer cases in Sweden) and you select controls from the population. Can you select only breast cancer in Stockholm county? What are the implications? Selection bias? Matched controls is one way of avoiding bias or conclusions from the results Cohort Rekrutering är baserad på exponering och under tiden observerar du vilka som har fått sjukdomen man studerar. You decide to follow a cohort of women born between 1950 and 1970 upp untill today (retrospective). You decide to contact all children born between 1 januari december 2010 and study occurrence and risk factors of child leukemia (propsective). Clinical TRials Du har en grupp av finniga tonåringar som söker sig till hudkliniken på KS för hjälp. Det finns en standard salva som oftast skrivs ut och så finns nya medlet. Och så finns placebo. För att se dess effekt så randomiserar man ut tonåringarna till antingen standard, nya medlet eller placebo.
 Case-control. RCT (Randomised Clinical Trial) Case-control. You select cases (tex all breast cancer cases in Sweden) and you select controls from the population. Can you select only breast cancer in Stockholm county What are the implications Selection bias Matched controls is one way of avoiding bias or conclusions from the results. Cohort. Rekrutering är baserad på exponering och under tiden observerar du vilka som har fått sjukdomen man studerar. You decide to follow a cohort of women born between 1950 and 1970 upp untill today (retrospective). You decide to contact all children born between 1 januari december 2010 and study occurrence and risk factors of child leukemia (propsective). Clinical TRials. Du har en grupp av finniga tonåringar som söker sig till hudkliniken på KS för hjälp. Det finns en standard salva som oftast skrivs ut och så finns nya medlet. Och så finns placebo. För att se dess effekt så randomiserar man ut tonåringarna till antingen standard, nya medlet eller placebo.")
8
Felkällor Felkällor (bias) i epidemiologiska studier är systematiska fel som resulterar I inkorrekta estimat av associationen mellan exponering och utfall. Felkällor: 1. Selektion bias 2. Observation/information (felklassificering / misclassification) bias recall reporting measurement withdrawal Beroende och oberoende felklassificering (differential/ non-differential)
 i epidemiologiska studier är systematiska fel som resulterar I inkorrekta estimat av associationen mellan exponering och utfall. Felkällor: 1. Selektion bias. 2. Observation/information (felklassificering / misclassification) bias. recall. reporting. measurement. withdrawal. Beroende och oberoende felklassificering (differential/ non-differential)")
9
Confounding Conf Exp Utfall Exp Med Utfall
Definition: En faktor som ”stör” det studerade sambandet. Ska vara associerad både med Exponeringen i fråga Utfallet i fråga Får dessutom inte vara en mediär faktor Kontroll för confounding utförs via - Restriktion vid valet av studiepopulation - Stratifierad analys - Multivariat modell Conf Exp Utfall Exp Med Utfall

10
Studiedesign och dess inverkan på konklusion av studien : COHORT
Prospektiv vs Retrospektiv Felkällor: Hur väl studien är utförd (t ex komplett och exakt exponeringsinformation från alla studiedeltagare) Styrkan och riktningen av associationen kan påverkas Ex: Om exponering är en terapi som ska administreras ...(indikation bias) Lost to follow-up Prospektiv: Man samlar data framåt i tiden. Detta gör ju att ma kan inte selektera individer för att de har en speciell exponering då man inte känner till vilka som kommer att få sjukdomen. Retrospektiv: alla events har hänt förr i tiden, tex då man har definierat tid för exponeringen. Viktigt att man fångar alla som ingår i definitionen av populationen i fråga. Slumpmässig val av alla individer innebär också att man närmar sig den riktiga sambandet så nära som möjligt. Det gäller att samla in data så bra som möjligt för om vi har ascertainment bias så har det konsekvenser för associationerna i fråga (Större problem för retrospektiva då både exponering och utfall har inträffat....därför bra med register studier) Om det finns skillnader i censoring eller lost to follow up mellan exponerade och oexponerade so har det konsekvenser för validiteten i studien Om exponering är en terapi som ska administreras och valet av exponerade bestäms utav sjukdomen (indications bias) så ändras associationen mellan exponering och sjukdom.
 Styrkan och riktningen av associationen kan påverkas. Ex: Om exponering är en terapi som ska administreras ...(indikation bias) Lost to follow-up. Prospektiv: Man samlar data framåt i tiden. Detta gör ju att ma kan inte selektera individer för att de har en speciell exponering då man inte känner till vilka som kommer att få sjukdomen. Retrospektiv: alla events har hänt förr i tiden, tex då man har definierat tid för exponeringen. Viktigt att man fångar alla som ingår i definitionen av populationen i fråga. Slumpmässig val av alla individer innebär också att man närmar sig den riktiga sambandet så nära som möjligt. Det gäller att samla in data så bra som möjligt för om vi har ascertainment bias så har det konsekvenser för associationerna i fråga (Större problem för retrospektiva då både exponering och utfall har inträffat....därför bra med register studier) Om det finns skillnader i censoring eller lost to follow up mellan exponerade och oexponerade so har det konsekvenser för validiteten i studien. Om exponering är en terapi som ska administreras och valet av exponerade bestäms utav sjukdomen (indications bias) så ändras associationen mellan exponering och sjukdom.")
11
Studiedesign och dess inverkan på konklusion av studien : CASE-CONTROL
Kostnads-effektiv för sällsynta sjukdomar eller sjukdomar med långa latenta perioder. Definition och selektion av fallen viktigt. - Viktigt att skilja mellan prevalenta och incidenta (nya) fall. Val av kontroller lika viktigt. Dessa ska spegla exponeringens förekomst i den population som studeras. Idén är ju att jämföra exponeringsfrekvensen hos fall med den hos kontroller. Information angående exponeringar ska samlas in på samma sätt för både fall och kontroller. Definitionen måste vara så precis som möjligt, för olika grupper inom samma sjukdomar kan innebär att validiteten drabbas både interna och externa. Alla fall borde också ha samma sannolikheten att bli valda in i studien. En viss grupp tex med mildare symptom som väljs oftare än gruppen med svårare sjuka kan ha konsekvenser för konklusionerna som dras utav denna studie. Man ska också vara försiktig med vilka fall man inkluderar tex incidenta eller prevalenta. Oftast är prevalenta fall inkluderade för de är lättast att identifiera. MEN de är oxå biased för det är populationen av fall som har överlevt fram tillas att studien började och vid kliniska studier så är det viktigt att ha det i åtanken. Tex ska man studera stroke patienter nu vid denna tidpunkt (prevalenta fall) så ska man tänka på att vissa kanske redan har dött innan och de vi har nu är selekterade för att ha överlevt sin stroke. Kontroller är inte definierade som personer som inte har sjukdomen ifråga. De ska representera generella populationen från vilken sjukdomen kan uppstå. Man kan också oftast matcha kontroller för vissa faktorer...MEN matchar man för tex ålder som kan vara en risk faktor så kan du inte estimera effekten av ålder då man har matchat för det! We match to ensure that controls and cases are similar in variables which may be related to the variable we are studying but are not of interest in themselves. Helst ska man samla in data likvärdigt för både kkontroller och fall och inte vara mer försiktig med fallen (tex rökvanor fråga mer fallen än kontrollerna ). Man kan ha en viss error i samling som kallas för random missclassification hos både fall och kontroller. Det adderar bara ”noise” hos båda och påverkar då inte chansen att hitta en skillnad mellan grupperna. Non-random missclasification kan leda till falska associationer.
 fall. Val av kontroller lika viktigt. Dessa ska spegla exponeringens förekomst i den population som studeras. Idén är ju att jämföra exponeringsfrekvensen hos fall med den hos kontroller. Information angående exponeringar ska samlas in på samma sätt för både fall och kontroller. Definitionen måste vara så precis som möjligt, för olika grupper inom samma sjukdomar kan innebär att validiteten drabbas både interna och externa. Alla fall borde också ha samma sannolikheten att bli valda in i studien. En viss grupp tex med mildare symptom som väljs oftare än gruppen med svårare sjuka kan ha konsekvenser för konklusionerna som dras utav denna studie. Man ska också vara försiktig med vilka fall man inkluderar tex incidenta eller prevalenta. Oftast är prevalenta fall inkluderade för de är lättast att identifiera. MEN de är oxå biased för det är populationen av fall som har överlevt fram tillas att studien började och vid kliniska studier så är det viktigt att ha det i åtanken. Tex ska man studera stroke patienter nu vid denna tidpunkt (prevalenta fall) så ska man tänka på att vissa kanske redan har dött innan och de vi har nu är selekterade för att ha överlevt sin stroke. Kontroller är inte definierade som personer som inte har sjukdomen ifråga. De ska representera generella populationen från vilken sjukdomen kan uppstå. Man kan också oftast matcha kontroller för vissa faktorer...MEN matchar man för tex ålder som kan vara en risk faktor så kan du inte estimera effekten av ålder då man har matchat för det! We match to ensure that controls and cases are similar in variables which may be related to the variable we are studying but are not of interest in themselves. Helst ska man samla in data likvärdigt för både kkontroller och fall och inte vara mer försiktig med fallen (tex rökvanor fråga mer fallen än kontrollerna ). Man kan ha en viss error i samling som kallas för random missclassification hos både fall och kontroller. Det adderar bara noise hos båda och påverkar då inte chansen att hitta en skillnad mellan grupperna. Non-random missclasification kan leda till falska associationer.")
12
Studiedesign och dess inverkan på konklusion av studien : CLINICAL TRIALS
Orsak- och verkan-samband. Randomisering. Volontärer! Hawthorne-effekten. Intention to treat. Med fall kontroll och kohort studier så kan man bara prata om associationer eller samband. Kliniska försök däremot kan etablera cause-effet samband. Randomisering är A och O. Det garnaterar att exponeringar och andra risk faktorer är så lika fördelade i varje grupp, så att man ”isolerar” effekten av terapin man vill testa. Så om man ser en effekt eller association så är den en cause-effect relation. MEN Vissa problem finns även här. Tex om man bara inkluderar volontärer gör ju att man har en viss selektion. Eller tex att de som går med på att vara med i studien kanske skiljer sig i ålder kön och SES som kan ha en effekt på sjukdom. Dessa faktorer borde då beaktas. Hawthorne effekten: Individer som är med i studier har bättre utfall eller lägre morbiditet och mortalitet än sådana som inte är med i trials. Som i alla studier är det viktigt med beräkning av power och sample size innan man börjar en studie. Sist In epidemiology, an intention to treat (ITT) analysis is an analysis based on the initial treatment intent, not on the treatment eventually administered. It is based on the assumption that, as in real life, sometimes patients do not all receive optimal treatment, even though that was the initial intention. For the purposes of analysis, the reasons why the patient did not receive the treatment are ignored. Intention to treat analyses are done to avoid the effects of crossover and drop-out, which may break the randomization to the treatment groups in a study. Intention to treat analysis provides information about the potential effects of treatment policy rather than on the potential effects of specific treatment. In contrast, efficacy subset analysis selects the subset of the patients who received the treatment of interest--regardless of initial randomization--and who have not dropped out for any reason. This approach can : introduce biases to the statistical analysis inflate the type I error; this effect is greater the larger the trial[1]. Full application of intention to treat can only be performed where there is complete outcome data for all randomised subjects. Although intention to treat is widely cited in published trials, it is often incorrectly described and its application may be flawed.
 analysis is an analysis based on the initial treatment intent, not on the treatment eventually administered. It is based on the assumption that, as in real life, sometimes patients do not all receive optimal treatment, even though that was the initial intention. For the purposes of analysis, the reasons why the patient did not receive the treatment are ignored. Intention to treat analyses are done to avoid the effects of crossover and drop-out, which may break the randomization to the treatment groups in a study. Intention to treat analysis provides information about the potential effects of treatment policy rather than on the potential effects of specific treatment. In contrast, efficacy subset analysis selects the subset of the patients who received the treatment of interest--regardless of initial randomization--and who have not dropped out for any reason. This approach can : introduce biases to the statistical analysis. inflate the type I error; this effect is greater the larger the trial[1]. Full application of intention to treat can only be performed where there is complete outcome data for all randomised subjects. Although intention to treat is widely cited in published trials, it is often incorrectly described and its application may be flawed.")
13
Nyckelbegrepp inom biostatistik
Incidens, Prevalens - dessa mått beror av varandra Relativ risk, Oddskvot, Hazard risk. Univariat vs multivariat analys. Linjär och logistisk regression, överlevnadsanalys (Cox proportional hazards). Power, significance (5%), p-value, confidence interval (95%). Incidens: är kvoten mellan antal nya fall som inträffar under en period genom antalet individer i populationen i början av tids perioden. Prevalens: är kvoten av antalet individer som har sjukdomen vid en given tidpunkt delat med totala antalet individer i populationen under risk vid samma tidpunkt. Det är mycket enklare (kostar mindre) att studera en population med stor pervalens än att följa en population över tid för att samla in incidenta fall. MEN man seleketerar då och samla in information för de risk faktorer givet att de har överlevt så länge. Så man kan inte generalisera på en incident population. Medans incidens och prevalens är ”rater” så får man från biostatistiken verktyg för att jämföra rater. 2 sådana kända mått är relativa risker och odsskvoter. Relativa risken är kvoten mellan incidensen eller prevalensen i en grupp som är exponerade delad med incidensen eller prevalensen i en grupp som inte är exponerade. Man pratar om relativa risker då man studerar populationer dvs cohort eller interventions studier. Odd kvoter används då man har en case-control design. Anldenigen är för att man väljer ett antal kontroller ur populationen istället för hela populationen, så egentligen är våra rates inte representativa. Så vad vi gör istället är att vi tittar på oddsen att bli exponerad i en grupp gentemot oddsen att inte var exponerad i en annan grupp. Vill man ha med tid i analyserna så använder man sig oftast av Hazard risk. Tex är det så att en viss terapi gör att vi har en fördröjning av sjukdomen? Detta är en överlevnadsanalys, tid till att vi får en händelse mellan grupper är hazard risken. Så man jämför frekvensen av en viss sjudkom eller event över en viss tid. Så på sätt och viss så beräknar man spontana RR av en event per enhet tid över en specifik tidsperiod. Univariat analys indikerar att man analyserar en variabel och ett utfall. Men det är väldigt viktigt att ha med cobfounding variabler som påverkar sambandet. Om de är inkluderade i en analys så pratar man då om multivariat analys. Man kontrollerar då så man säger för dessa confounding effekter och på så sätt ”isolerar” man oberoende effekten av var och en på asosociationen som ma egentligen är intresserad av. VIKTIGT, har du inte fått med alla confounding faktorer så är assocationen så bra som den kan vara givet de variabler vi har kontrollerat för. Typer av analys: Man väljer typ av analys beroende på vad man har för utfall. Har man ett kontinuerligt utfall så använder ma sig oftast av linjäör regression. Tex risk faktorer och dess samband med fetma mätt som BMI kontinuerlig skala. Om utfallet är dichotomt (dvs ja/nej) så använder man sig av logistisk regression. Tex man undersöker om en viss terapi leder till sjukdom bland patienter. Oddskvoter fårs fram oftast med hjälp av logistisk regression. Cox proportional hazards är en utav metoderna för att undersöka om en grupp patienter tex får en viss sjukdom under en viss tidsperiod. Denna metod jämför egentligen lutningarna mellan 2 överlevnads kurvor istället för proportioner som man gör i logistiks regression. Power: är måttet som talar om vad sannolikheten är att hitta en skillnad när en sådan existerar i verkligheten. Den beror på storleken av studien, magnituden av effekten man vill studera, frekvensen av sjukdomen i populationen, och längden av observations perioden. Signifikans används som ett mått när man undersöker skillnader mellan två mått eller rater. En skillnad kan antingen uppstå av en slump eller för att den verkligen finns där. P-värdet är just sannolikheten att skillnaden vi har hittat beror på slumpen. Man brukar säga att signifkansen är på 5% vilket innebär att om vi hittar en skillnad så accepterar vi att till 5% beror den på slumpen. Man brukar också prata om Type 1 fel (error) dvs att man hittar en skillnad när en sådan gentligen inte finns. Ett typ 2 fel är alltså att man inte hittar en skillnad när en sådan faktist finns (tex att man har för få individer, dvs low power och hittar då ingen effekt pga det).
. Power, significance (5%), p-value, confidence interval (95%). Incidens: är kvoten mellan antal nya fall som inträffar under en period genom antalet individer i populationen i början av tids perioden. Prevalens: är kvoten av antalet individer som har sjukdomen vid en given tidpunkt delat med totala antalet individer i populationen under risk vid samma tidpunkt. Det är mycket enklare (kostar mindre) att studera en population med stor pervalens än att följa en population över tid för att samla in incidenta fall. MEN man seleketerar då och samla in information för de risk faktorer givet att de har överlevt så länge. Så man kan inte generalisera på en incident population. Medans incidens och prevalens är rater så får man från biostatistiken verktyg för att jämföra rater. 2 sådana kända mått är relativa risker och odsskvoter. Relativa risken är kvoten mellan incidensen eller prevalensen i en grupp som är exponerade delad med incidensen eller prevalensen i en grupp som inte är exponerade. Man pratar om relativa risker då man studerar populationer dvs cohort eller interventions studier. Odd kvoter används då man har en case-control design. Anldenigen är för att man väljer ett antal kontroller ur populationen istället för hela populationen, så egentligen är våra rates inte representativa. Så vad vi gör istället är att vi tittar på oddsen att bli exponerad i en grupp gentemot oddsen att inte var exponerad i en annan grupp. Vill man ha med tid i analyserna så använder man sig oftast av Hazard risk. Tex är det så att en viss terapi gör att vi har en fördröjning av sjukdomen Detta är en överlevnadsanalys, tid till att vi får en händelse mellan grupper är hazard risken. Så man jämför frekvensen av en viss sjudkom eller event över en viss tid. Så på sätt och viss så beräknar man spontana RR av en event per enhet tid över en specifik tidsperiod. Univariat analys indikerar att man analyserar en variabel och ett utfall. Men det är väldigt viktigt att ha med cobfounding variabler som påverkar sambandet. Om de är inkluderade i en analys så pratar man då om multivariat analys. Man kontrollerar då så man säger för dessa confounding effekter och på så sätt isolerar man oberoende effekten av var och en på asosociationen som ma egentligen är intresserad av. VIKTIGT, har du inte fått med alla confounding faktorer så är assocationen så bra som den kan vara givet de variabler vi har kontrollerat för. Typer av analys: Man väljer typ av analys beroende på vad man har för utfall. Har man ett kontinuerligt utfall så använder ma sig oftast av linjäör regression. Tex risk faktorer och dess samband med fetma mätt som BMI kontinuerlig skala. Om utfallet är dichotomt (dvs ja/nej) så använder man sig av logistisk regression. Tex man undersöker om en viss terapi leder till sjukdom bland patienter. Oddskvoter fårs fram oftast med hjälp av logistisk regression. Cox proportional hazards är en utav metoderna för att undersöka om en grupp patienter tex får en viss sjukdom under en viss tidsperiod. Denna metod jämför egentligen lutningarna mellan 2 överlevnads kurvor istället för proportioner som man gör i logistiks regression. Power: är måttet som talar om vad sannolikheten är att hitta en skillnad när en sådan existerar i verkligheten. Den beror på storleken av studien, magnituden av effekten man vill studera, frekvensen av sjukdomen i populationen, och längden av observations perioden. Signifikans används som ett mått när man undersöker skillnader mellan två mått eller rater. En skillnad kan antingen uppstå av en slump eller för att den verkligen finns där. P-värdet är just sannolikheten att skillnaden vi har hittat beror på slumpen. Man brukar säga att signifkansen är på 5% vilket innebär att om vi hittar en skillnad så accepterar vi att till 5% beror den på slumpen. Man brukar också prata om Type 1 fel (error) dvs att man hittar en skillnad när en sådan gentligen inte finns. Ett typ 2 fel är alltså att man inte hittar en skillnad när en sådan faktist finns (tex att man har för få individer, dvs low power och hittar då ingen effekt pga det).")
14
Sammanfattning Tre olika mått på sjukdomsförekomst:
Prevalens, incidens och kumulativ incidens Vanliga studiedesigntyper: Cohort och Fall-kontroll (observationsstudier) Randomiserade clinical trials (experimentell design) Ingen studiedesign är fri från felkällor. Vanliga biostatistiska mått på effekt inkluderar: Relativ risk Oddskvot Hazard ratio
 Randomiserade clinical trials (experimentell design) Ingen studiedesign är fri från felkällor. Vanliga biostatistiska mått på effekt inkluderar: Relativ risk. Oddskvot. Hazard ratio.")
15
Tips vid presentation/tolkning av resultat
Alla observerade samband är inte kausala… Var försiktig med formuleringar som ”x orsakar y” Beakta alla tänkbara felkällor. Påvisade dos-respons-samband i studiematerialet kan ge visst stöd till hypoteser om orsakssamband. Biologiska tidigare kända mekanismer kan stödja påvisade samband.

16
Presentationer av artikelgranskningar 13/1
Fysisk aktivitet och risk för förmaksflimmer Galectin 3 och risk för förmaksflimmer Behandling med antiinflammatoriskt läkemedel och risk för förmaksflimmer Presentera översiktligt : Studieupplägg/frågeställningar, studiedesign, resultat, felkällor, konklusioner. Även era egna åsikter om vad som var bra och vad som skulle kunna gjorts bättre.

17
Epidemiologisk litteratur:
Ahlbom A, Alfredsson L, Alfvén T, Bennet A. Grunderna i epidemiologi. Lund: Studentlitteratur, Norell S. Epidemiologisk metodik: studieuppläggning, tillförlitlighet, effektivitet. Lund: Studentlitteratur, Hammar N, Persson G. Grunderna i biostatistik. Lund: Studentlitteratur, Rothman KJ. Epidemiology: an introduction. New York: Oxford University Press, Rothman KJ. Greenland S, Lash T. Modern epidemiology. Third ed. Health/Lippincott Williams & Wilkins 2008. Webplatser för svenska register: Swedeheart Nationellt register för hjärtstopp utanför sjukhus Riks-Stroke Swedvasc GUCH Register för vuxna med medfödda hjärtfel RiksSvikt (Nationellt Hjärtsviktregister) AuriculA – Atrial fibriallation and Anticoagulation registry Nationellt register för hjärtstopp på sjukhus Nationellt kvalitetsregister för kateterablation
 AuriculA – Atrial fibriallation and Anticoagulation registry Nationellt register för hjärtstopp på sjukhus Nationellt kvalitetsregister för kateterablation")
18
Svenska Register Webplatser för register: Swedeheart Nationellt register för hjärtstopp utanför sjukhus Riks-Stroke Swedvasc GUCH Register för vuxna med medfödda hjärtfel RiksSvikt (Nationellt Hjärtsviktregister) AuriculA – Atrial fibriallation and Anticoagulation registry Nationellt register för hjärtstopp på sjukhus Nationellt kvalitetsregister för kateterablation
 AuriculA – Atrial fibriallation and Anticoagulation registry Nationellt register för hjärtstopp på sjukhus Nationellt kvalitetsregister för kateterablation")
Liknande presentationer


 vid behandling av barnfetma enligt SLL's handlingsprogram (Abstract ECO 2009) Anna Bohlin.>")
















